
How to Use UMAP For Much Faster And Effective Outlier Detection
Let’s catch those high-dimensional outliers

Introduction
We’ve all used those simple techniques — plot a scatterplot or a KDE, and the data points farthest from the group are outliers. Now, tell me — how would you use these methods if you were to find outliers in, say, 100-dimensional datasets? Right off the bat, visual outlier detection methods are out of the question.
So, fancy machine learning algorithms like Local Outlier Factor or Isolation Forest come to mind, which are effective against outliers in high-dimensional data.
But there are many caveats to using ML methods to detect outliers. A technique called Elliptical Envelope uses a covariance estimation but assumes the data is normally distributed (which is rarely the case). Local Outlier Factor is much faster than Isolation Forest at the risk of lower accuracy.
So, how can we excel at both speed and accuracy at outlier detection when dealing with massive, million-row datasets that are so common? That’s where UMAP comes in.
Get the best and latest ML and AI papers chosen and summarized by a powerful AI — Alpha Signal:
What is UMAP?
UMAP (Uniform Manifold Approximation & Projection) is a dimensionality reduction algorithm introduced in 2018. It combines the best features of PCA and tSNE — it can scale to large datasets quickly and compete with PCA in terms of speed, and project data to low dimensional space much more effectively and beautifully than tSNE:

The UMAP python package has a familiar Scikit-learn API. Below is an example code projecting the Kaggle TPS September Competition data to 2D:
UMAP is designed so that whatever dimension you project the data to, it reserves as much variance and topological structure as possible. But what does it have to do with outlier detection?
Well, since we know that UMAP preserves all the peculiarities and attributes of the dataset even in lower dimensions, we can use it to first project the data to a lower space and then use any other outlier detection algorithm much faster! In the coming sections, we will look at an example using the above TPS September data.
If you want to learn more about UMAP and its awesome features, I have covered it in-depth in a previous article:
Setting a baseline with pure Isolation Forest
Before we move on, let’s establish a baseline performance. First, we will fit a CatBoostClassifier for a benchmark:
We have got a ROC AUC score of 0.784. Now, let’s fit an Isolation Forest estimator to the data after imputing missing data:
Even though powerful, Isolation Forest has only a few parameters to tune. The most important one is n_estimators, which controls the number of trees to be built. We are setting it to 3000, considering the dataset size.
After waiting for about 50 minutes, we discover that Isolation Forest found 2270 outliers in the data. Let’s drop those values from the training data and fit a classifier again:
We got a slight drop in the performance, but that’s not a sign for us to stop our efforts of finding outliers. At this point, we don’t really know whether these ~2200 data points are all the outliers in the data. We don’t know whether we built Isolation Forest with enough trees, as well. The worst part, we can’t try the experiment again because it is too time-consuming.
That’s why we will start playing smart.
Outlier detection with UMAP combined with Isolation Forest
After we found the 2270 outliers, we didn’t double-check whether they were actual outliers. Traditional visualization methods won’t work, so let’s try projecting the data to 2D first and plot a scatterplot:

We can immediately see singleton points farthest from the two distinct clusters (they are displayed in small sizes because we didn’t tweak UMAP parameters). We can confidently classify these points as outliers and trust the results we obtained from Isolation Forest.
Now, we will combine UMAP with IsolationForest. To maximize retention as much as possible, we will project the data to 5 dimensions. Then, we will fit Isolation Forest with only 500 trees since we have much fewer features this time:
The whole transformation and outlier detection took three times less amount of time. But here is the surprise — this time, Isolation Forest found a whopping ~163k outliers out of 950k. Are we making a mistake? Let’s check by fitting a classifier once again after dropping these outliers:
It seems that 3000 trees were not enough to find all the outliers in the data. We see that even after dropping 160k observations, we are still getting the same results.
Summary
Yes, we didn’t get a significant score improvement after removing outliers from the dataset. In fact, you could have said all our efforts were complete waste in terms of practicality.
However, the purpose of this article was to show you that outlier detection will become much less time/resource-consuming when combining powerful dimensionality reduction techniques like UMAP. As you have seen, we achieved much better performance with much less resources in Isolation Forests.
Outliers are a real and serious problem in the ML world. The techniques you have learned today will surely benefit you against scenarios like below, especially when your data is massive and high-dimensional:
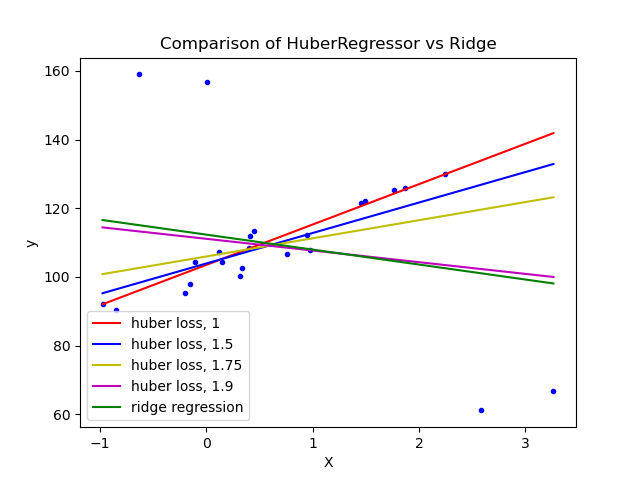
You can learn more about the techniques in the article from the UMAP documentation, which includes an awesome example using the digits data.
Thank you for reading!





