
Natural Language Processing
How To Use Rasa To Build A Bot That Understands Bahasa Melayu
A Tutorial On Extending The LanguageModelFeaturizer Component To Use Other Pretrained Models
Introduction
In this article, I will explain how to extend Rasa’s LanguageModelFeaturizer component to use other models on HuggingFace’s models repository.
I assume the reader is familiar with building chatbots using Rasa. If that is not the case, then watch these series of videos on YouTube to quickly get up to speed.
The code to reproduce the results described in this article can be found here.
Problem Statement
Suppose you are tasked with building a chatbot that will interact with users in the Malay language.
Since you are just starting out, you don’t have a lot of real-world conversations to train the NLU model on. However, there are a lot of conversations going on out there (e.g. social media) in the Malay language. How can we use these conversations to improve the NLU model?
Solution
One solution is to train a language model on a Malay language corpus that approximates the utterances you expect your users will utter to your bot. Then, you can treat the language model as a featurizer and feed those features into the DIET Classifier for further “fine-tuning”.
If the language model was built using Hugging Face’s transformers library, then it can be integrated into the NLU model’s prediction pipeline using the LanguageModelFeaturizer component.
The rest of this article assumes that we are interested in using the Melayu BERT model as a featurizer.
To Extend Or Reuse The LanguageModelFeaturizer Component?
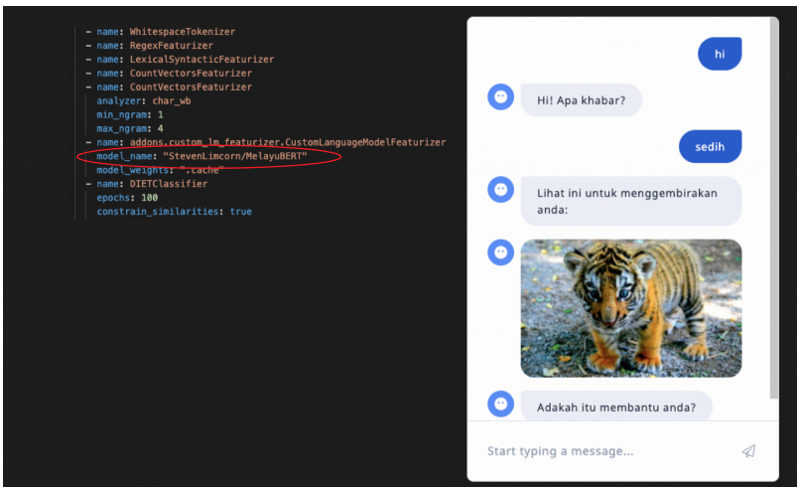
Since Melayu BERT is based on the BERT model, a reasonable way to use the LanguageModelFeaturizer component is to configure it this way:

Although the training runs successfully, the logs show:

This is because the model_name: "bert" parameter corresponds to the TFBertModel architecture while the Melayu BERT model was implemented using the TFBertForMaskedLM architecture.
A more prudent approach is to subclass LanguageModelFeaturizer to define how to extract features from models based on the TFBertForMaskedLM architecture. This helps avoid accidentally introducing bugs due to model missing crucial layers.
Implementation Details
A TFBertForMaskedLM model shares a lot of similarities with a TFBertModel. This means that we can reuse most of the existing methods in the LanguageModelFeaturizer class.
These are the only methods we need to override:
_load_model_metadata_load_model_instance_add_lm_specifc_special_tokens_lm_specific_token_cleanup_compute_batch_sequence_features_post_process_sequence_embeddings
We will create a class named CustomLanguageModelFeaturizer to override the methods above. This class will be defined in a module named custom_lm_featurizer.py in a folder named addons.
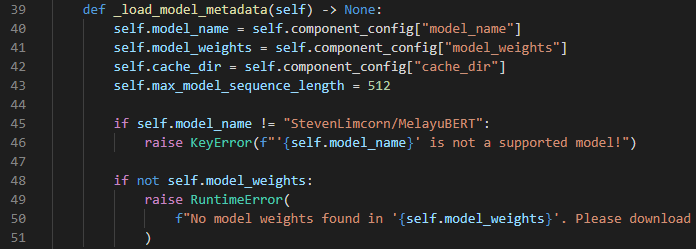
Step 1: How to load a model’s metadata
_load_model_metadata controls how the configuration in LanguageModelFeaturizer gets processed.
Suppose we want the component to fail if model_name isn’t StevenLimcorn/MelayuBERT and if the model’s weights have not been downloaded. This is how this method can be implemented:
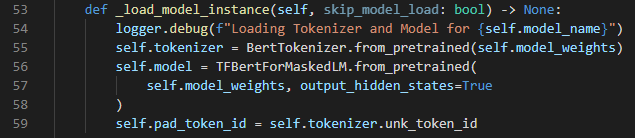
Step 2: How to load a model
_load_model_instance defines the components tokenizer, model, and padding token. This is straightforward to implement:
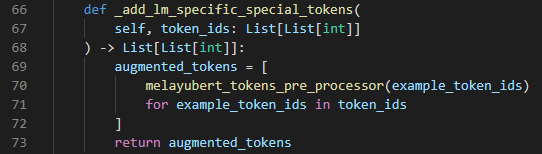
Step 3: Adding language model specific tokens
We know that BERT models require adding the [CLS] and [SEP] tokens as part of their input. This part is handled by the _add_lm_specific_special_tokens method:
Step 4: Cleaning up tokens
We also know that BERT’s tokenize sometimes breaks a single word into multiple words. For example, the word “strawberries” will be tokenized into “straw” and “##berries” in a bert-base-uncased model.
The _lm_specific_token_cleanup the method will remove the “##” so that we will have something more readable in case we want to stitch the tokens back together for further processing downstream:

Step 5: How to extract features
We want the DIET Classifier to use the last hidden state of Melayu BERT as a feature to perform intent classification and/or entity extraction. We define this behavior in the _compute_batch_sequence_features method:
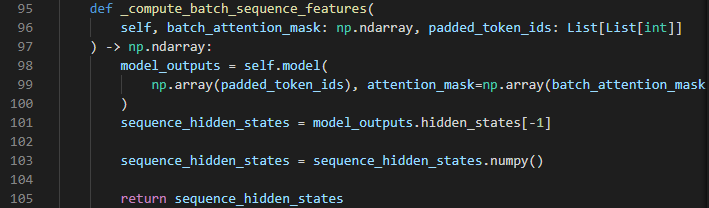
Step 6: How to use the features
Once we’ve extracted the features from Melayu BERT, we need to tell DIET Classifier how to use it for intent classification and entity extraction. This is done in the post_process_sequence_embeddings :
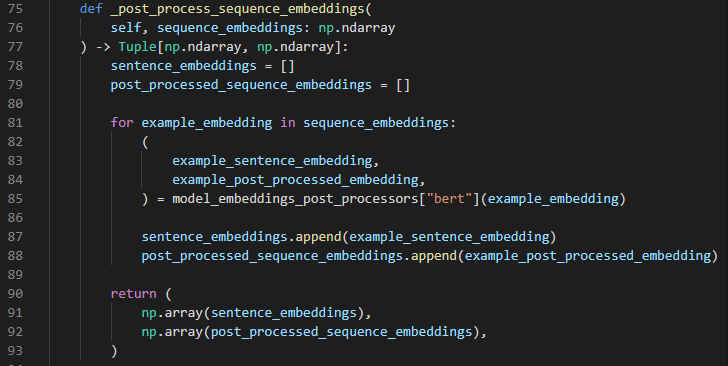
Given a last hidden state from Melayu BERT, the feature to use for intent classification and entity extraction is the vector representation of the [CLS] token. The features to use for entity extraction are everything else except the [CLS] and [SEP] token. This logic is identical to the predefined post processor for the TFBertModel which is why we’ve decided to reuse it (see line 85).
Usage
The following snippet shows how to include the CustomLanguageModelFeaturizer the component as part of the NLU pipeline:

CustomLanguageModelFeaturizer componentFigure 9 assumes that the model artifacts have been downloaded into a folder named .cache.
Conclusion
This article has described a way to use customize the LanguageModelFeaturizer component to use a TFBertForMaskedLM model as a featurizer in Rasa. A similar approach could be adapted to work with any model created using the transformers library.
Let me know in the comments if you have any questions.