
How to code Temporal Distribution Characterization (TDC) for time series?
There is no need to express the necessity of forecasting time series data by deep learning methods. I did provide an article about how we can handle the variations in statistical features (particularly, distribution perspective), which can lead us to a disaster. The model proposed is named AdaRNN, including two main initiatives, TDC and TDM. This article is going to illustrate TDC in detail.

I’m not gonna speak about everything from scratch, if you want, you can check my previous article, “Adaptive Learning for Time Series Forecasting”. Let’s go through TDC:
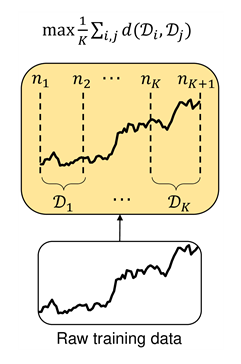
Figure 1 shows the architectural view of using TDC, it separates the dataset into intervals with the most possible diversity. This makes the model robust on distribution variations. The main point of TDC is maximizing the entropy (Equation 1, objective), as you can see in Figure 1 and Equation 1.
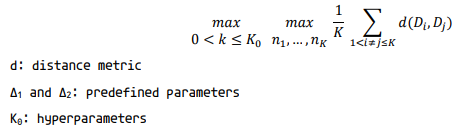
In Equation 1, we need to make the borders for Di not too large or not too small because it can be led to a failure of capturing the information out of the data.
In Eq. 1, we have a distance metric which can be any distance function (Cosine, Maximum Mean Discrepancy, Deep Correlation Alignment, etc). However, for this article, I am going to use Deep Correlation Alignment (CORAL) as our distribution distance function. Its formula can be seen in Eq. 2: ( For more information you can read the paper: Deep CORAL: Correlation Alignment for Deep Domain Adaptation)

Thus, equation 1 will be transformed into Equation 3:
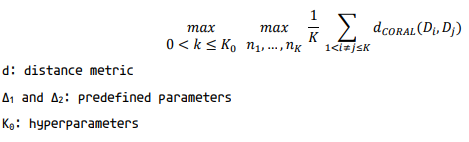
Please note that you can other distance metrics. And, the equation 3 (eq 1 generally) can be solved with dynamic programming (DP).
- K is a random value in {2, 3, 5, 7, 1}, by which we select each period (as you can see in Figure 1) with the size of nj. (you can use any optimization method, here it is a greedy strategy.)
- If the period starts with A and ends with B, we have duration [start, end]. Firstly, we contemplate K equals 2 by selecting a separating point (C) from nine candidates (how?? by maximizing the distance between S_AC and S_CB).
- When we calculated C, we give k, the value of 3, and so on.
- The results of the main research showed that there is an optimal value of K to have the best performance (it is not very large or very small).
So now, let’s have a look TDC from a code perspective: 😉
It might be interesting how is the performance of using various distances in TDC. Well, in the main research, researchers provided their results on different distance functions.
- Firstly, they set K = 2 for TDC and then compared it with one random domain split and the opposite domain split.

As you can see, the results of the paper’s TDC show better results in RMSE and MAE for the most distance functions.
That was all. 😉This was used in AdaRNN: Adaptive Learning and Forecasting of Time Series, to train their model. Also, you can read my previous article in Adaptive Learning for Time Series Forecasting. I am going to write another article about implementing AdaRNN in PytorchLightning. If you find any errors in my articles or if there was anything to say, you can easily reach out to me on LinkedIn.