Machine Learning Art
How to teach the AI art generator to understand what we are talking about
personalized generation of AI ART

Where can I create AI art?
Large-scale text-to-image models have recently shown an ability to reason over natural language descriptions that have never been seen before. They let users combine new scenes with never-before-seen compositions to make vivid pictures in various styles.
🟠 DALL·E 2 , Imagen , Parti — Personalization
People have used these tools to make AI art, get ideas, and even come up with ideas for new physical products. However, their use is limited by how well the user can describe the desired target in text.
- August 2022 — AI art tools update can be found ➡️ HERE ⬅️
Personalized AI ART
How could we, as users, ask text-to-image models to make a scene in a book that includes a favorite toy from our childhood? Or to take our child’s drawing off the refrigerator and turn it into a work of AI art?
It is often hard to put new ideas into large-scale models. For each new concept, it’s too expensive to re-train a model with a larger data set, and fine-tuning on a few examples usually leads to forgetting.
The authors think these problems can be solved by finding new words in the textual embedding space of text-to-image models that have already been trained.
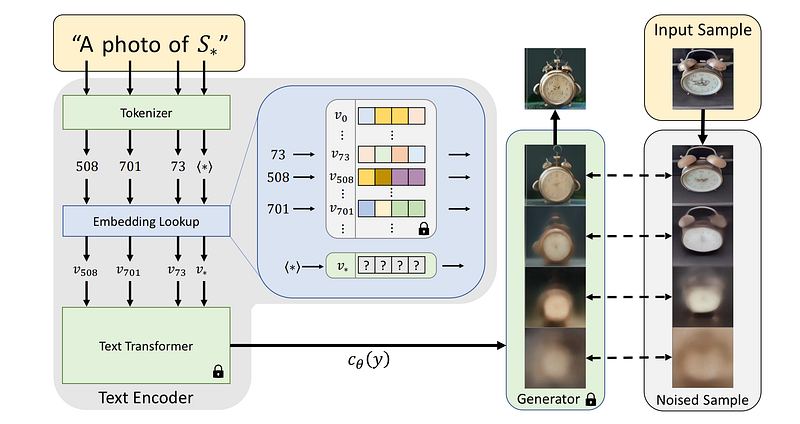
First, the authors look at the first step in the process of encoding text. In this case, a string that is read in is first turned into a set of tokens. Then, each token is replaced with its own embedding vector, and the downstream model is fed these vectors. The goal is to find new, specific embedding vectors representing new ideas.
Project Page (scroll down)

Researchers show a new embedding vector by a new pseudoword called S. This fake word is then treated like any other word and can be used to make new text queries for the generative models. So, you can ask for “a picture of S on the beach,” “an oil painting of a S on the wall,” or even a combination of two ideas, like “a drawing of S 1 in the style of S 2.”

Most importantly, this process does not change the generative model. By doing this, we keep the rich text understanding and generalization skills that are often lost when vision and language models are fine-tuned for new tasks. We think of the task as an inversion to find these fake words. We are given a fixed text-to-image model that has already been trained and a small set of images that show the idea. The authors aim to find a single-word embedding so that sentences like “A photo of S” can be used to piece together images from our small set.
This embedding is found through a process they call “Textual Inversion,” which is a way to improve the process. They look into a few more extensions based on tools usually used in Generative Adversarial Network (GAN) inversion. Their analysis shows that even though some core ideas are still the same, naively applying the prior art is either not helpful or can even be harmful.

The authors show how our method works with various ideas and prompts. They show how it can put unique objects into new scenes, change them into different styles, transfer poses, reduce biases, and even develop new products.
In short, the following are what the authors done: 🔵 The task of personalized text-to-image generation, in which we create new scenes from the user’s ideas with the help of natural language instruction.
🔵The concept of “Textual Inversions” in the context of generative models. Here, the goal is to find new “pseudowords” in the text encoder’s embedding space that can capture the high-level meaning and fine visual details.
🔵 Look at the embedding space in light of GAN-inspired inversion techniques and show a tradeoff between distortion and being able to change it. The authors show that our approach lies on an attractive part of the tradeoff curve.
🔵 The researchers tested the method on images that were made using user-provided captions of the concepts. They showed that their embeddings gave better visual accuracy and made editing easier.
AI art impact | Is AI generated art copyrighted?
The ability to learn different styles of art could be used to steal someone else’s work. Instead of paying an artist for their work, users could look at their pictures, copy their style, and make their own pictures. Generated artwork is still easy to spot, but it might be harder to find and take legal action against people who do this in the future.
Inversions of Text
The task of personalized, language-guided generation is a text-to-image model used to make images of specific concepts in new settings and scenes. “Textual Inversions” works by turning the ideas into new “pseudowords” in the textual embedding space of a text-to-image model that has already been trained.
These “fake words” can be added to new scenes using simple natural language descriptions. This makes changes easy and straightforward. In a way, the method lets a user use multi-modal information. It uses a text-driven interface to make editing more accessible but also gives visual cues when natural language isn’t enough.
Keywords: computer vision, Artificial Intelligence, Machine Learning, AI art, art, wombo dream, digital art, Dalle 2, Imagen, wombo ai, Parti, text-to-image, diffusion models, generative art, wombo art, photographic quality, img by AI system, AI art generator, text to art generator, free ai art generator, 3D ai art,
I invite you to explore the concept of “AI creativity” by reading and learningfrom the many articles found on 🔵 MLearning.ai 🟠
Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai
- Linkedin (20.3K+ ML-professionals)
- Twitter (5.1K+ followers)
- Instagram (2.3K + followers )
- Sketchfab * — individual vRooML!
- Youtube
- Apple Podcasts
- Substack
Title: An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
The Authors: Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, Daniel Cohen-OrProject Page:
https://arxiv.org/pdf/2208.01618.pdf