
How to load model YOLOv8 ONNXRuntime

YOLOv8 is the latest version (v8) of the YOLO (You Only Look Once) object detection system. YOLO is a real-time, one-shot object detection system that aims to perform object detection in a single forward pass of the network, making it fast and efficient. YOLOv8 is an improved version of the previous YOLO models with improved accuracy and faster inference speed.
ONNX (Open Neural Network Exchange) is an open format to represent deep learning models. To convert a YOLOv8 model to ONNX format, you need to use a tool such as ONNX Runtime, which provides an API to convert models from different frameworks to ONNX format. The exact steps would depend on the programming framework and tools you are using to develop and run your YOLOv8 model.
How to convert?
model = YOLO("yolov8n.pt")
results = model.predict(source="https://ultralytics.com/images/bus.jpg")[0]
model.export(format="onnx",imgsz=[640,640], opset=12) # export the model to ONNX formatHow to load ONNX Runtime?
onnxruntime is an open-source runtime engine for executing machine learning models that are represented in the Open Neural Network Exchange (ONNX) format. ONNX is an open standard for representing deep learning models that allows for interoperability between different frameworks and tools. ONNX models can be exported from a variety of deep learning frameworks, such as PyTorch, TensorFlow, and Keras, and can be executed on different hardware platforms, such as CPUs, GPUs, and FPGAs.
onnxruntime provides a unified API for executing ONNX models across different hardware platforms and operating systems. It supports a wide range of execution providers, including CPU, GPU, and specialized accelerators, such as NVIDIA TensorRT and Intel OpenVINO. onnxruntime also provides support for model optimization and quantization to improve model performance and reduce memory and storage requirements.
onnxruntime can be used in a variety of applications, such as computer vision, natural language processing, and speech recognition. It provides a high-performance and flexible runtime engine that allows for efficient execution of deep learning models in production environments.
Load model
# Install onnx runtime
pip3 install onnxruntimeimport onnxruntime
opt_session = onnxruntime.SessionOptions()
opt_session.enable_mem_pattern = False
opt_session.enable_cpu_mem_arena = False
opt_session.graph_optimization_level = onnxruntime.GraphOptimizationLevel.ORT_DISABLE_ALLThe code you have provided sets up an onnxruntime.SessionOptions object with a few options. Let’s go through them one by one:
- enable_mem_pattern: This option controls whether memory pattern optimization is enabled or not. When enabled, onnxruntime can analyze the memory usage pattern of a model and allocate memory more efficiently, which can reduce memory usage and improve performance. Setting this option to False disables memory pattern optimization.
- enable_cpu_mem_arena: This option controls whether CPU memory arena is enabled or not. Memory arena is a technique used by onnxruntime to manage memory more efficiently. When enabled, onnxruntime allocates memory in chunks and reuses them, which can improve performance. Setting this option to False disables CPU memory arena.
- graph_optimization_level: This option controls the level of optimization performed on the ONNX graph during inference. onnxruntime provides several levels of optimization, ranging from ORT_DISABLE_ALL (which disables all optimization) to ORT_ENABLE_EXTENDED (which enables all available optimization). In the code you provided, ORT_DISABLE_ALL is used, which disables all optimization.
model_path = 'yolov8n.onnx'
EP_list = ['CUDAExecutionProvider', 'CPUExecutionProvider']
ort_session = onnxruntime.InferenceSession(model_path, providers=EP_list)The code you provided sets up an onnxruntime.InferenceSession object, which is used to load an ONNX model and run inference on it. Let’s go through the parameters used:
- model_path: This parameter specifies the path to the ONNX model file that you want to load. In the example you provided, the path is set to ‘model_name.onnx’.
- providers: This parameter specifies the list of execution providers that should be used for inference. Execution providers are responsible for executing the operations in the ONNX model, and onnxruntime provides several built-in execution providers, including CPUExecutionProvider and CUDAExecutionProvider (which use CPU and GPU for inference, respectively). In the example you provided, a list of two execution providers is used: [‘CUDAExecutionProvider’, ‘CPUExecutionProvider’]. This means that onnxruntime will try to use the CUDAExecutionProvider first, and if it is not available (e.g., because there is no GPU), it will fall back to the CPUExecutionProvider.
model_inputs = ort_session.get_inputs()
input_names = [model_inputs[i].name for i in range(len(model_inputs))]
input_shape = model_inputs[0].shape
input_shapeThe code you provided retrieves the input information for the loaded ONNX model using the get_inputs method of the onnxruntime.InferenceSession object. Let’s go through the variables that are created:
- model_inputs: This variable is a list of input nodes for the loaded ONNX model. Each input node is represented as an onnxruntime.NodeArg object, which contains information about the name, shape, and data type of the input.
- input_names: This variable is a list of the names of the input nodes for the model. The names can be used to identify the inputs when running inference on the model.
- input_shape: This variable contains the shape of the first input node in the model. Since the ONNX model can have multiple inputs, the shape of each input may be different. In the example you provided, the shape of the first input node is retrieved by accessing model_inputs[0].shape.
By retrieving the input information for the model, you can prepare the input data that needs to be passed to the model when running inference. You can use the input names and shapes to create the input data in the correct format. Once you have prepared the input data, you can pass it to the run method of the onnxruntime.InferenceSession object to run inference on the model.
model_output = ort_session.get_outputs()
output_names = [model_output[i].name for i in range(len(model_output))]The code you provided retrieves the output information for the loaded ONNX model using the get_outputs method of the onnxruntime.InferenceSession object. Let’s go through the variables that are created:
- model_output: This variable is a list of output nodes for the loaded ONNX model. Each output node is represented as an onnxruntime.NodeArg object, which contains information about the name, shape, and data type of the output.
- output_names: This variable is a list of the names of the output nodes for the model. The names can be used to identify the outputs when running inference on the model.
By retrieving the output information for the model, you can access the output data produced by the model during inference. You can use the output names and shapes to retrieve the output data in the correct format. Once you have retrieved the output data, you can use it to perform further processing or analysis.
Detection
import cv2
import numpy as np
from PIL import Image
image = cv2.imread('bus.jpg')
image_height, image_width = image.shape[:2]
Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))input_height, input_width = input_shape[2:]
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
resized = cv2.resize(image_rgb, (input_width, input_height))
# Scale input pixel value to 0 to 1
input_image = resized / 255.0
input_image = input_image.transpose(2,0,1)
input_tensor = input_image[np.newaxis, :, :, :].astype(np.float32)
input_tensor.shapeLet’s go through the code you provided:
- input_height and input_width: These variables contain the height and width of the input tensor required by the ONNX model. The height and width were obtained from the input_shape variable, which was retrieved from the ONNX model earlier.
- image_rgb: This variable contains the input image data in RGB color format. The original image data was read using OpenCV’s imread function, which reads images in the BGR color format by default. The cvtColor function is used to convert the image data from BGR to RGB color format.
- resized: This variable contains the resized image data, which is resized to match the dimensions of the input tensor required by the ONNX model. The resize function is used to resize the image data.
- input_image: This variable contains the input tensor data after normalization and rearrangement of the image data. The pixel values of the resized image data are first scaled to the range of 0 to 1. Then, the dimensions of the image data are rearranged to match the input tensor format required by the ONNX model, which is (batch_size, channel, height, width).
- input_tensor: This variable contains the final input tensor data, which is a NumPy array with shape (batch_size, channel, height, width). The batch size is set to 1 since only a single image is being processed. The data type of the array is float32.
Once you have prepared the input tensor data, you can pass it to the run method of the onnxruntime.InferenceSession object to run inference on the model.
outputs = ort_session.run(output_names, {input_names[0]: input_tensor})[0]outputs: This variable contains the output data produced by the ONNX model during inference. The run method returns a tuple of outputs for the model, with each output represented as a NumPy array. In this case, we are only interested in the first output, which is why we use [0] to access it.
To run inference on the model, we pass the input tensor data as a dictionary to the run method, where the keys are the names of the input nodes for the model (in this case, input_names[0]), and the values are the input tensor data. We also provide a list of output node names (output_names) so that the run method knows which outputs to return. Once the run method is called, it performs inference on the model and returns the output data in the form of NumPy arrays.
predictions = np.squeeze(outputs).T
conf_thresold = 0.8
# Filter out object confidence scores below threshold
scores = np.max(predictions[:, 4:], axis=1)
predictions = predictions[scores > conf_thresold, :]
scores = scores[scores > conf_thresold] The code you provided is used to filter out predictions with object confidence scores below a certain threshold. Let’s go through the variables that are created:
- conf_threshold: This variable specifies the threshold value for object confidence scores. Any predictions with object confidence scores below this threshold will be filtered out.
- scores: This variable contains the maximum object confidence score for each predicted bounding box. The object confidence score is the fifth element of the predicted values for each bounding box, i.e., predictions[:, 4:]. The max function is used to compute the maximum confidence score across all object classes for each predicted bounding box. The resulting scores array has shape (num_boxes,), where num_boxes is the number of predicted bounding boxes.
# Get the class with the highest confidence
class_ids = np.argmax(predictions[:, 4:], axis=1)class_ids: This variable contains the class IDs (i.e., the object classes) for each predicted bounding box. The class probabilities for each bounding box are given by the last num_classes elements of the predicted values for that bounding box, i.e., predictions[:, 4:]. The argmax function is used to find the index of the maximum probability (i.e., the predicted class) for each bounding box. The resulting class_ids array has shape (num_filtered_boxes,), where num_filtered_boxes is the number of filtered bounding boxes (i.e., those with confidence scores above the threshold). Each element of the class_ids array corresponds to the predicted object class for the corresponding bounding box
# Get bounding boxes for each object
boxes = predictions[:, :4]
#rescale box
input_shape = np.array([input_width, input_height, input_width, input_height])
boxes = np.divide(boxes, input_shape, dtype=np.float32)
boxes *= np.array([image_width, image_height, image_width, image_height])
boxes = boxes.astype(np.int32)
boxesThe code you provided is used to compute the bounding box coordinates for each predicted object, and rescale them back to the original image size. Let’s go through the variables that are created:
- boxes: This variable contains the predicted bounding box coordinates for each object, in the format (x1, y1, x2, y2). The x1 and y1 coordinates are the top-left corner of the bounding box, and the x2 and y2 coordinates are the bottom-right corner of the bounding box. The boxes variable has shape (num_filtered_boxes, 4), where num_filtered_boxes is the number of filtered bounding boxes (i.e., those with confidence scores above the threshold). Each row of the boxes array corresponds to the predicted bounding box coordinates for the corresponding object.
- input_shape: This variable contains the shape of the input image, as (input_width, input_height, input_width, input_height). This is used to rescale the bounding box coordinates from the normalized input size (i.e., the size of the image that was passed to the model) back to the original image size.
- The first line of code simply gets the bounding box coordinates for each object from the predictions array. Since the bounding box coordinates are the first four elements of each row of the predictions array, we simply take the first four columns of the predictions array to get the boxes variable.
- The second line of code rescales the bounding box coordinates from the normalized input size to the original image size. This is done by dividing the boxes array by the input_shape array, element-wise, using numpy’s divide function. We cast the resulting array to np.float32 to avoid integer division.
- The third line of code multiplies the rescaled boxes array by the original image size, again element-wise. This rescales the bounding box coordinates from the normalized input size to the original image size. We cast the resulting array to np.int32 to ensure that the bounding box coordinates are integers (since we can’t have fractional pixel coordinates).
def nms(boxes, scores, iou_threshold):
# Sort by score
sorted_indices = np.argsort(scores)[::-1]
keep_boxes = []
while sorted_indices.size > 0:
# Pick the last box
box_id = sorted_indices[0]
keep_boxes.append(box_id)
# Compute IoU of the picked box with the rest
ious = compute_iou(boxes[box_id, :], boxes[sorted_indices[1:], :])
# Remove boxes with IoU over the threshold
keep_indices = np.where(ious < iou_threshold)[0]
# print(keep_indices.shape, sorted_indices.shape)
sorted_indices = sorted_indices[keep_indices + 1]
return keep_boxes
def compute_iou(box, boxes):
# Compute xmin, ymin, xmax, ymax for both boxes
xmin = np.maximum(box[0], boxes[:, 0])
ymin = np.maximum(box[1], boxes[:, 1])
xmax = np.minimum(box[2], boxes[:, 2])
ymax = np.minimum(box[3], boxes[:, 3])
# Compute intersection area
intersection_area = np.maximum(0, xmax - xmin) * np.maximum(0, ymax - ymin)
# Compute union area
box_area = (box[2] - box[0]) * (box[3] - box[1])
boxes_area = (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
union_area = box_area + boxes_area - intersection_area
# Compute IoU
iou = intersection_area / union_area
return iou
# Apply non-maxima suppression to suppress weak, overlapping bounding boxes
indices = nms(boxes, scores, 0.3)The code you provided is used to perform non-maximum suppression (NMS) on the filtered bounding boxes. NMS is a technique used in object detection to suppress overlapping bounding boxes and retain only the ones with the highest confidence scores
Visualize
# Define classes
CLASSES = [
'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat',
'traffic light', 'fire hydrant', 'street sign', 'stop sign', 'parking meter', 'bench', 'bird', 'cat',
'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'hat', 'backpack', 'umbrella',
'shoe', 'eye glasses', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'plate',
'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli',
'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'mirror',
'dining table', 'window', 'desk', 'toilet', 'door', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'blender', 'book', 'clock', 'vase',
'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]def xywh2xyxy(x):
# Convert bounding box (x, y, w, h) to bounding box (x1, y1, x2, y2)
y = np.copy(x)
y[..., 0] = x[..., 0] - x[..., 2] / 2
y[..., 1] = x[..., 1] - x[..., 3] / 2
y[..., 2] = x[..., 0] + x[..., 2] / 2
y[..., 3] = x[..., 1] + x[..., 3] / 2
return yimage_draw = image.copy()
for (bbox, score, label) in zip(xywh2xyxy(boxes[indices]), scores[indices], class_ids[indices]):
bbox = bbox.round().astype(np.int32).tolist()
cls_id = int(label)
cls = CLASSES[cls_id]
color = (0,255,0)
cv2.rectangle(image_draw, tuple(bbox[:2]), tuple(bbox[2:]), color, 2)
cv2.putText(image_draw,
f'{cls}:{int(score*100)}', (bbox[0], bbox[1] - 2),
cv2.FONT_HERSHEY_SIMPLEX,
0.60, [225, 255, 255],
thickness=1)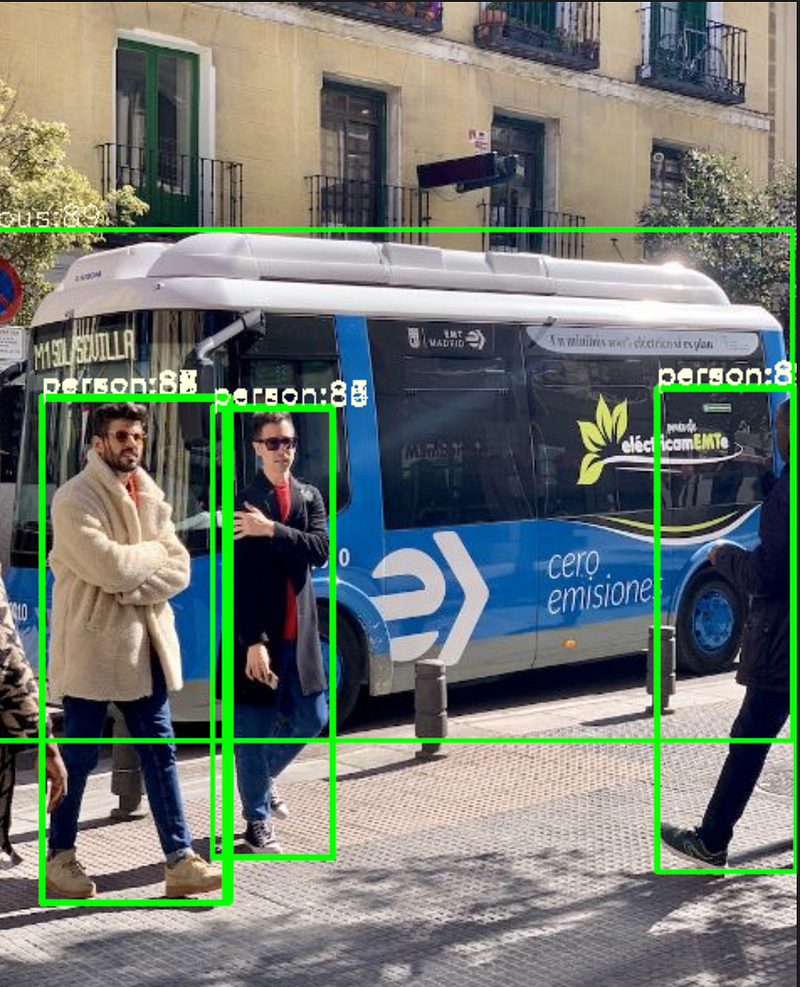
Conclusion
be used to perform object detection using a pre-trained YOLOv8n model in ONNX format. onnxruntime provides a flexible and high-performance runtime engine for executing deep learning models in production environments, and supports a wide range of hardware platforms and execution providers. The code also shows how the output of the model can be processed to extract the bounding boxes and class labels of the detected objects, which can be used for a variety of downstream applications, such as tracking, counting, or recognition.
If you found this article helpful, please consider following my medium account for more informative and insightful content. Thanks

Link Notebook : https://colab.research.google.com/drive/1lIaP7r3I4kSgi3AVYf6fhgRZ56JMpXEL?usp=sharing
next :
Reach me at
- LinkedIn : www.linkedin.com/in/alimustoofaa
- Email : [email protected]
- Github : https://github.com/Alimustoofaa
- Twitter : https://twitter.com/Alimustoofaa




