
Natural Language Processing
How to Train a Seq2Seq Text Summarization Model With Sample Code (Ft. Huggingface/PyTorch)
Part 2 of the introductory series about training a Text Summarization model (or any Seq2seq/Encoder-Decoder Architecture) with sample codes using HuggingFace.

This piece aims to give you a deeper understanding of the sequence-to-sequence (seq2seq) networks and how it is possible to train them for automatic text summarization. I will use the Transformer architecture while not going through its implementation details to keep the article focused on the training part. (There are numerous resources already available) We will leverage the Huggingface library, which hosts major state-of-the-art NLP models.
⚠️ I recommend reading the “Introduction to Tokenization” story and Part 1 “Introduction to Text Summarization” of this series (especially if you are new to NLP, the encoder-decoder architecture, or text summarization), where I wrote about the basics of encoder-decoder architecture.
What is training?
It means adjusting the model’s weights to make accurate predictions by showing several examples. There are different algorithms for training neural networks depending on the task. We will do Supervised Learning, which means training the model by presenting both source (article) and target (summary) samples to learn from.
The process starts by feeding the input (article) to the model and generating a summary. Then we can compare the generated summary with the target summary using a loss function (CrossEntropy here) to calculate how close they are and how much we need to change the weights to generate a better summary using an optimizer (Adam with Weight Decay). This is an iterative process that will repeat depending on the number of epochs.
One epoch means doing the mentioned process for each sample in the dataset once. Consequently, 10 epochs mean the model will see each sample 10 times during training. Also, there is the concept of batching which means passing the data in batches with sizes greater than 1 to the model and averaging their losses instead of feeding samples one. It will speed up the training process.
How Does it Work?
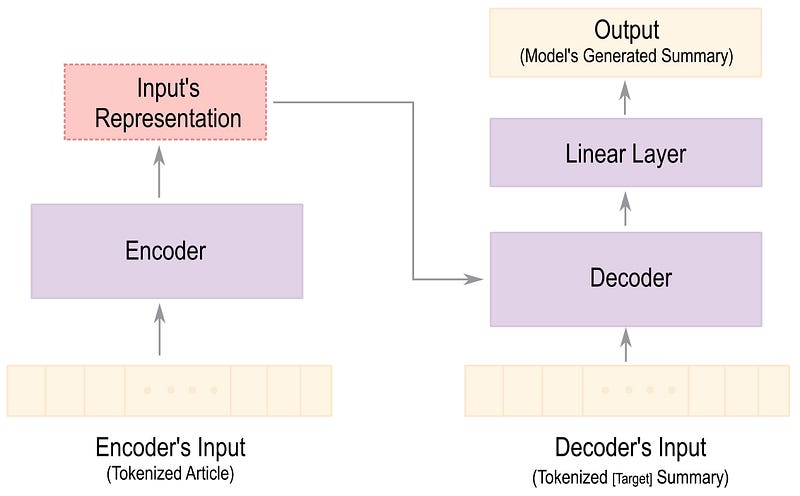
Let’s take a quick look at Figure 1 before diving into the code and assuming that the batch_size is 1. You should be familiar with most parts of the figure if you read the Part 1 story. (“What architecture to use?” subsection) The main difference (compared to inference) is that the entire target summary will be fed to the decoder during the training process so the model can learn what a good summary looks like.
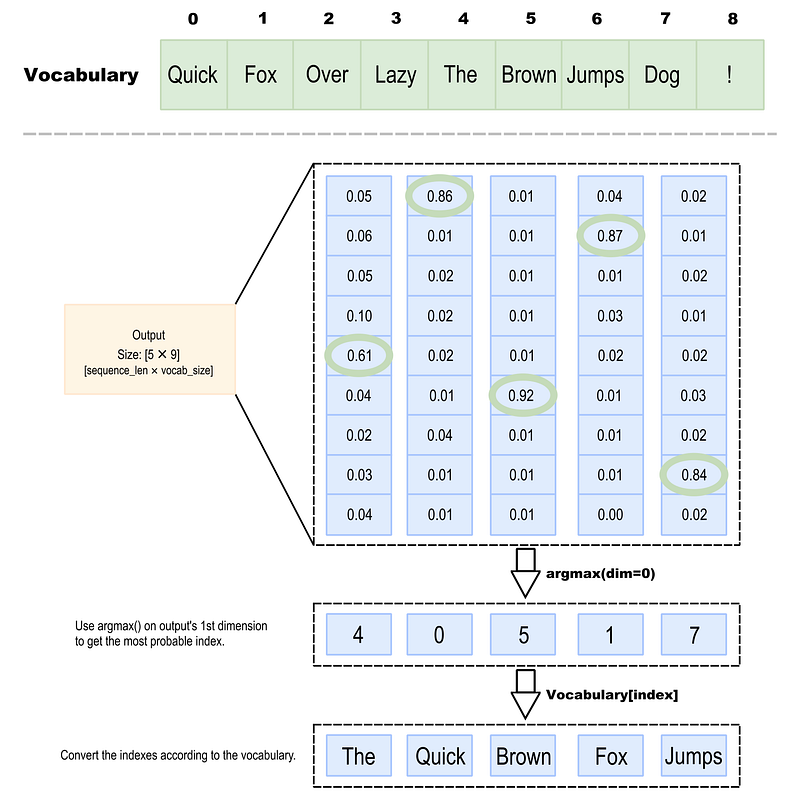
The output is a tensor with the size of [generated_sequence_length × vocabulary_size] where each index of the 1st dimension represents a token from the generated summary, and each index of the 2nd dimension represents a word from the tokenizer’s vocabulary and its probability of being the next token. A sample output tensor for a generated summary with five tokens is illustrated in Figure 2. The number of possibilities for each token is the same as the vocabulary size (9). To find the generated summary tokens, we will pick the index that holds the highest probability, and this index can be used and find the word from the vocabulary.
Let’s See the Code!
Dataset — The Huggingface co provides a great tool called “Datasets” that lets you quickly load and manipulate your data. We will use the CNN/DailyMail [2] dataset, a standard benchmark for the summarization task. Let’s start by loading the dataset. I am using only 1% of the dataset to speed up the process. (You should use the entire dataset by removing the [0:1%] part if you want to train your model)
If you are confused about the differences of pre-trained transformer-based models like BERT, BART, XLNet, MASS,… read the story “What are the differences in Pre-Trained Transformer-base models” that point out their differences.
The next step is to prepare the dataset based on the model except to see. As illustrated in Figure 1, the tokenized input (the article) and decoder inputs (target summary) alongside their attention masks (The mask can use it to ignore some tokens) with the addition of the labels parameter (that is the same as the target summary). The process_data_to_model_inputs() function will use the BART’s [1] tokenizer object to convert the dataset to the desired format. It also changes the padding token to -100 to ensure that irrelevant tokens will not affect the loss value. Then, we will map the mentioned function to datasets variables, set the correct format, and use PyTorch’s DataLoader function to make an iterative object to batch through the dataset.
Keep in mind that the code above only demonstrates the mapping and set_fromat process for the training set. If available, it should also be done for other sets like validation and test. The article and summary length variables are dependants on the model’s design choices. BART can accept up to 1024 tokens as input, but we set the sequence length limit to 512 to reduce the memory consumption. The same idea goes for choosing the batch size and should use a larger number if you have enough resources.
Model — We use the Huggingface’s BART implementation, a pre-trained transformer-based seq2seq model. Let’s start with loading the model and its pre-trained weights.
The BART’s fine-tuned model for text summarization is loaded using the BartForConditionalGeneration module and will download the weights using the from_pretrained() call. The model will be sent to GPU if any is available, and we will split it based on the components highlighted in Figure 1.
⚠️ Note on Splitting the Model: I’ve done this to make the connections and data flow more clear. It is only meant to be for teaching purposes to show you how the model works under the hood. In reality, you can easily call the model object, and it will take care of everything itself instead of splitting it. (We will see it while implementing the validating loop)
Loss Function and Optimizer — Two more modules needed for training are the CrossEntropy loss and the AdamW optimizer that can be loaded from PyTorch and the Huggingface, respectively. A linear scheduler is also selected to compliment the optimizer to change the learning rate during the training. The scheduler will increase the learning rate from zero to the specified value over the warm-up period and then decrease it back to zero.
Training Loop — Now, it is time to code the main loop. It is simply responsible for feeding a batch of data to the model and comparing its generated summary with the desired target summary using the loss function. And repeat the process!
The main loop begins with putting the batch on the GPU (if available) and follows bypassing the tokenized article through the encoder to get the representation. The encoder’s output will be given to the decoder with the target summary and processed using the last linear layer to get the model’s final prediction.
Reminder: This process can (and should be!) be done by calling the
model(**batch)to get the lm_head_output directly.
The rest of the loop will calculate the loss value for the current batch and adjust the model’s parameters. Lastly, send a signal to both optimizer and scheduler that the current step is done and make the optimizer ready for the next step by resetting the gradient.
Validation Loop — The final piece of the puzzle is to make a validation loop after each epoch to ensure that the model is not over-fitting and evaluate its performance on unseen data. Also, you can see how easy it is to calculate the loss using the model object itself in the code below.
⚠️ The full implementation is available in a notebook on Github.
Final Words,
This was the 2nd part of the series to cover the summarization task where I explained what happens during training a seq2seq (encoder-decoder) model. I recommend you look over the notebook content because some parts have not been mentioned here, and you can run the code on a Google Colab instance and see the outputs.
I send out a weekly newsletter for NLP nerds. Consider subscribing if you like to stay up-to-date on the latest developments in Natural Language Processing. Read more and subscribe — join the cool kids club and sign up now!
References
[1] Lewis, Mike, et al. “Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension.” arXiv preprint arXiv:1910.13461 (2019). [2] Nallapati, Ramesh, et al. “Abstractive text summarization using sequence-to-sequence rnns and beyond.” arXiv preprint arXiv:1602.06023 (2016).





