
How to Reduce Embedding Size and Increase RAG Retrieval Speed
Flexible text embedding with Matryoshka Representation Learning (MRL)

Introduction
Text embeddings are high-dimensional vector representations of single words or entire sentences.
These vectors (arrays) of numbers capture rich information about the underlying text that can be used for many downstream tasks, such as semantic understanding, classification, clustering, information retrieval (RAG), reranking, and more.
Usually, the dimension d of the embedding vector is fixed. The embedding dimension is typically a power of two, ranging from 64 up to 4096.
With Matryoshka embeddings, you can change the dimension of your embeddings depending on your application. This can reduce storage space, save costs, and increase retrieval speed.
What Are Text Embeddings?
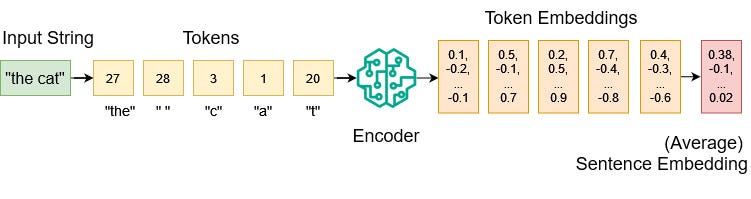
We start by defining a vocabulary that maps all possible input characters to integer values. The vocabulary includes not only characters from the alphabet, but also special characters, short words, and subwords:
{
"a": 1,
"b": 2,
"c": 3,
...
"z": 26,
"the": 27,
" ": 28
}After tokenization, we can feed the list of tokens to our encoder model. The encoder has learned from large amounts of training data to transform each token into a high-dimensional numerical vector embedding.
For example, OpenAI’s text-embedding-3-large model has an output dimension d for its embeddings of 3072.
To get a single sentence embedding, we need to compress the information from multiple token embeddings. One way to do this is to simply average over all the token embeddings.
Matryoshka Embeddings
Matryoshka embeddings were introduced by researchers from the University of Washington, Google Research, and Harvard University in the paper “Matryoshka Representation Learning” in 2022 [1].
Matryoshka embeddings are trained to encode information of different granularity in one single embedding vector.
For example, instead of simply training a full embedding vector of size d = 1024, with MRL we use a list of dimensions matryoshka_dims = [1024,512,256,128,64] for the loss function that we want to optimize for at the same time [2].
This results in an embedding vector with nested information, where the coarsest information is stored in the first few dimensions and more and more detail is stored in the later dimensions.
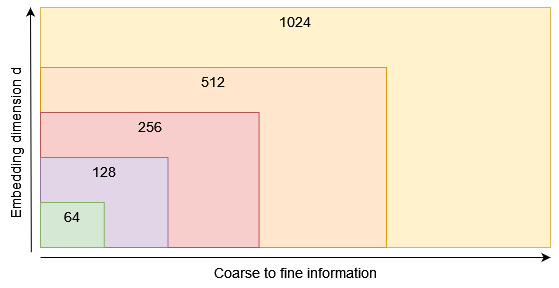
This effectively means that we can truncate our embedding vector wherever we want without sacrificing too much performance.
Why Does It Matter?
Suppose we want to store n text embedding vectors in a vector database. Each embedding has d dimensions. And each number is usually a 32-bit float. So we need n * d * 4 bytes for storage.
And if we want to compute similarity metrics like dot product or cosine similarity (which is just a normalized dot product), the higher the dimensionality d is, the more mathematical calculations we have to do.
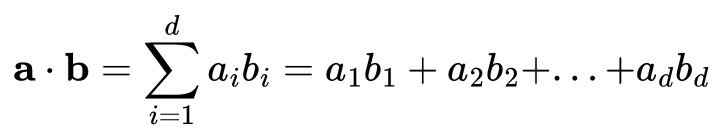
With MRL, if we care about a small memory footprint, fast processing speed, and therefore cost savings, we might only use the first 64 dimensions. If we want the best downstream performance, we use all dimensions. Or we might choose something in between.
Thus, MRL gives LLM users the ability to trade off embedding size (cost) for a small reduction in downstream performance.
Using MRL With Nomic AI
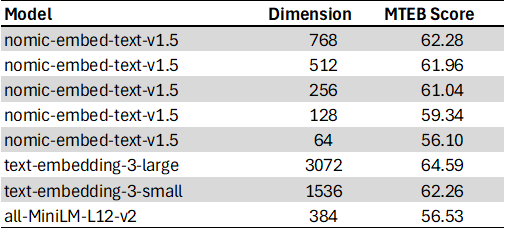
Nomic’s Matryoshka text embedding model nomic-embed-text-v1.5 was trained with matryoshka_dims = [768,512,256,128,64]. The model is publicly available on Hugging Face [3].
Another nice feature of this encoder model is that it supports different prefixes. The model supports the prefixes [search_query, search_document, classification, clustering] to get better embeddings for each specific downstream task.
Here is how nomic-embed-text-v1.5 performs on the Massive Text Embedding Benchmark (MTEB):
Let’s implement the model in Python using PyTorch and the Sentence Transformers library:
!pip install torch sentence_transformers einops
import torch
from sentence_transformers import SentenceTransformer
device = "cuda" if torch.cuda.is_available() else "cpu"model = SentenceTransformer(
"nomic-ai/nomic-embed-text-v1.5",
device=device,
trust_remote_code=True,
prompts={
"search_query": "search_query: ",
"search_document": "search_document: ",
"classification": "classification: ",
"clustering": "clustering: ",
},
)
def embed_sentences(
model: SentenceTransformer,
sentences: list[str],
prompt_name: str,
matryoshka_dim: int,
device: str,
):
assert matryoshka_dim <= 768, "maximum dimension for nomic-embed-text-v1.5 is 768"
embeddings = model.encode(
sentences, prompt_name=prompt_name, device=device, convert_to_tensor=True
)
embeddings = torch.nn.functional.layer_norm(
embeddings, normalized_shape=(embeddings.shape[1],)
)
embeddings = embeddings[:, :matryoshka_dim]
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)
return embeddings.cpu()Using the matryoshka_dim parameter, we truncate our 768-dimensional embedding vector and then normalize the new embedding vector.
Now, we can set our desired dimensionality and encode some Wikipedia text as well as our question for a Retrieval-Augmented Generation (RAG) use case:
matryoshka_dim = 64
wikipedia_texts = [
"The dog (Canis familiaris or Canis lupus familiaris) is a domesticated descendant of the wolf.",
"Albert Einstein was born in Ulm in the Kingdom of Württemberg in the German Empire, on 14 March 1879.",
"Einstein excelled at physics and mathematics from an early age, and soon acquired the mathematical expertise normally only found in a child several years his senior.",
"Werner Karl Heisenberg was a German theoretical physicist, one of the main pioneers of the theory of quantum mechanics, and a principal scientist in the Nazi nuclear weapons program during World War II.",
"Steven Paul Jobs (February 24, 1955 - October 5, 2011) was an American businessman, inventor, and investor best known for co-founding the technology giant Apple Inc.",
"The cat (Felis catus), commonly referred to as the domestic cat or house cat, is the only domesticated species in the family Felidae.",
]
question = ["Where was Albert Einstein born?"]
question_embedding = embed_sentences(
model,
sentences=question,
prompt_name="search_query",
matryoshka_dim=matryoshka_dim,
device=device,
)
document_embeddings = embed_sentences(
model,
sentences=wikipedia_texts,
prompt_name="search_document",
matryoshka_dim=matryoshka_dim,
device=device,
)print(f"document_embeddings.shape: {document_embeddings.shape}")
print(f"question_embedding.shape: {question_embedding.shape}")
>> document_embeddings.shape: torch.Size([6, 64])
>> question_embedding.shape: torch.Size([1, 64])We can visualize the first two dimensions of our Matryoshka text embeddings with a scatter plot. However, this embedding model was not explicitly optimized for a Matryoshka dimension of 2.
Next, we can store our document embeddings in a vector database. I’m using Faiss. Faiss is an open-source library from Meta Research for efficient similarity search and clustering of dense vectors [4].
!pip install faiss-cpu
import faiss
index = faiss.IndexFlatIP(matryoshka_dim)
index.add(document_embeddings)This creates a vector database using “exact search for inner product” with IndexFlatIP, which is the dot product similarity measure. Since we are using normalized embeddings, the dot product and the cosine similarity are the same.
index is now a vector database consisting of six text embeddings:
print(index.ntotal)
>> 6Let’s search for the most similar embeddings to our question and retrieve the top-k results:
distances, indices = index.search(question_embedding, k=6)
print(indices)
print(distances)
>> [[1 2 3 4 0 5]]
>> [[0.9633528 0.729192 0.63353264 0.62068397 0.512541 0.43155164]]Our most similar text has the index 1 in our database with a similarity score of 0.96 (the maximum is 1.0).
# results with d=64
print(question)
print(wikipedia_texts[1])
>> ['Where was Albert Einstein born?']
>> 'Albert Einstein was born in Ulm in the Kingdom of Württemberg in the German Empire, on 14 March 1879.'I also reran the code with matryoshka_dim=768 and got similar results. However, the higher dimensionality requires more memory and more computation.
# results with d=768
print(indices)
print(distances)
>> [[1 2 4 3 0 5]]
>> [[0.92466116 0.645744 0.54405797 0.54004824 0.39331824 0.37972206]]MRL & Quantization
If we want to compress our embeddings even further, we can use MRL together with binary vector quantization. Binary quantization converts all numbers in the embedding vector that are greater than zero to one and everything else to zero [5].

Using binary quantization, an embedding vector of dimension d requires only d / 8 bytes of memory, which is a 32x reduction in size compared to the d * 4 bytes of float32 [4]. However, this reduction comes at the cost of performance.
Conclusion
Embedding models that use the Matryoshka loss during training are optimized for multiple embedding dimensions at the same time.
With Matryoshka Representation Learning, LLM users can trade off text embedding size for a small performance hit.
Smaller embeddings require less memory and computation, which can save a lot of money in the long run. They are also faster to compute and therefore have a higher retrieval speed, for example for a RAG application.
References
[1] A. Kusupati et al. (2022), Matryoshka Representation Learning, arXiv:2205.13147
[2] MatryoshkaLoss: https://www.sbert.net/docs/package_reference/losses.html#matryoshkaloss (accessed: 04–05–2024)
[3] nomic-embed-text-v1.5 on Hugging Face: https://huggingface.co/nomic-ai/nomic-embed-text-v1.5 (accessed: 04–05–2024)
[4] Faiss Documentation: https://github.com/facebookresearch/faiss/wiki/Getting-started (accessed: 04–05–2024)
[5] A. Shakir, T. Aarsen, S. Lee (2024), Binary and Scalar Embedding Quantization for Significantly Faster & Cheaper Retrieval, Hugging Face Blog




