
How to transcribe and translate with OpenAI’s Whisper
Use Whisper for free with this Google Colab notebook

One of my favorite writers is Enrique Vila-Matas, a Spanish writer obsessed with books and the reading life.
I’ve read everything he wrote that I can find in English, but too many of his interviews are untranslated, trapped in scholarly Spanish prose too intricate for my feeble Spanish skills to decipher.
Whisper + Google Colab
When Open At released Whisper this week, I thought I could use the neural network’s tools to transcribe a Spanish audio interview with Vila-Matas and translate it into English.
I began by looking for Google Colab notebooks I could use to tap into this open-source general-purpose speech recognition model.
I couldn’t find one, so I wrote my own Colab notebook that anybody can use: “Transcribe and Translate with OpenAI’s Whisper.”
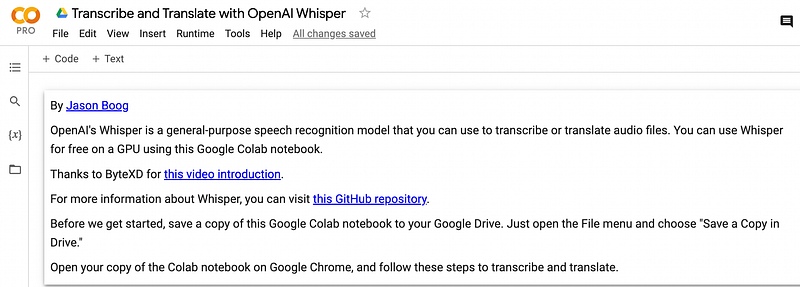
My coding skills are primitive at best, but I managed to bend all my knowledge into a few paragraphs.
After a bit of work, I had built an AI translation machine. With my Google Colab account, I could use this general-purpose speech recognition model to both transcribe or translate audio files.
I tested my Colab notebook with audio from an Enrique Vila-Matas mini-doc I’ve always wanted to watch, “Cafe Con Shandy.”
The whole process was magical and cumbersome, but now I have an enormous .TXT file containing a pretty solid translation of a once indecipherable bit of video.
AI and “the abundance of materials”
That chunk of newly translated text took some extra reading to sort out, but I finally understood what they were talking about in the video.
I even found a sentence in there that’s applicable to our world where GPT-3 can generate endless text and Whisper can translate it.
“Of course, and it is a fear that I think the writer has, it is the fear of being finished,” Vila-Matas notes in the video that I translated with the help of Whisper.
“This idea of finishing sometimes has to do with your writing, with a different question or that would seem to oppose the conclusion — which is precisely the excess, the abundance of materials.”
We now live in a world of AI-generated abundance, and writers will need to find a place in this sea of content.
For me today, that means something new and interesting to read. For me tomorrow, that means an existential struggle to find readers in a sea of AI-generated stories and images.
Vila-Matas is right. The writer will never be finished. But it is a little scary and thrilling to see our excessive future, overwhelmed by our “abundance of materials.”




