
Hyperparameter Tuning and Regularization for Time Series Model Using Prophet in Python
What are the Prophet model hyperparameters that should be tuned automatically, manually, or better not be tuned?

Welcome to GrabNGoInfo! In this tutorial, we will talk about hyperparameter tuning and regularization for time series model using prophet in Python. You will learn:
- What are the hyperparameters for a prophet time series model?
- Among all the hyperparameters, what hyperparameters should be tuned, and what hyperparameters are better not to be tuned?
- Among all the hyperparameters that should be tuned, what hyperparameters should be tuned automatically vs. manually?
- How are hyperparameter tunings related to regularization?
- How does data transformation impact the model performance?
If you are not familiar with Prophet, please check out my previous tutorial Time Series Forecasting Of Bitcoin Prices Using Prophet, Multivariate Time Series Forecasting with Seasonality and Holiday Effect Using Prophet, and 3 Ways for Multiple Time Series Forecasting Using Prophet.
Resources for this post:
- Video tutorial for this post on YouTube
- Python code is at the end of the post. Click here for the Colab notebook
- More video tutorials on time series and hyperparameter tuning
- More blog posts on time series and hyperparameter tuning
Let’s get started!
Step 0: Overview of All the Hyperparameters for a Prophet Model
In step 0, we will provide an overview of all the hyperparameters for a prophet model. The hyperparameters are divided into three groups:
- The first group contains hyperparameters that are suitable for automatic tuning. We can specify a list of values and do a grid search for the best value combination. For more information about grid search, please refer to my previous tutorial Hyperparameter Tuning For XGBoost
- The second group contains hyperparameters that are suitable for manual tuning. A human needs to make a judgment on what hyperparameter value to use based on knowledge about data and business.
- The third group contains the hyperparameters that are better left untuned with the default values.
Group 1: Hyperparameters Suitable for Automatic Tuning
There are four hyperparameters that are suitable to be tuned automatically using grid search.
changepoint_prior_scaleis probably the most impactful parameter according to the Prophet documentation. It determines the scale of the change at the time series trend change point. It is an L1 LASSO regularization penalty term. To learn more about regularization, please refer to my previous tutorial LASSO (L1) Vs Ridge (L2) Vs Elastic Net Regularization For Classification Model
When the scale is too small, the trend does not change much at the change point, and the model tends to underfit. This is because the variance caused by the trend change is likely to be considered as noise with a small
changepoint_prior_scalevalue.
When the scale is too large, the trend changes a lot at the change point, and the model tends to overfit. The variance caused by noise is considered to be part of the trend.
The default value for
changepoint_prior_scaleis 0.05, and the recommended tuning range is 0.001 to 0.5. This hyperparameter is usually tuned on a log scale.
seasonality_prior_scalecontrols the magnitude of the seasonality fluctuation. It is an L2 Ridge regularization penalty term.
When the scale is too small, the magnitude of the seasonality shrinks to a very small value.
When the scale is too large, the magnitude of the seasonality allows very large fluctuations.
The default value for
seasonality_prior_scaleis 10, meaning that no regularization is applied. The recommended tuning range is 0.01 to 10, where a smaller value corresponds to a smaller magnitude of seasonality. This hyperparameter is usually tuned on a log scale.
holidays_prior_scaledetermines the scale of holiday effects, and is very similar to theseasonality_prior_scale. The default value is 10, meaning that no regularization is applied. The recommended tuning range is 0.01 to 10, where a smaller value corresponds to a smaller magnitude of holidays.seasonality_modehas two options, additive and multiplicative.
The additive model adds trend, seasonality, and other effects together when making predictions. It is appropriate for the time series models with relatively constant seasonal variation over time.
The multiplicative model multiplies trend, seasonality, and other effects together when making predictions. It is appropriate for the time series models with increasing or decreasing seasonal variation over time.
Group 2: Hyperparameters Suitable for Manual Tuning
Some hyperparameters need to be evaluated by a human-based on business knowledge or data observations for manual tuning.
changepoint_rangeis a value between 0 and 1 indicating the percentage of historical data that allow a trend change.
The default value is 0.8, meaning that the first 80% of the data allows trend changes, and the last 20% of the data does not allow a trend change. This is because there are not enough data at the end of the time series to identify a trend change with confidence.
The person who builds the model can increase or decrease the value manually by examining the time series shape and model performance for the last 20% of data.
growthhas two options, linear and logistic. The default value is linear, and it can be manually changed to logistic if there is a known growth saturating point.changepointsmanually specifying the dates of changepoints. The default value is None, which allows the model to automatically identify and place the change points on the trend. However, if there are any known events such as the rebranding of the business, the corresponding date can be manually added.yearly_seasonalityhas three options, auto, True, and False. The default is auto, which automatically turns the yearly seasonality on when there are at least two cycles of data.
We can manually set
yearly_seasonalityto be True to force the yearly seasonality if there are less than two years of data.
yearly_seasonalityis usually not set to False, because it's more effective to leave it on and turn down the seasonal effects by tuningseasonality_prior_scale[2].
weekly_seasonalityanddaily_seasonalitycan be handled in the same way as theyearly_seasonality.holidaystakes in a dataframe with specified holidays and special events. We can manually include or exclude holidays or events, or change the number of days impacted by the holiday to tune this hyperparameter. The magnitude of the holiday effects should be tuned byholidays_prior_scale.
Group 3: Hyperparameters Suitable for No Tuning
There are five hyperparameters that should not be tuned.
n_changepointsis the number of changepoints on the trend. The default value is 25. Rather than increasing or decreasing the number of changepoints, the prophet documentation[2] suggested focusing on increasing or decreasing the flexibility at those trend changes, which is done withchangepoint_prior_scale.interval_widthdetermines the uncertainty interval for the predictions. The default value is 0.8, meaning that the prediction upper boundyhat_upperand the prediction lower boundyhat_lowerare based on the 80% uncertainty interval.interval_widthdoes not impact the model prediction, so there is no need to tune this hyperparameter.uncertainty_samplesis the number of samples used for uncertainty interval calculation. The default value is 1000, and increasing the value decreases the variance of the uncertainty interval. This hyperparameter does not impact the model prediction, so there is no need to tune it.mcmc_samplesis an integer that determines if the model uses a full Bayesian inference or a Maximum a Posterior (MAP) for model training and prediction.
When it’s greater than 0, a full Bayesian inference with the specified number of MCMC samples will be used. Bayesian inference usually needs at least 1000 samples to get reasonable results.
When it equals to 0, a Maximum a Posterior (MAP) estimation will be used. The default value for
mcmc_samplesis 0, indicating that Maximum a Posterior (MAP) estimation is used by default. The prophet documentation suggests leaving this hyperparameter unchanged[2].
stan_backendneeds to be specified when bothpystanandcmdstanpybackends are set up. This hyperparameter does not impact model training and prediction, so there is no need to tune it.
Step 1: Install and Import Libraries
In the first step, we will install and import libraries.
yfinance is the python package for pulling stock data from Yahoo Finance. prophet is the package for the time series model. After installing yfinance and prophet, they are imported into the notebook.
We also import pandas and numpy for data processing, seaborn and matplotlib for visualization, and itertools, cross_validation, and performance_metrics for hyperparameter tuning.
# Install libraries
!pip install yfinance prophet# Data processing
import pandas as pd
import numpy as np# Get time series data
import yfinance as yf# Prophet model for time series forecast
from prophet import Prophet# Visualization
import seaborn as sns
import matplotlib.pyplot as plt# Hyperparameter tuning
import itertools
from prophet.diagnostics import cross_validation, performance_metricsStep 2: Pull Data
The second step pulls stock data from Yahoo Finance API. We will pull 2 years of daily data from the beginning of 2020 to the end of 2021.
start_date = '2020-01-02'because January 1st is a holiday, and there is no stock data on holidays and weekends.end_date = '2022-01-01'becauseyfinanceexcludes the end date, so we need to add one day to the last day of the data end date.
# Data start date
start_date = '2020-01-02'# Data end date
end_date = '2022-01-01' # yfinance excludes the end date, so we need to add one day to the last day of dataThe goal of the time series model is to predict the closing price of Google’s stock, so Google’s ticker GOOG is used for pulling the data.
Prophet requires at least two columns as inputs: a ds column and a y column.
- The
dscolumn has the time information. Currently we have the date as the index, so we reset the index and renamedatetods. - The y column has the time series values. In this example, because we are predicting Google’s closing price, the column name for the price is changed to
y.
# Pull close data from Yahoo Finance for the list of tickers
ticker_list = ['GOOG']
data = yf.download(ticker_list, start=start_date, end=end_date)[['Close']]# Change column names
data = data.reset_index()
data.columns = ['ds', 'y']# Take a look at the data
data.head()Using .info, we can see that the dataset has 505 records and there are no missing values.
# Data information
data.info()Output
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 505 entries, 0 to 504
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ds 505 non-null datetime64[ns]
1 y 505 non-null float64
dtypes: datetime64[ns](1), float64(1)
memory usage: 8.0 KBNext, let’s visualize the closing prices of the two tickers using seaborn, and add the legend to the plot using matplotlib. We can see that the price for Google increased a lot starting in late 2020, and almost doubled in late 2021.
# Visualize data using seaborn
sns.set(rc={'figure.figsize':(12,8)})
sns.lineplot(x=data['ds'], y=data['y'])
plt.legend(['Google'])
Step 3: Baseline Model Using Default Hyperparameters
In step 3, we will build a baseline model using the default prophet hyperparameters.
# Initiate the model
baseline_model = Prophet()# Fit the model on the training dataset
baseline_model.fit(data)Output
INFO:prophet:Disabling yearly seasonality. Run prophet with yearly_seasonality=True to override this.
INFO:prophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
<prophet.forecaster.Prophet at 0x7fd0536db410>Prophet automatically fits daily, weekly, and yearly seasonalities if the time series is more than two cycles long.
The model information shows that the yearly seasonality and the daily seasonality are disabled.
- The daily seasonality is disabled because we do not have sub-daily time series.
- The yearly seasonality is disabled although we have two years of data because there are no stock price data on holidays and weekends, so we have less than 365 data points for each year.
Next, let’s do cross-validation for the baseline model to get the model performance. Prophet has a cross_validation function to automate the comparison between the actual and the predicted values.
model=baseline_modelspecifies the model name.initial='200 days'means the initial model will be trained on the first 200 days of data.period='30 days'means 30 days will be added to the training dataset for each additional model.horizon = '30 days'means that the model forecasts the next 30 days. When onlyhorizonis given, Prophet defaultsinitialto be triple thehorizon, andperiodto be half of thehorizon.parallel="processes"enables parallel processing for cross-validation. When the parallel cross-validation can be done on a single machine, "processes" provide the highest performance. For larger problems,daskcan be used to do cross-validation on multiple machines.
# Cross validation
baseline_model_cv = cross_validation(model=baseline_model, initial='200 days', period='30 days', horizon = '30 days', parallel="processes")
baseline_model_cv.head()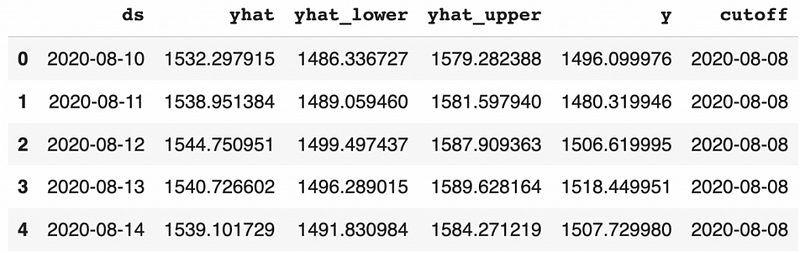
Based on the output from the cross-validation, we can get the model performance using the method performance_metrics.
- The model performance metrics are calculated using a rolling window. The average performance metrics values are calculated for each value of the horizon. Since we have the horizon value of 30 days, there will be 30 average values, one for each day.
rolling_windowdetermines the window size, which is the percentage of forecasted data points to include in the calculation.
rolling_window=0computes performance metrics separately for each horizon.
rolling_window=0.1is the default value, which computes performance metrics using about 10% of the predictions in each window.
rolling_window=1computes performance metrics using all the forecasted data. We are usingrolling_window=1in this tutorial. to get a single performance metric number.
rolling_window<0computes each data point without averaging (i.e.,MSEwill actually be a squared error with no mean)[3]
# Model performance metrics
baseline_model_p = performance_metrics(baseline_model_cv, rolling_window=1)
baseline_model_p.head()
Prophet provides six commonly used performance metrics:
- Mean Squared Error(MSE) sums up the squared difference between actual and prediction and is divided by the number of predictions.
- Root Mean Square Error(RMSE) takes the square root of MSE.
- Mean Absolute Error(MAE) sums up the absolute difference between actual and prediction and is divided by the number of predictions.
- Mean Absolute Percentage Error(MAPE) sums up the absolute percentage difference between actual and prediction and is divided by the number of predictions. MAPE is independent of the magnitude of data, so it can be used to compare different forecasts. But it’s undefined when the actual value is zero.
- Median Absolute Percentage Error(MDAPE) is similar to MAPE. The difference is that it calculates the median instead of taking the average of the absolute percentage difference.
- Symmetric Mean Absolute Percentage Error(SMAPE) is similar to MAPE. The difference is that when calculating absolute percentage error, the denominator is the actual value for MAPE and the average of the actual and predicted value for SMAPE.
We can see that the baseline model using default hyperparameters has 4.45% Mean Absolute Percentage Error (MAPE), meaning that the predictions are 4.45% off the actual values.
# Get the performance metric value
baseline_model_p['mape'].values[0]Output
0.04445730639004379Step 4: Models with Manual Hyperparameter Changes
In step 4, we will check the hyperparameters for manual tuning.
changepoint_rangewill be increased from 0.8 to 0.9 to see if there is a trend change near the end of the time series. This is because the shape of the time series seems to flatter starting around October of 2021 based on human observation.growthis kept at the default valuelinearbecause there is no saturating point for the stock price data.changepointsis kept at the default value is None, which allows the model to automatically identify and place the change points on the trend. This is because there are not any known big events that are likely to impact the Google stock prices in the time range used for the model.yearly_seasonalityis kept at the automated value of False because we do not have more than 2 cycles of yearly data for the model training.weekly_seasonalityis kept at the automated value of True because we have more than 2 cycles of weekly data.daily_seasonalityis kept at the automated value of False because we do not have sub-daily data.holidaystakes in a dataframe with specified holidays and special events. We can manually include two special events, COVID start and Super Bowl.
The manually changed hyperparameters will be evaluated one by one. If the change improves the model performance, we will keep the change, otherwise, we will switch back to the default values.
Step 4.1: Change Point Range
Firstly, let’s increase changepoint_range from 0.8 to 0.9 to see if there is a trend change near the end of the time series.
# Initiate the model
manual_model = Prophet(changepoint_range=0.9)# Fit the model on the training dataset
manual_model.fit(data)# Cross validation
manual_model_cv = cross_validation(manual_model, initial='200 days', period='30 days', horizon = '30 days', parallel="processes")# Model performance metrics
manual_model_p = performance_metrics(manual_model_cv, rolling_window=1)
manual_model_p['mape'].values[0]Output
0.05132206898098496The Mean Absolute Percentage Error (MAPE) from cross-validation is 5.13%, which is higher than the baseline model of 4.45%, indicating that we should not increase the value of changepoint_range.
Step 4.2: Holidays
Next, let’s create two special events: COVID start and Super Bowl.
- For the COVID start event, we set the date to be March 15th of 2020, then extend the event to 15 days before and 15 days after using
lower_windowandupper_windowseparately. - For the Super Bowl event, we set the date in 2020 and 2021 separately, and extend the event to 7 days before and 1 day after.
Then the two events are concatenated together into one dataframe called events.
# COVID time window
COVID = pd.DataFrame({
'holiday': 'COVID',
'ds': pd.to_datetime(['2020-03-15']),
'lower_window': -15,
'upper_window': 15,
})# Super Bowl time window
superbowl = pd.DataFrame({
'holiday': 'superbowl',
'ds': pd.to_datetime(['2020-02-02', '2021-02-07']),
'lower_window': -7,
'upper_window': 1,
})# Combine all events
events = pd.concat((COVID, superbowl))# Take a look at the events data
events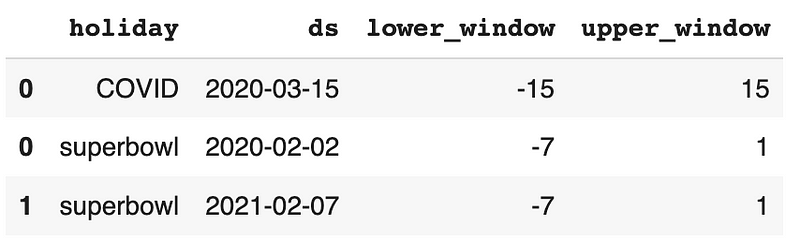
After adding the special events, the Mean Absolute Percentage Error (MAPE) from cross-validation is 4.64%, which is higher than the baseline model of 4.45%, indicating that the special events are not predictive of the stock prices. Therefore, we should not include special events in the model.
# Add special events
manual_model = Prophet(holidays=events)# Fit the model on the training dataset
manual_model.fit(data)# Cross validation
manual_model_cv = cross_validation(manual_model, initial='200 days', period='30 days', horizon = '30 days', parallel="processes")# Model performance metrics
manual_model_p = performance_metrics(manual_model_cv, rolling_window=1)
manual_model_p['mape'].values[0]Output
0.046355656191352575Step 5: Automatic Hyperparameter Tuning
There are four hyperparameters that are suitable to be tuned automatically using grid search: changepoint_prior_scale, seasonality_prior_scale, holidays_prior_scale, and seasonality_mode.
holidays_prior_scale is not applicable because there is no holiday or special events included in the model. We will use grid search to find the best values for the other three hyperparameters.
- Firstly, four values for
changepoint_prior_scale, five values forseasonality_prior_scale, and two values forseasonality_modeare used to set up the parameter grid. - Then, all combinations of parameters are created and saved in a variable called
all_params. mapesis an empty list created for storing the Mean Absolute Percentage Error (MAPE) for each combination of parameters.- After that, we loop through each parameter combination to build a time series model, and save the cross-validation performance results in the list called
mapes. - Finally, we get the best parameters based on the minimum value of Mean Absolute Percentage Error (MAPE), and build a new model using the best parameters.
# Set up parameter grid
param_grid = {
'changepoint_prior_scale': [0.001, 0.05, 0.08, 0.5],
'seasonality_prior_scale': [0.01, 1, 5, 10, 12],
'seasonality_mode': ['additive', 'multiplicative']
}# Generate all combinations of parameters
all_params = [dict(zip(param_grid.keys(), v)) for v in itertools.product(*param_grid.values())]# Create a list to store MAPE values for each combination
mapes = [] # Use cross validation to evaluate all parameters
for params in all_params:
# Fit a model using one parameter combination
m = Prophet(**params).fit(data)
# Cross-validation
df_cv = cross_validation(m, initial='200 days', period='30 days', horizon = '30 days', parallel="processes")
# Model performance
df_p = performance_metrics(df_cv, rolling_window=1)
# Save model performance metrics
mapes.append(df_p['mape'].values[0])
# Tuning results
tuning_results = pd.DataFrame(all_params)
tuning_results['mape'] = mapes# Find the best parameters
best_params = all_params[np.argmin(mapes)]
print(best_params)Output
{'changepoint_prior_scale': 0.05, 'seasonality_prior_scale': 1.0, 'seasonality_mode': 'additive'}We can see that the best parameters are changepoint_prior_scale equals 0.05, seasonality_prior_scale equals 1, and seasonality_mode equals additive.
# Fit the model using the best parameters
auto_model = Prophet(changepoint_prior_scale=best_params['changepoint_prior_scale'],
seasonality_prior_scale=best_params['seasonality_prior_scale'],
seasonality_mode=best_params['seasonality_mode'])# Fit the model on the training dataset
auto_model.fit(data)# Cross validation
auto_model_cv = cross_validation(auto_model, initial='200 days', period='30 days', horizon = '30 days', parallel="processes")# Model performance metrics
auto_model_p = performance_metrics(auto_model_cv, rolling_window=1)
auto_model_p['mape'].values[0]Output
0.044162208439371395The Mean Absolute Percentage Error (MAPE) from cross-validation is 4.42% for the model with the best parameters, which is better than the baseline model of 4.45%.
Step 6: Automatic Hyperparameter Tuning using Log Data
The prophet model documentation[2] mentioned some hyperparameters are best tuned in log scale. In step 6, we will transform the data to the log form, and then do the automatic hyperparameter tuning.
- Firstly, a copy of the modeling data is created with the name
data_log - Then, the log scale data is created by taking the natural log of the stock prices.
- After that, the original stock prices are deleted and the log scale stock prices are renamed to
y. - Lastly, the new log-scale data is used for grid search, and the best parameters are used for the final model.
# Create a copy of the data
data_log = data.copy()# Create the log scale data by taking the natual log of the stock prices.
data_log['y_log'] = np.log(data['y'])# Delete the stock price and rename the log scale stock price to y
data_log = data_log.drop('y', axis=1).rename(columns={'y_log': 'y'})# Take a look at the data
data_log.head()
# Parameter grid
param_grid = {
'changepoint_prior_scale': [0.001, 0.05, 0.08, 0.5],
'seasonality_prior_scale': [0.01, 1.0, 5, 10, 12],
'seasonality_mode': ['additive', 'multiplicative']
}# Generate all combinations of parameters
all_params = [dict(zip(param_grid.keys(), v)) for v in itertools.product(*param_grid.values())]
mapes = [] # Store the MAPEs for each params here# Use cross validation to evaluate all parameters
for params in all_params:
# Fit a model using one parameter combination
m = Prophet(**params).fit(data_log)
# Cross-validation
df_cv = cross_validation(m, initial='200 days', period='30 days', horizon = '30 days', parallel="processes")
# Model performance
df_p = performance_metrics(df_cv, rolling_window=1)
# Save model performance metrics
mapes.append(df_p['mape'].values[0])# Tuning results
best_params = all_params[np.argmin(mapes)]# Best parameters
print(best_params)# Train model using best parameters
auto_model_log = Prophet(changepoint_prior_scale=best_params['changepoint_prior_scale'],
seasonality_prior_scale=best_params['seasonality_prior_scale'],
seasonality_mode=best_params['seasonality_mode'])# Fit the model on the training dataset
auto_model_log.fit(data_log)# Cross validation
auto_model_log_cv = cross_validation(auto_model_log, initial='200 days', period='30 days', horizon = '30 days', parallel="processes")# Model performance metrics
auto_model_log_p = performance_metrics(auto_model_log_cv, rolling_window=1)
auto_model_log_p['mape'].values[0]Output
{'changepoint_prior_scale': 0.08, 'seasonality_prior_scale': 0.01, 'seasonality_mode': 'additive'}0.006668734217672668The Mean Absolute Percentage Error (MAPE) from cross-validation is 0.67% for the log-scale model with the best parameters, which is much better than the baseline model of 4.45%.
Summary
In this tutorial, we talked about hyperparameter tuning and regularization for time series model using prophet in Python. You learned:
- What are the hyperparameters for a prophet time series model?
- Among all the hyperparameters, what hyperparameters should be tuned, and what hyperparameters are better not to be tuned?
- Among all the hyperparameters that should be tuned, what hyperparameters should be tuned automatically vs. manually?
- How are hyperparameter tunings related to regularization?
- How does data transformation impact the model performance?
More tutorials are available on GrabNGoInfo YouTube Channel and GrabNGoInfo.com.
Recommended Tutorials
- GrabNGoInfo Machine Learning Tutorials Inventory
- Time Series Anomaly Detection Using Prophet in Python
- 3 Ways for Multiple Time Series Forecasting Using Prophet in Python
- Time Series Forecasting Of Bitcoin Prices Using Prophet
- Multivariate Time Series Forecasting with Seasonality and Holiday Effect Using Prophet in Python
- Four Oversampling And Under-Sampling Methods For Imbalanced Classification Using Python
- Recommendation System: User-Based Collaborative Filtering
- Sentiment Analysis Without Modeling: TextBlob vs. VADER vs. Flair
References
[1] PSU Stat510 Applied Time Series Analysis Chapter 5.1 Decomposition Models





