
How to work with BIG Geospatial Data

I’ve been working as a freelance webGIS developer for over three years now and before that, I did a bachelors degree in GeoInformatics so I have had to work with geospatial data a lot.
It is not uncommon for geospatial data to get large, especially when you are dealing with Raster data. A few gigabytes of data is very common and most of the desktop GIS software (like ArcGIS and QGIS etc.) are usually able to handle that much data.
But what if the data gets really huge? Like in Terabytes or Petabytes?
For example when you have to work with mosaics of high resolution multispectral or hyperspectral images on a national or continental scale. This is when the size of the dataset can balloon to terabytes or even petabytes and the real trouble starts because conventional GIS software can’t easily handle that large amount of data.
This is when you’ve to start looking for alternatives to Desktop GIS software and since there isn’t much help online about this subject yet so I thought I should share my experiences to help those looking forward to working with big geospatial datasets. Following are some of the tools and technologies that I’d recommend in such cases:
1. Google BigQuery GIS
Google BigQuery is a tool from Google that is used for data warehousing and performing analytics on large datasets. Fortunately, it also comes with a spatial extension called Bigquery GIS. Here is a short introduction:
It is important to note that BigQuery comes with its own limitations, for example, it only works with WGS 84 Projection (EPSG: 4326) and doesn’t have as many capabilities as other opensource GIS databases (like PostGIS).
But when it comes to large datasets, nothing can beat BigQuery GIS. I once tried to find erroneous polygons from a huge dataset (it had more than 700 million records) in PostGIS and it almost took a day to find them out while BigQuery GIS was able to find them out in less than 3 minutes.
If you are interested, you can read a bit more on BigQuery GIS and its available functions here.
2. Opensource Libraries and Binaries
Another way of handling such datasets is to have a process and have it run programmatically through opensource libraries and binaries and you can use them inside a shell script to your advantage.

My team once handled terabytes of data in a Linux environment using python GDAL bindings (we wrote python scripts) and also used some ogr2ogr commands and encapsulated all of them in bash scripts that would perform all the steps one by one. For a very large dataset, we divided the continental scale raster into hundreds of small squares using a grid, processed all of them individually and at the end merged the final results. This technique can even take a couple of days to complete but it is able to process very large datasets.
These scripts can also be sped up using different tools and technologies. Once we had a python script to process large datasets and a team member scaled it up using Google DataFlow and the process that would otherwise take days could complete in minutes enabling us to process large amounts of data.
3. SpatialHadoop
Apache Hadoop is a collection of open-source software utilities that facilitate using a network of many computers to solve problems involving massive amounts of data and computation. It also comes with a geospatial extension known as SpatialHadoop. I haven’t used it myself so far but it would be unfair to talk about processing Geospatial Big Data without SpatialHadoop.
SpatialHadoop has native support for Spatial Data and is aware of the location. It uses traditional Geospatial indexing like R-tree, Grid, etc. on top of Hadoop Codebase thus making it location-aware.
4. Google Earth Engine
Google Earth Engine is undoubtedly one of the best and the easiest tools out there for processing Geospatial data. It has Petabytes of opensource images from Remote Sensing satellites and keeps on ingesting their feed in real-time and you can just use them without downloading. It also processes them to create other datasets. Here is a brief introduction of the Earth Engine:
Earth Engine comes with a myriad of datasets already available and you can further do band maths and/or use other functions to manipulate these datasets according to your needs. It also allows you to upload and manipulate your own datasets within the simple platform. Here is how it looks like:
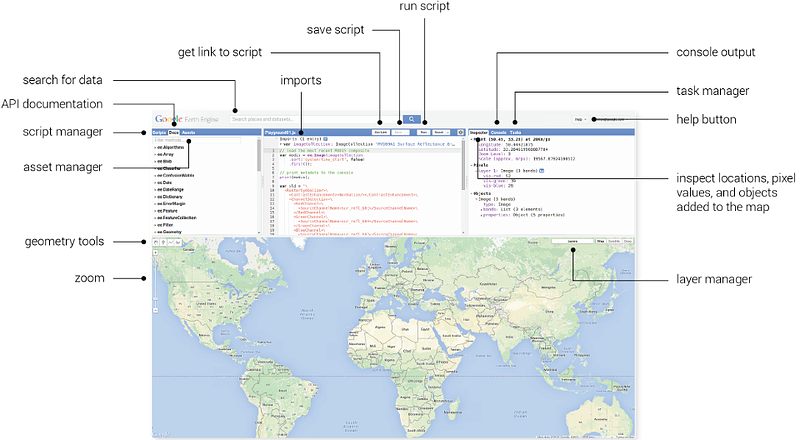
The best thing about Earth Engine is that it is completely free for research and non-commercial purposes. If you know Python or Javascript, you can easily get started with it. You can also prepare real-time layers and add them to Google Maps to create exciting web maps using Google Earth Engine.
I have used Earth Engine to monitor floods, monitor vegetation and changes in it, and to monitor rainfalls and snow. And for all this, I never had to download tons of satellite images on my computer. In the future, I would be writing more blogs to show these practical uses of Earth Engine and analyze different phenomenon like floods, deforestation, and forest fires, etc.
Edit: following are the tools and technologies that people recommended in response to this story, I haven’t used them but I thought I should add them too because they seem to be doing a good job as well.
5. AWS Athena
Amazon Athena is an interactive query service that makes it easy to analyze data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL.
This also supports Geospatial data types and provides Geospatial lookups and functions.
6. PostGIS
Now you must be thinking that why PostGIS? I even compared it with Bigquery GIS where it didn’t perform as well. I have personally used it for smaller datasets and didn’t have a great experience handling large datasets using it. But it turns out that even PostGIS can be used if the dataset size is around a few Terabytes.
But you have to make it work in that case. You need to heavily rely on ANALYZE and EXPLAIN and you have to religiously monitor the logs to trim the fat of your queries. You need to optimize and index the tables and aggressive vacuuming is essential.

7. NoSQL and Graph databases
NoSQL databases like MongoDB and ElasticSearch are good at handling large datasets and have decent Geospatial support. We also have Graph databases like Neo4j that are good at handling large datasets and support Geospatial queries.
Side Note
To see Geospatial big data in action have a look at Glidefinder. We used Google BigQuery GIS and Opensource libraries and binaries to process large amounts of data to build this site that can monitor wildfires in real-time. If you are interested to read more about how it was made, have a look at this blog by the CTO
There’s no “one tool to rule them all”
Real-world problems are complex and they vary from each other and so does the nature of datasets that are required to handle them. You cannot point to one tool or technology and say that it can help with all the datasets. Which option you should choose always depends on what you want to achieve and in many cases you need to use a combination of different tools, technologies, and techniques.
I am Ramiz Sami. I climb mountains, lift heavy weights and build WebGIS solutions. Feel free to get connected with me on Linkedin.




