
How to ensure idempotence

Definition of idempotency.
The concept of idempotence comes from mathematics, which means that the results of N transformations and 1 transformation on the data source are the same.
In the project, idempotence is used to indicate that the results of one request or multiple requests initiated by the user for the same operation are consistent, and there will be no side effects due to multiple clicks.
- Idempotence includes side effects on resources when the first request is made, but subsequent requests will no longer have side effects on resources.
- Idempotency focuses on whether subsequent multiple requests have side effects on resources, not on the results.
- Problems such as network timeouts are not in the scope of idempotency.
- Idempotency is a kind of commitment of system services to the outside world, rather than realization. It promises that as long as the call interface is successful, the impact of multiple external calls on the system is consistent.
- A service declared as idempotent will assume that external call failures are normal, and there must be retries after failure.
Scenes to be used.
During business development, you may encounter a situation where the request cannot be received due to network turbulence, which triggers the retry mechanism, or the front-end jitter causes the form to be submitted repeatedly.
For example, in the transaction system, the shopping request submitted by the user has been correctly processed by the server, but the return result of the server is lost due to reasons such as the network so the client cannot know the processing result.
If it is on a web page, some inappropriate design may make the user think that the last operation failed, and then refresh the page, which causes the deduction to be called twice, and the account is also debited once more.
At this point, an idempotent interface needs to be introduced.
Let’s take MySQL as an example. Only the third scenario requires developers to use other strategies to ensure idempotency.
-- No matter how many times it is executed, it will not change the state, so it is naturally idempotent.
SELECT col1 FROM tab1 WHER col2=2;
-- No matter how many times the execution is successful, the state is consistent, so it is also an idempotent operation.
UPDATE tab1 SET col1=1 WHERE col2=2;
-- The result of each execution will change, which is not idempotent.
UPDATE tab1 SET col1=col1+1 WHERE col2=2;Tip: The difference between repeated submission and idempotency.
- Repeated submission refers to artificially performing multiple operations when the first request has been successful, causing services that do not meet the idempotent requirements to change their status multiple times.
- Idempotent is more used when the first request does not know the result (such as a timeout) or fails abnormally, and initiates multiple requests. The purpose is to confirm the success of the first request multiple times, but it will not fail due to multiple requests There are multiple state changes.
Some Thoughts on Idempotency.
The introduction of idempotence will make the logic of the server more complicated, and services that satisfy idempotence need to include at least two points in the logic.
- First, query the last execution status, if not, it is considered the first request.
- Ensure the logic of anti-duplicate submission before the business logic of changing the state of the service.
Idempotency can simplify the logic processing of the client, but it increases the logic and cost of the service provider. Therefore, whether to use it or not needs to be analyzed according to specific scenarios. Therefore, except for special business requirements, try not to provide idempotent interfaces.
- Additional business logic for controlling idempotence is added, which complicates business functions.
- Changing the function of parallel execution to serial execution reduces execution efficiency.
Realization of idempotency.
# 1. Front-end settings.
The most typical operation is that after the user clicks the submit button, we can set the button to be unavailable or hidden.
The front-end restriction is relatively simple, but there is a fatal mistake. If a knowledgeable user repeatedly submits a request by simulating a web page request, the front-end restriction is bypassed.
# 2. Unique index.
The simplest and most direct way to prevent multiple insertions of orders is to create a unique index, and then the statement may be slightly different when inserting.
But the purpose is to ensure that there is only one identical record in the database.
- Solution 1: Add a unique index to the database, and if
DuplicateKeyExceptionis caught during execution, you will understand that it is caused by repeated insertion, and you can continue to execute the business. - Solution 2: Use MySQL’s built-in keyword
ON DUPLICATE KEY UPDATEto implement the operation of inserting if it does not exist, and updating if it exists. This keyword will not delete the original record. - Solution 3: Use the
replace intokeyword. The bottom layer ofreplace intois to delete and then insert data, which will destroy the index and maintain the index again. It should be noted that there must be a primary key or a unique index to be effective, otherwisereplace intowill only add
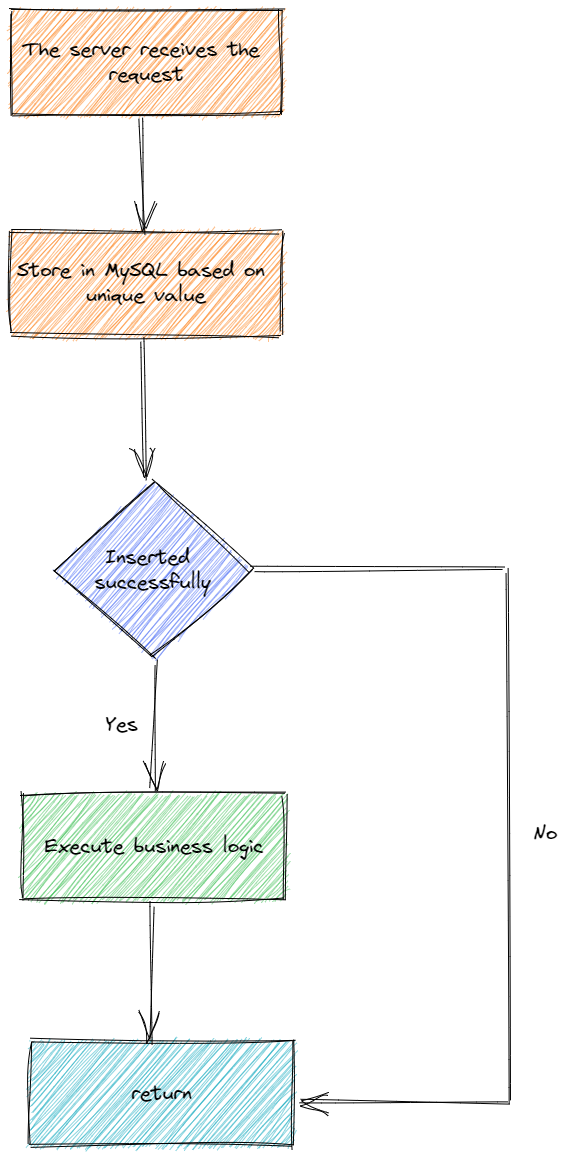
# 3. Create duplicate records.
This mechanism is also implemented according to the characteristics of MySQL's unique index, the general process is:
- The client first requests the server, and the server first stores the request information in a MySQL deduplication table. This table needs to establish a unique index or a primary key index based on a special field of this request.
- Determine whether the insertion is successful, and if the insertion is successful, continue to make subsequent business requests. If the insertion fails, it means that the current request has already been executed.
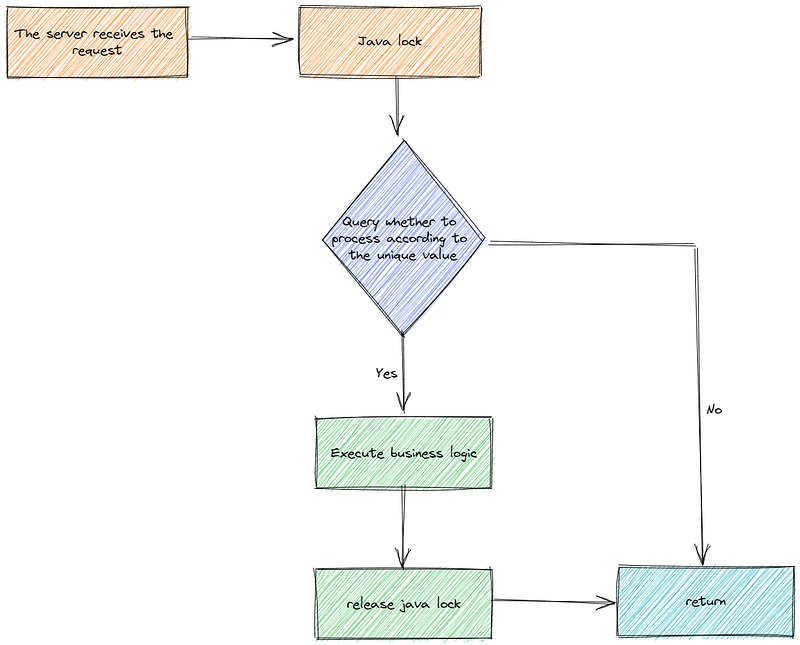
# 4. Pessimistic lock.
You can use the syn or lock that comes with Java to achieve idempotency.
The core point is to switch important execution parts from parallel to serial.
The disadvantage is that this lock cannot be used in distributed scenarios because it is across JVM! At this time, distributed locks need to be introduced.
Another implementation is to rely on MySQL’s built-in for update to operate the database to achieve serialization. The focus here is on for update.
- When thread A executes
for update, the data will be locked on the current record. When other threads execute this line of code, they will wait for thread A to release the lock before acquiring the lock and continuing the subsequent operations. - When the transaction is submitted, the lock acquired by
for updatewill be released automatically.
The disadvantage of this mode is that if the business processing is time-consuming and concurrent, the subsequent threads will be in a waiting state for a long time, occupying a lot of threads, and making these threads in an invalid waiting state.
However, the number of threads in web services is generally limited. If a large number of threads are in a waiting state due to acquiring for update locks, it is not conducive to the concurrent operation of the system.
# 5. Optimistic lock.
You can add a version field to each row of data, using the current read and update operations that come with MySQL.
When updating data, first query to obtain the corresponding version number, then try the update operation, and check whether it is a repeated submission according to whether the return value is 0.
// Suppose version = 100
select version from user where id = 123;
update user set account = account + 1, version = version + 1
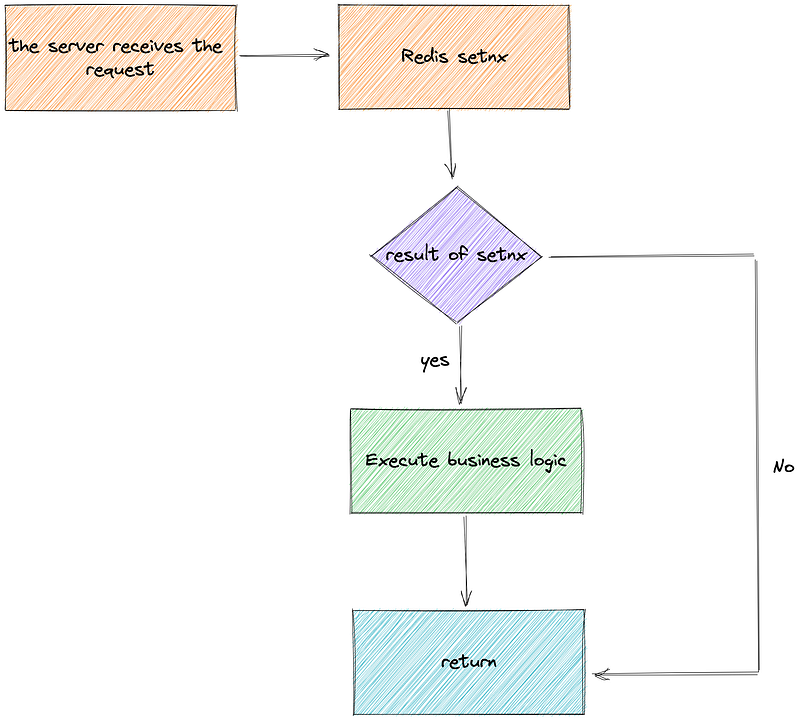
where id = 123 and version = 100;# 6. Distributed lock.
You can use the setnx operation in Redis to set the idempotence guarantee barrier in the distributed lock.
If setnx succeeds, it means that this is the first time to insert data, just continue to execute the SQL statement.
If setnx fails, it has already been executed.
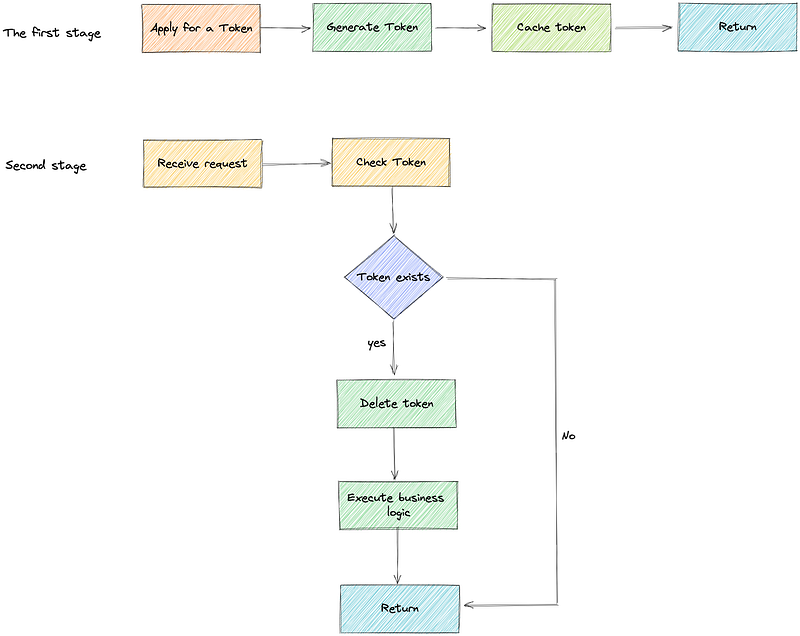
# 7. Use Token.
This method is divided into two stages: applying for tokens and consuming tokens.
The first stage: Before the user makes a request, it is necessary to initiate a Token request to the system according to the user information, and the system saves the Token in the Redis cache for consumption in the second stage.
The second stage: take the applied Token to initiate a request, the system will check whether the Token exists in Redis, if it exists, it means that the request is initiated for the first time, delete the Token in the cache and start business logic processing, if it does not exist in the cache, it means Repeat request.
In fact, the Token here can be regarded as a token, and the system confirms the uniqueness of the insertion based on the Token.
The disadvantage of the Token mode is that it requires two interactions between systems, and the process is more complicated than the above method.
If you like such stories and want to support me, please give me a clap.
Your support is very important to me, thank you.