
Part 2: How to create EMR cluster with Apache Spark and Apache Zeppelin

This is part-2 of the blog series — How to analyze Kaggle data with Apache Spark and Zeppelin. In the first part we saw how to copy Kaggle data to Amazon S3. We would now like to analyze our data on EMR. I’m choosing Spark and Zeppelin for this task.
What is EMR ?
Amazon EMR provides a managed Hadoop framework that makes it easy, fast, and cost-effective to process vast amounts of data across dynamically scalable Amazon EC2 instances. You can also run other popular distributed frameworks such as Apache Spark, HBase, Presto, and Flink in Amazon EMR, and interact with data in other AWS data stores such as Amazon S3 and Amazon DynamoDB.
Learn more about Amazon EMR here.
What is Apache Spark ?
Apache Spark is a unified analytics engine for large-scale data processing. Apache Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
Learn more about Apache Spark here.
What is Apache Zeppelin ?
Apache Zeppelin interpreter concept allows any language/data-processing-backend to be plugged into Zeppelin. Currently Apache Zeppelin supports many interpreters such as Apache Spark, Python, JDBC, Markdown and Shell. Especially, Apache Zeppelin provides built-in Apache Spark integration. You don’t need to build a separate module, plugin or library for it.
Learn more about Apache Zeppelin here.
Steps to create EMR Cluster
Login to AWS web console
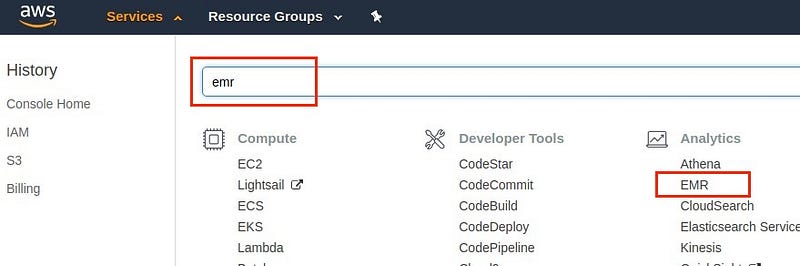
Go to Amazon web console and search for EMR.
Create EMR cluster

Go to advanced option

After creating cluster, we have to go to advanced setting.
Software configuration
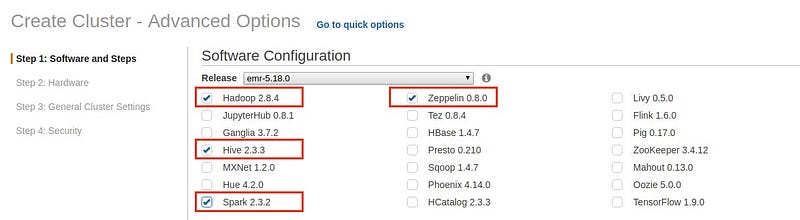
In advanced setting, we have to choose software on which we will work.
Hardware
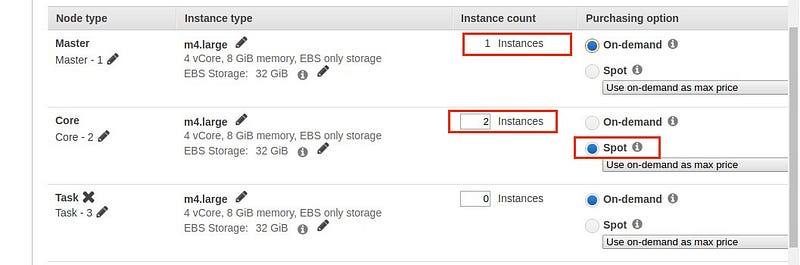
After setting Software configuration, we have to choose node i.e; master and core depending on purchasing option.
Note : I’m using spot purchasing option for core node. Spot nodes use bidding and are much cheaper than on-demand nodes.
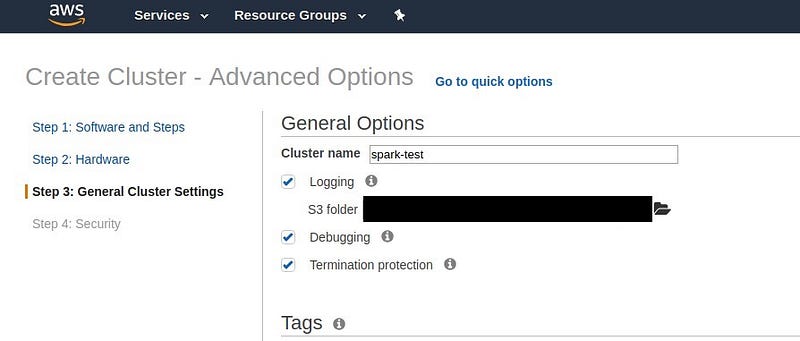
General cluster settings
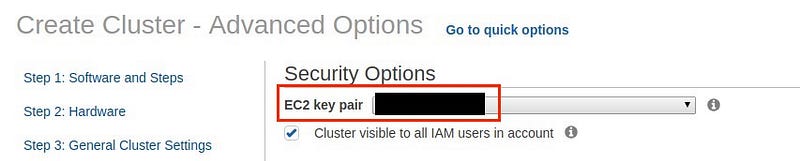
Security
In this step, we have to provide the key-pair to login into our EMR cluster. It’s very important that this key-pair must be downloaded in local system else we would not be allowed to login to our EMR cluster.
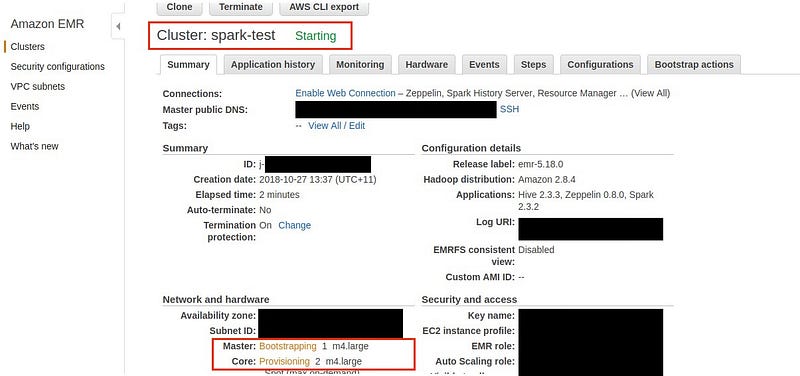
We can now see our cluster will start in a few minutes.
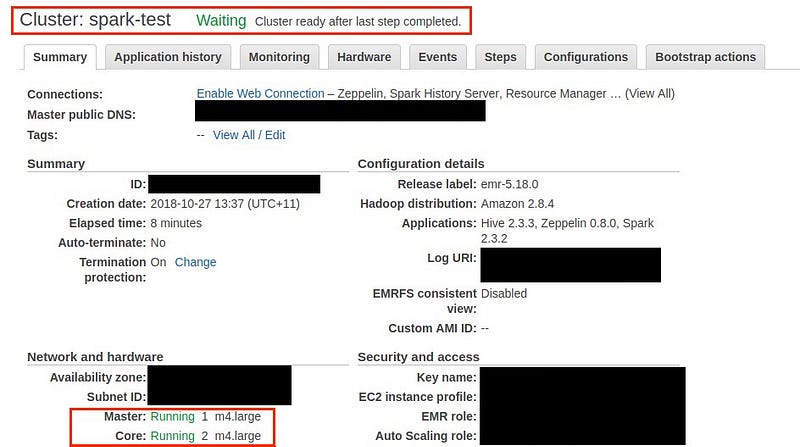
Now, finally our cluster is ready to use.
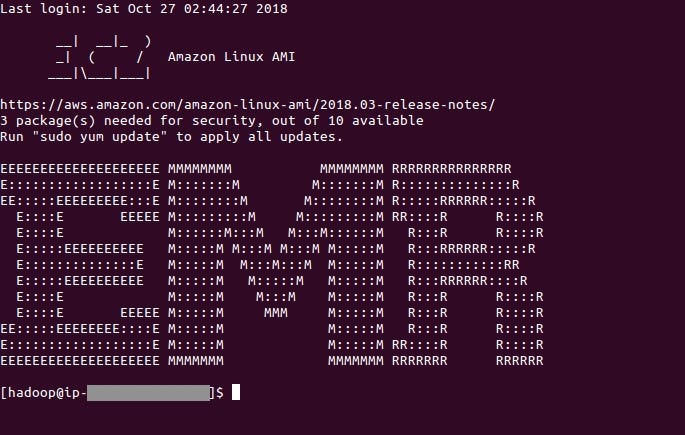
Login to EMR cluster
Now we can login our cluster via terminal.
ssh -i <path/to/ssh-key.pem> hadoop@<ip address of master node>
Note: You can get the ip address of the master node from the AWS web console in the hardware section.
Also, Note: If you get permission denied, it might be worth checking the permission of the pem file. The permission level should be 400 for the pem file. You can use below command to fix the permissions.
chmod 400<path/to/ssh-key.pem>

Use Hive and Spark on our cluster


Finally we are ready to use our cluster via spark/ hive.
Access Zeppelin
Now lets access Zeppelin via browser. The list of all the EMR web interfaces can be found here — EMR web interfaces.
So we can access Zeppelin at –
http://<master-ip-address>:8890/The master IP address can be found from the EMR web interface:
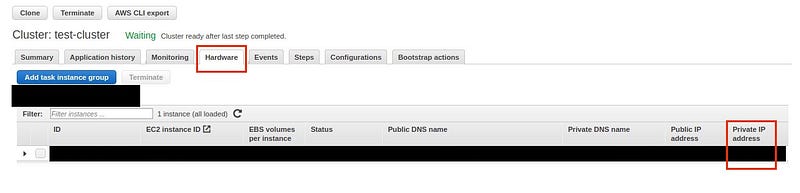
If the page doesn’t load up, or, you’re having issues with accessing Zeppelin via the web interface, we would need to open up a tunnel to the EMR cluster. Please refer to this blog post to tunnel into the EMR cluster.
If you tunnel in, you would have to use this command for ssh’ing into the cluster:
ssh -D 9999 -i </path/to/ssh-key.pem> hadoop@<ip address of master node>
You should now be able to access Zeppelin via your browser at
http://<master-ip-address>:8890/
Thats all for this post. In the next part we will create tables to analyze Kaggle dataset. Hope this post was helpful.
Cheers.
Originally published at confusedcoders.com on October 28, 2018.