How to Extract and Summarize with BeautifulSoup and TextRank
In this, we will scrape the data from the web using Beautiful soup with python and then use the scraped data to summarize the article to get a glance overview of it. Nowadays time is crucial in our life. To read the news or some articles we need to spend some time, So now we are going to summarize the news or articles through Summarization.
In summarization, there are two types they are Abstractive and extractive Summarization.
Abstractive Summarization: In this method, It selects words based on the relation between them. even those words are not present in the articles. It gives the information in a new way. The flowchart will be like we input a document and then it understands the data and gives the information in new words with the original context.
Extractive Summarization: This method summarizes the article and gives the same subset of words which are essential. Different algorithms and techniques are used to weights the sentences and rank them based on the priority sentences and give the summarized information. We input the document, it checks the sentence similarity then weight the sentence and gives the higher ranks sentences as summarized data.
Here we use the news article to Summarize the data
Beautiful Soup
Now we extracted the news article link, with the link and parse HTML we will extract the information from the article. we use requests python library to on the link and Beautiful soup library to extract the parse Html information.
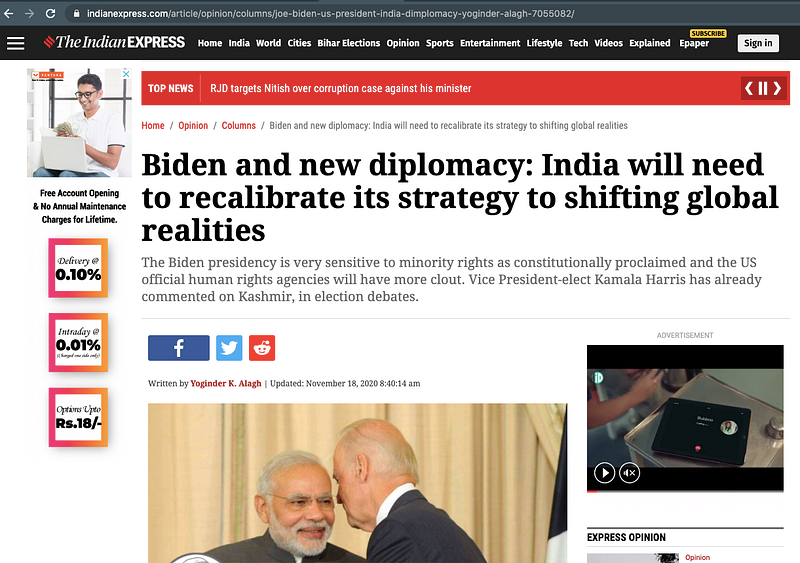


In html_doc variable, we use the requests library and get the URL content. Soup is the root of prased tree of our HTML page which allows us to search elements in tree. ‘div’ containing article will make us search for the subtree of the article.
By inspect element option. We can get the HTML code in the side of the particular browser we can search for the particular part of the article and take the class name, tag name. later we use the code and extract the text.
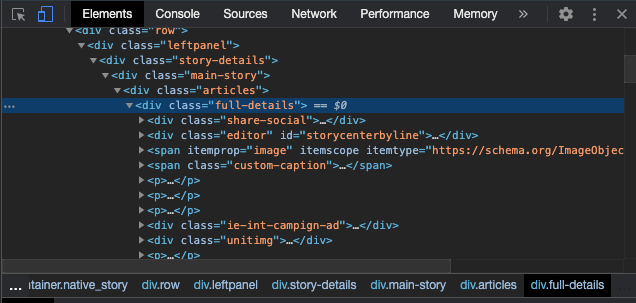
we can see in the above picture we took the div tag and full-details class and later from the tag p we extracted the whole data from it. We took the h1 tag which is the heading of the article. author form a tag, and the keywords from the story tags class.
we can see all_tags variable in the code. where we extracted all the unoreder list elements into it. After extracting the data. we use required data from the article.
Text Rank Algorithm
let’s start the summarize data process. There are many processes to do extractive summarization. let’s do it in a simple way by the unsupervised learning approach. In this, we find the sentence similarity and rank. specially no need to train the model. directly start using the data that we extracted from the article. we use Cosine similarity in the code it is used to calculate the similarity between the two non-zero vectors of an inner product space that measures the cosine angle between them. if the sentences are similar the angle between them be 0.
A clear view of what we do is, first input the data of the article next splits into sentences. later remove the stop words, build a similarity matrix then generate the rank based on matrix. then picks the top n sentences parse the summary.


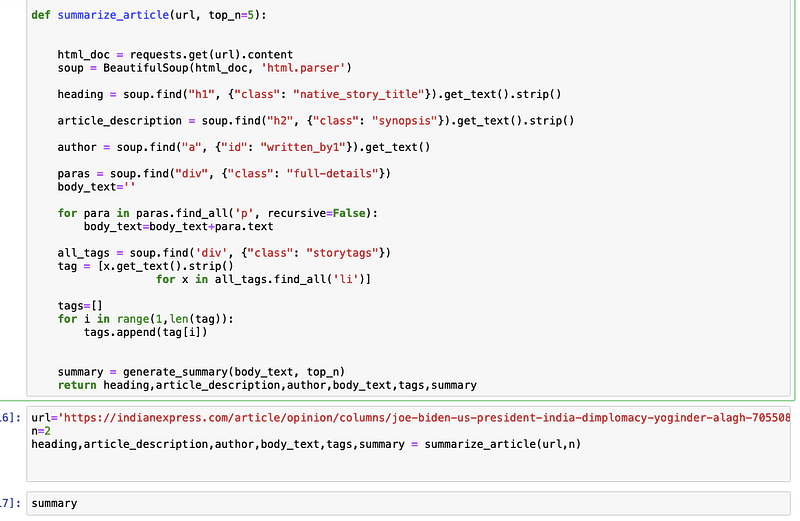
At last, combined the scraping code with the Summarization code made into the function so we can give input as URL and pick top n sentences. such way it goes into respective functions and execute and gives the output as a summary of that particular link.







