
How to Train the LILT Model on Invoices and Run Inference
A Step-by-Step Tutorial

In the realm of document understanding, deep learning models have played a significant role. These models are able to accurately interpret the content and structure of documents, making them valuable tools for tasks such as invoice processing, resume parsing, and contract analysis. Another important benefit of deep learning models for document understanding is their ability to learn and adapt over time. As new types of documents are encountered, these models can continue to learn and improve their performance, making them highly scalable and efficient for tasks such as document classification and information extraction.
One of these models is the LILT model (Language-Independent Layout Transformer), a deep learning model developed for the task of document layout analysis. Unlike it’s layoutLM predecessor, LILT is originally designed to be language-independent, meaning it can analyze documents in any language while achieving superior performance compared to other existing models in many downstream tasks application. Furthermore, the model has the MIT license, which means it can be used commercially unlike the latest layoutLM v3 and layoutXLM. Therefore, it is worthwhile to create a tutorial on how to fine-tune this model as it has the potential to be widely used for a wide range of document understanding tasks.
In this tutorial, we will discuss this novel model architecture and show how to fine-tune it on invoice extraction. We will then use it to run inference on a new set of invoices.
LILT Model Architecture:
One of the key advantages of using the LILT model is its ability to handle multi-language document understanding with state-of-the-art performance. The authors achieved this by separating the text and layout embedding into their corresponding transformer architecture and using a bi-directional attention complementation mechanism (BiACM) to enable cross-modality interaction between the two types of data. The encoded text and layout features are then concatenated and additional heads are added, allowing the model to be used for either self-supervised pre-training or downstream fine-tuning. This approach is different from the layoutXLM model, which involves collecting and pre-processing a large dataset of multilingual documents.
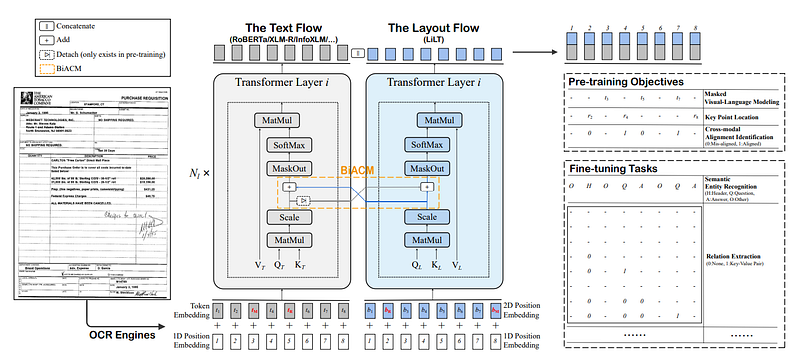
The key novelty in this model is the use of the BiACM to capture the cross-interaction between the text and layout features during the encoding process. Simply concatenating the text and layout model output results in worse performance, suggesting that cross-interaction during the encoding pipeline is key to the success of this model. For more in-depth details, read the original article.
Model Fine-tuning:
Similar to my previous articles on how to fine-tune the layoutLM model, we will use the same dataset to fine-tune the LILT model. The data was obtained by manually labeling 220 invoices using UBIAI text annotation tool. More details about the labeling process can be found in this link. For an in-depth video tutorial, checkout the link below:
To train the model, we first pre-pre-process the data output from UBIAI to get it ready for model training. These steps are the same as in the previous notebook training the layoutLM model, here is the notebook:
We download the LILT model from Huggingface:
from transformers import LiltForTokenClassification
# huggingface hub model id
model_id = "SCUT-DLVCLab/lilt-roberta-en-base"
# load model with correct number of labels and mapping
model = LiltForTokenClassification.from_pretrained(
model_id, num_labels=len(label_list), label2id=label2id, id2label=id2label
)For this model training, we use the following hyperparameters:
NUM_TRAIN_EPOCHS = 120
PER_DEVICE_TRAIN_BATCH_SIZE = 6
PER_DEVICE_EVAL_BATCH_SIZE = 6
LEARNING_RATE = 4e-5To train the model, simply run trainer.train() command:
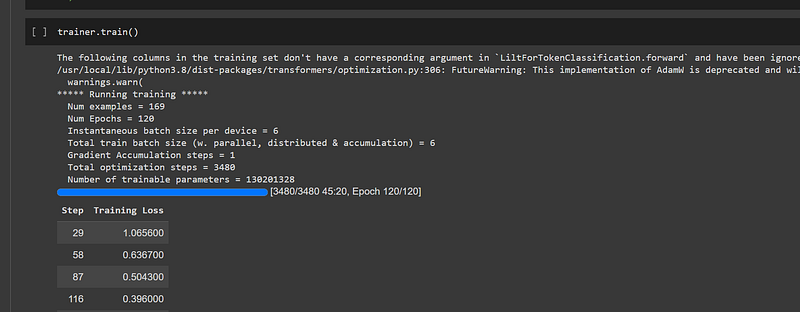
On GPU, training takes approximately 1h. After training, we evaluate the model by running trainer.evaluate():
{
'eval_precision': 0.6335952848722987,
'eval_recall': 0.7413793103448276,
'eval_f1': 0.6832627118644069,
}We get a precision, recall and F-1 score of 0.63, 0.74 and 0.68 respectively. The LILT model evaluation F-1 score of 0.68 indicates that the model is performing well in terms of its ability to accurately classify and predict outcomes with a moderate to good accuracy. It is worth noting, however, that there is always room for improvement, and it is beneficial to continue labeling more data in order to further increase its performance. Overall, the LILT model evaluation F-1 score of 0.68 is a positive result and suggests that the model is performing well in its intended task.
In order to assess the model performance on unseen data, we run inference on a new invoice.
We make sure to save the model so we can use it for inference later on using this command:
torch.save(model,'/content/drive/MyDrive/LILT_Model/lilt.pth')Model Inference:
To test the model on a new invoice, we run the inference script below:
Below is the result:
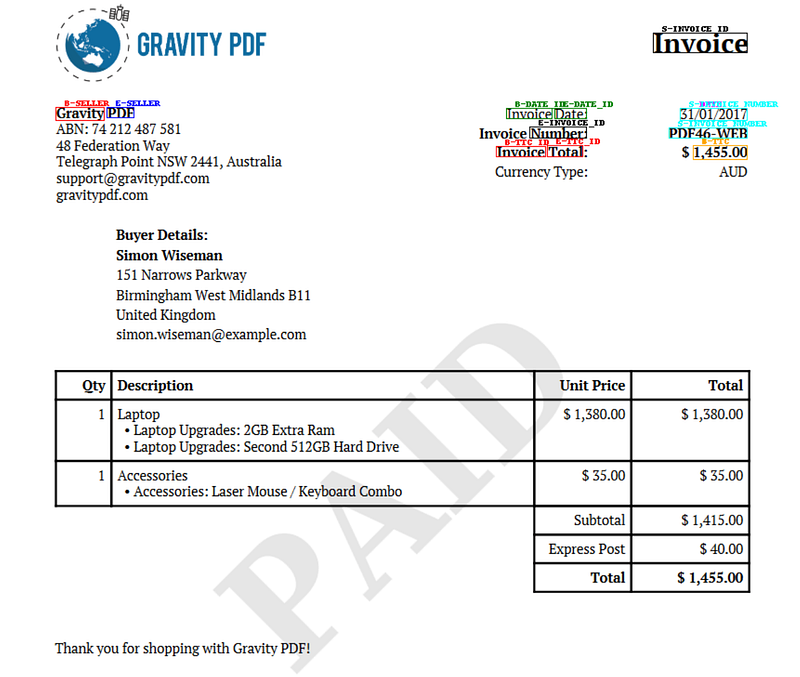
The LILT model correctly identified a wide range of entities, including seller names, invoice numbers, and total amounts. Let’s try out a couple more invoices:


As we can see, the LILT model was able to handle a variety of different formats with different context with a relatively good accuracy although it made few mistakes. Overall, the LILT model performed well and its predictions were similar to those produced by layoutlm v3 highlighting its effectiveness for document understanding tasks.
Conclusion
In conclusion, the LILT model has proven to be effective for document understanding tasks. Unlike the layoutLM v3 model, the LILT model is MIT licensed which allows for widespread commercial adoption and use by researchers and developers, making it a desirable choice for many projects. As a next step, we can improve the model performance by labeling and improving the training dataset.
If you want to efficiently and easily create your own training dataset, checkout UBIAI’s OCR annotation feature for free.
Follow us on Twitter @UBIAI5 or subscribe here!





