
How to Label Unlabeled Tweets
Unsupervised Learning

While learning data science, we mostly get a well-labeled dataset to build our models on. However, in a real-world scenario, seldom do we get good labeled datasets. Many data science problems revolve around the unlabeled and unstructured data domain. A primary solution to analyze unlabeled data is through Clustering. However, a more important aspect here is to understand how to cluster.
Clustering can only be done on numerical values as it primarily calculates the similarity of each datapoint with respect to others by calculating their mathematical distance (Euclidean, Manhattan, Minkowski, etc.). Hence, we can either cluster the textual data points by converting them into a numerical dissimilarity matrix, or we can cluster them by understanding the semantics of the textual datapoints by vectorizing and clustering them by their word embeddings.

When it comes to sentiment analysis, it often makes sense to understand the semantics in order to cluster similar meaning words together. Thus, I’ll further discuss a step-by-step process of carrying out a sentiment analysis of an unlabeled dataset. A prime example of unlabeled data is the tweets! I’ll try to unbundle this enigma of unlabeled data by analyzing all the tweets related to Electric Cars!
Why Electric Cars?

Electric cars are the future, is a statement that has been extensively marketed by experts in the last few years. Due to this, their popularity is booming and a lot of big players from the automobile industries have shown keen interest in them. But is this exuberance shared by mainstream forecasters as well? I’ll carry out a thorough evaluation of how the general public perceives Electric cars and will do a feasibility test of Electric cars in the current world scenario.
My main purpose would be to assess the general public narrative around electric cars by doing a thorough analysis of all the tweets made about electric cars. I’ll then build a machine learning model that analyses tweets and predicts their sentiments, primarily into Positive, Negative, and Neutral.
I’ll be using TWINT library to fetch all the tweets related to Electric Cars. It is an advanced Twitter scraping tool written in Python that allows for scraping Tweets from Twitter profiles without using Twitter’s API. I create a Data Frame from the response from Twint for all the tweets with a Hashtag #ElectricCar, from January 1st, 2010 to June 17, 2021, and 10 minimum likes for each tweet, total tweets collected around 90 thousand tweets.
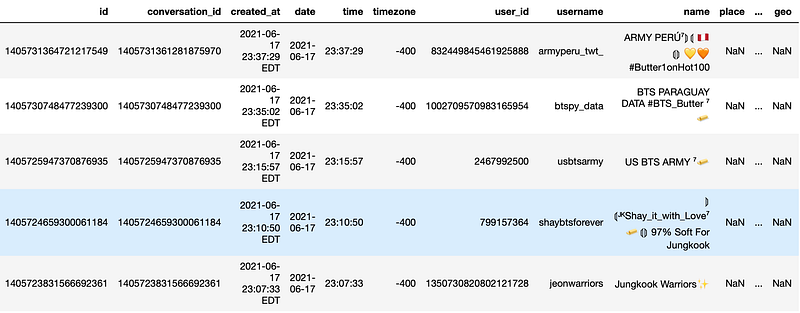
Since there are no labels available on this raw data, I’ll be using an unsupervised modeling approach for this problem. I want the model to learn the pattern, understand the semantics of the data and make sense out of it following few dedicated steps.
Cleaning:
Tweets are unstructured and informal types of data. People often tend to use slang, multiple languages, numbers, web links, hashtags, and emojis in their tweets to express their opinions. Most of them (except hashtags and emojis) are not strong individual contributors to emotional sentiments and hence, it makes sense to remove them from our tweets. Thus, I choose to remove the following:
- Special characters such as (@,*,&)
- Punctuations
- Numbers
- Usernames
- short words of length 1
I also try to lemmatize the words and bring the words back to their roots. This helps us to avoid multiple variations of the same word. Hence, words like “running,” “walking” and “buying” get converted to their root forms “run”,” walk” and “buy” respectively.
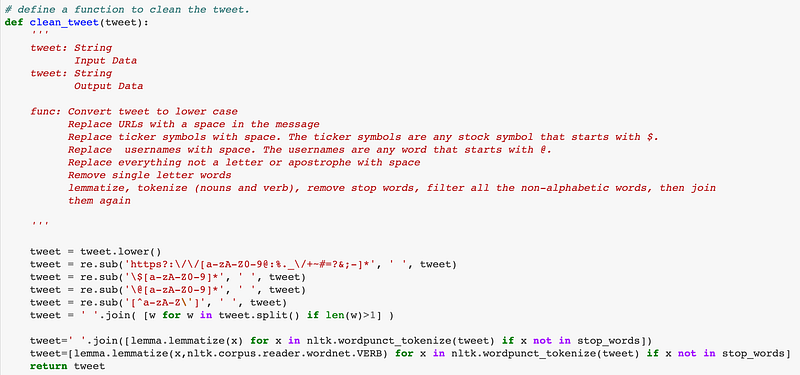
Word Embeddings:
Word Embeddings is an NLP technique of representing words in the form of vectors. The primary purpose of word embeddings is to represent similar words using word vectorization. Long story short, it detects similarities between words mathematically. More specifically it aims to capture similarities between words based on their distributional properties in large samples of language data. It can be summed with an argument- “a word is characterized by the company it keeps”. Given enough data, usage, and contexts, word embeddings can make some really accurate guesses of what exactly a word means.
In our context, I am going to train a word2vec model with CBOW architecture on our custom data.


I test the model by checking all similar words related to “battery” with our custom dataset.

The model identifies lithium ion, energy storage, million-mile, copper, and lithium as the closet words related to “battery”. This shows that the model has learned a good amount of context from our custom data. However, our next task is to use these embeddings and cluster all those tweets which are similar to each other with respect to their context.
Clustering:
Clustering is again, an example of unsupervised learning. There are multiple clustering techniques, which ideally assume that the observed data is heterogeneous, and partitioning it into multiple populations will make the clusters homogeneous. For our problem, I’ll be using K-means Clustering. K-means Clustering technique aims to partition n observations into k-clusters in which each observation belongs to the cluster whose mean (centroid) is nearest to it. Since I ought to find only 3 major clusters -Positive, Negative, and Neutral, I’ll use k=3.

We then observe how the words get distributed in each of the clusters.
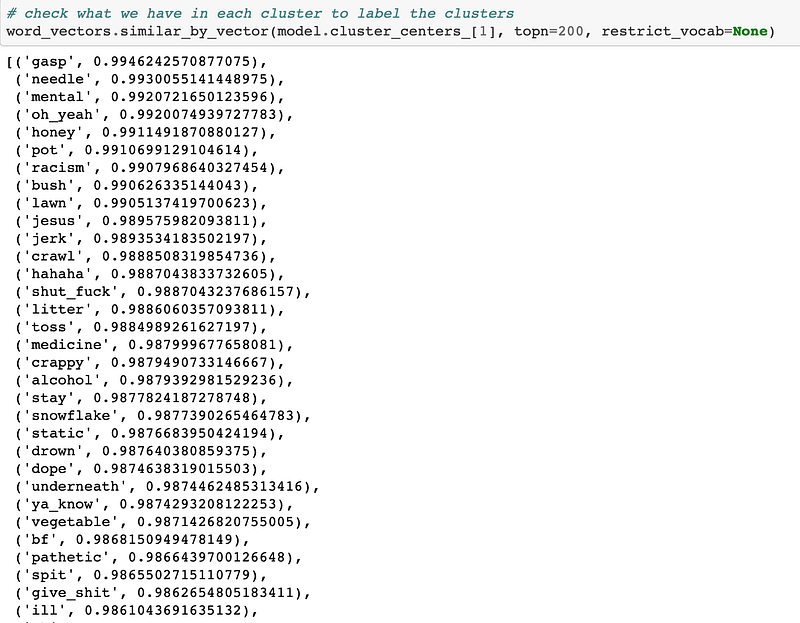
This is one of the clusters which has words like mental, racism, jerk, crappy, and pathetic. Hence, we can safely assume that this cluster set belongs to negative words. Similarly, we can find and segregate words into positive and neutral clusters as well.

However, the segmentation of these clusters is not perfect. Not all negative, positive and neutral words fall under negative, positive, and neutral clusters respectively. There is a chance of mix-ups- with negative words falling under the positive category and vice versa. Hence, I created a provision in which if we identify a misclassified word, we can sort the word into its correct cluster manually.

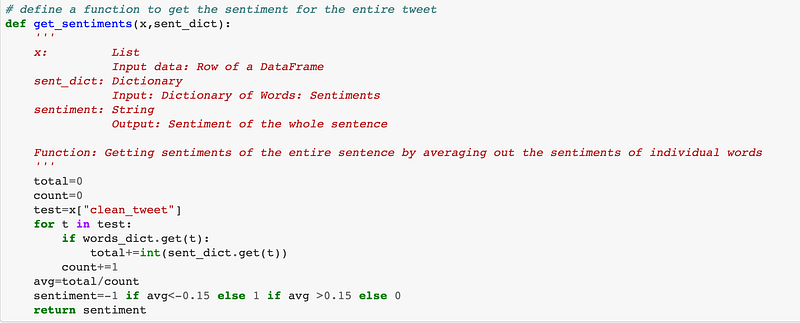
Get Sentiments:
Each word within the corpus now has a Negative (-1), Neutral (0), and Positive (1) sentiment attached to it. I take a cumulative sentiment of all words within a tweet and divide it by the total number of words to get a resultant sentiment for the whole tweet. A positive result amounts to Positive sentiment whereas a 0 and negative value would amount to Neutral and Negative sentiments respectively. For e.g.: if a tweet has 4 positive, 2 neutral and, 2 negative words, then the sentiment of the tweet will be calculated as:
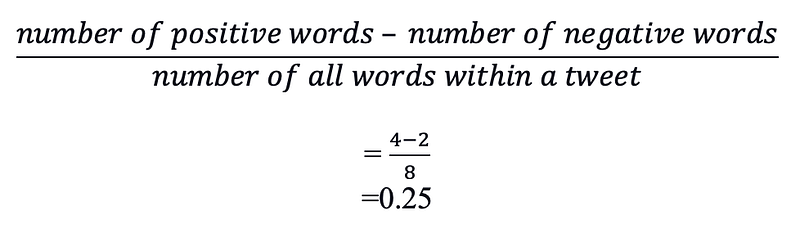
Thus, the tweet would be marked as positive as it has more positive dominant words. However, in certain cases where suppose we have 6 neutral words and just 1 positive/negative word, the result from the above formula would be 0.14/-0.14 respectively. Here, it will be unfair to say that the tweet is firmly positive/negative as 6 out of 7 words are simply neutral. Hence, I decided to increase the coverage of neutral sentiments from just 0 to -0.15 to 0.15. Hence, all tweets falling in the above sentiment range are marked as neutral. This approach resulted in better overall results.
Then evaluate the Sentiment Distribution of Tweets within the whole corpus.
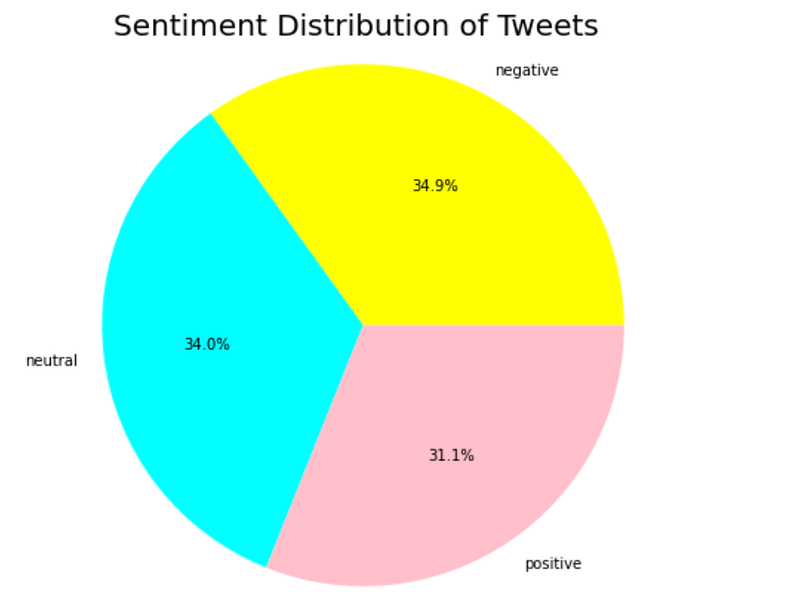
The tweets are equally spread out between positive, negative, and neutral sentiments, with negative sentiments leading marginally.
Let’s Visualize:
I filter out the tweets made against the major car manufacturers (Ford, BMW, Tesla, Audi, Bollinger Motors, Hyundai, Dodge) and evaluate general public sentiments toward them.

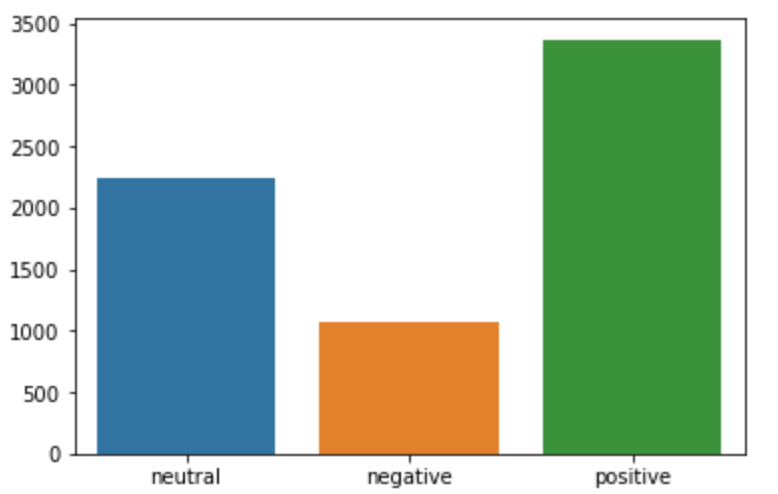
Here, we can make out that most of the tweets are positive. This shows that more people have positive or reserved thoughts on EVs, but only a small fraction of people have outright negative sentiments. Similarly, when we filter the tweets for words like Costs, Batteries, Climate, fuel, Price, and Afford, the results are quite expected

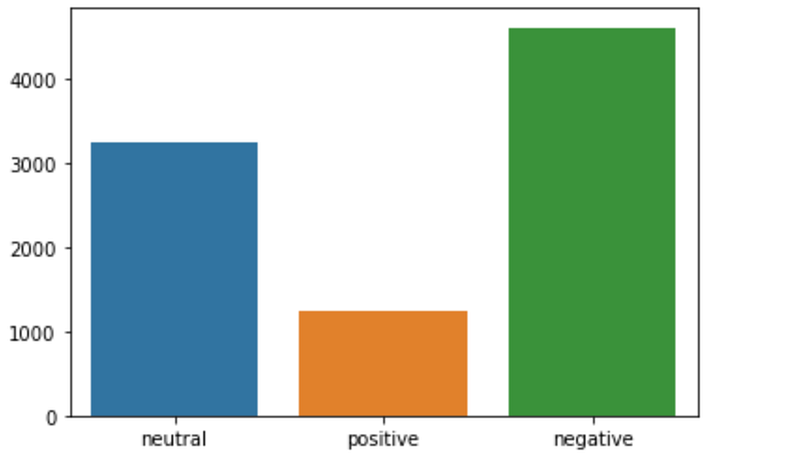
The majority of the sentiments turn out to be negative. This shows that more people have a genuine concern about the negative points of EVs. They seem concerned about the costs of the EVs or their negative impacts on the environment.
Evaluating our results:
We successfully labeled the data and carried out a whole lot of analysis around the electric cars. But how close are we to the actual real-world scenario? To answer this question, I am going to compare the labeled sentiments with the stock market trend to see if the general public sentiments correlate with stock market trends.
I collect the stock market data of Tesla using Yahoo finance library


I filter all the tweets about Tesla. Thus, we have an equivalent dataset for Tesla across public sentiments and stock market trends. We take a sample from the last three years Filtering tweets about Tesla and stock market trends for the year 2018, then merging both the datasets on a Month-on-Month basis, and scale the data for better visualization

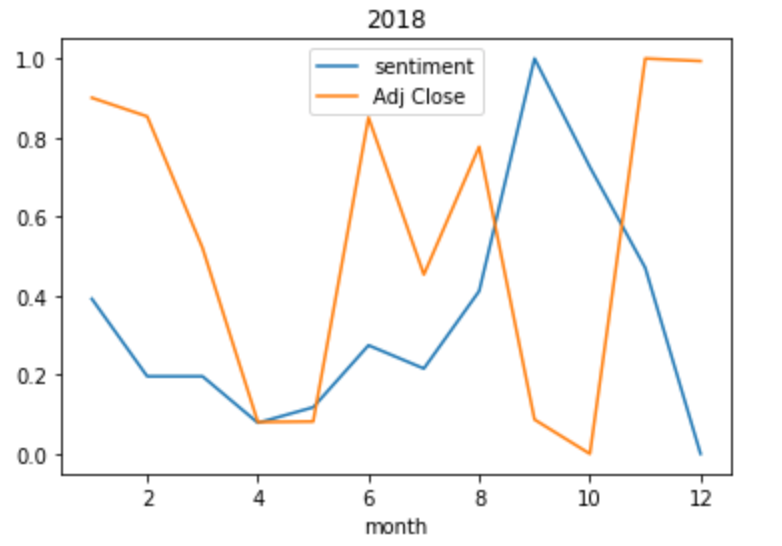
There was a sharp decline in sentiments in April-May of 2018 and a similar decline can be seen in the stock prices. Also, A recovery can be seen in June and August in both stocks and sentiments. However, the rise and fall of sentiments are more extreme as compared to stocks. This can be because people are usually at the extreme when expressing their excitement or anguish, but the same cannot be said about the regulated stock markets. But What happens when we evaluate the same case for 2020?
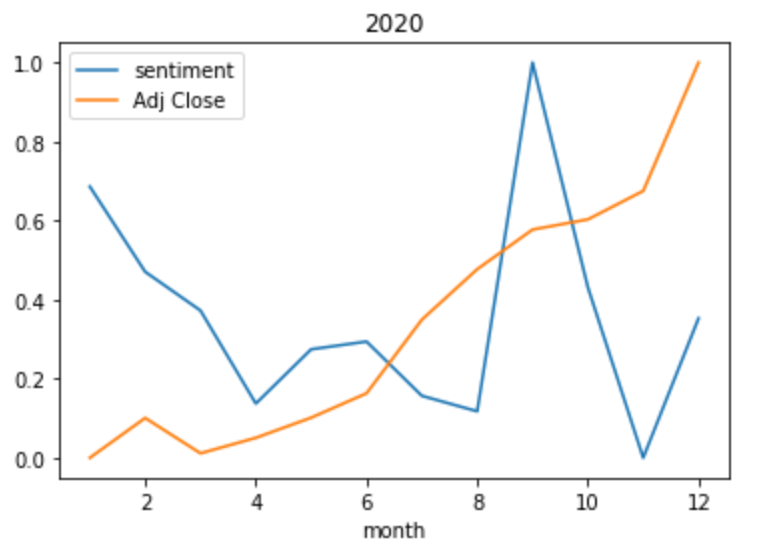
Boom! The year 2020 has been a complete anomaly. The Stock prices and sentiments had a similar curve from April till June and from August till October. After that, there has been a completely negative trend in the sentiments whereas the stock prices have flourished. This trend can be attributed to the fact that most people were going through a tough time in the latter half of 2020.
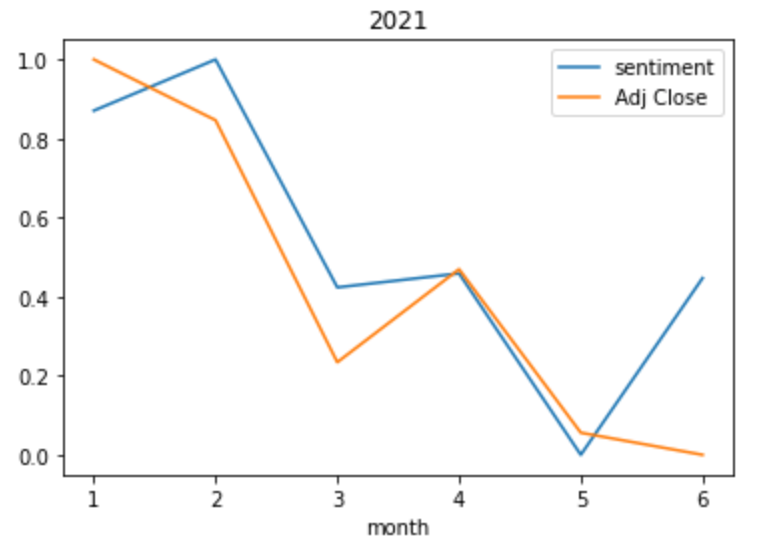
Woah!! Both the stock prices and the Sentiments curve have followed an exceptionally similar trend in 2021. Also, The values for both curves have been a little volatile this year. Since May, the sentiments for Tesla seemed to have improved, whereas the stock prices are still on a decline.
Conclusion:
We were able to convert our unlabeled dataset into a labeled one by a combination of clustering and word embeddings. It is always a good practice to train the embeddings model with your own custom data to get results closer to your expectations. Now, we can train any ML model with this labeled data and create a pipeline architecture that will keep predicting the sentiments of every incoming tweet. Also, now we know that Tweeples (people on Twitter) are fairly enthusiastic about the emergence of EV’s and mostly have positive sentiments attached to them. However, a fair amount of them has genuine concerns about the impact of EVs on the environment.
For full code click here, and Thanks for Reading!