
Machine Learning Art
How to generate 3D scenes from text descriptions
A Machine Learning Architect | Github: Source code
3D content creation
A new method that enables new tasks such as generating 3D scenes from text descriptions.
- August 2022 — AI art tools update can be found ➡️ HERE ⬅️
So that learning systems can understand and make 3D spaces, there needs to be a lot of progress in generative models for 3D.
Antoni Gaudi said, “The creation continues incessantly through the media of humans.”
3D Scene Generation
The new method, Gaudi, can learn the distribution of 3D scenes and render views from scenes taken from that distribution. It would significantly impact many machine learning and computer vision tasks. For example, you could try out plausible scene completions that fit with what you see in an image or what you read in a text. Also, these kinds of models would be beneficial in model-based reinforcement learning and planning, SLAM, and making 3D content.
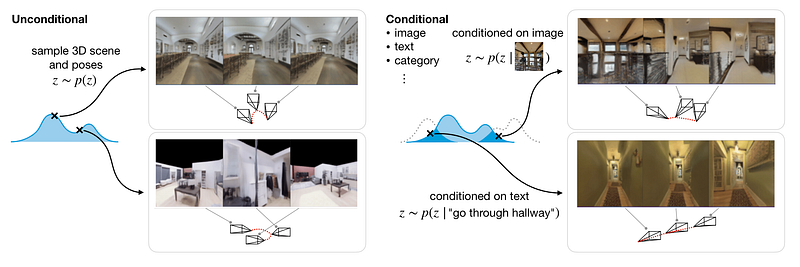
GAUDI lets you model both dependent and independent distributions over complicated 3D scenes. Scenes and poses from the unconditional distribution (on the left) and a distribution that depends on an image observation or a text prompt (on the right).

Gaudi can be summed up as follows:
🔵 It can make 3D scenes with hundreds of thousands of images for thousands of indoor scenes without mode collapse or canonical orientation problems during training.
🔵 A new denoising optimization goal to find latent representations that jointly model a radiance field and the camera poses in a separate way.
🔵 The approach gets state-of-the-art generation performance across multiple datasets.
🔵 The approach allows for different generative setups, including unconditional generation and generation based on images or text.
Project Page (Scroll Down)
Text conditional generation
A sample from a text conditional GAUDI model. Prompt: “walk into the kitchen”

Text to 3D Scene Generation
GAUDI is a generative model that can show how complex and realistic 3D scenes are distributed. GAUDI uses a two-step method that can be scaled up. The first step is to learn a latent representation that separates radiance fields and camera poses. Then, a strong prior is used to model the distribution of latent representations that have been separated from each other. Comparing the model’s performance to recent baselines across multiple 3D datasets and metrics shows that it is at the top of the field. GAUDI can be used for both conditional and unconditional problems. It also makes it possible to do new things, like make 3D scenes from text descriptions.
Keywords: computer vision, Artificial Intelligence, Machine Learning, AI art, art, wombo dream, digital art, Dalle 2, Imagen, wombo ai, Parti, text-to-image, diffusion models, generative art, wombo art, photographic quality, img by AI system, AI art generator, text to art generator, free ai art generator, 3D ai art
I invite you to explore the concept of “AI creativity” by reading and learningfrom the many articles found on 🔵 MLearning.ai 🟠
Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai
- Linkedin (19.8K+ ML-professionals)
- Twitter (5.1K+ followers)
- Instagram (2.2K + followers )
- Sketchfab * — individual vRooML!
- Youtube
- Apple Podcasts
- Substack
Project Page:
https://arxiv.org/pdf/2207.13751.pdf
Github:
https://github.com/apple/ml-gaudi
@article{bautista2022gaudi,
title={GAUDI: A Neural Architect for Immersive 3D Scene Generation},
author={Miguel Angel Bautista and Pengsheng Guo and Samira Abnar and Walter Talbott and Alexander Toshev and Zhuoyuan Chen and Laurent Dinh and Shuangfei Zhai and Hanlin Goh and Daniel Ulbricht and Afshin Dehghan and Josh Susskind},
journal={arXiv},
year={2022}
}




