
How to choose a NoSQL database for your application
NoSQL stands for ‘not only SQL’, and represents a group of non-relational database categories that can handle various data types, including unstructured and semi-structured formats. NoSQL databases are often used in conjunction with SQL databases and are designed to handle large volumes of distributed data. However, NoSQL databases have a number of differences when compared with their relational counterparts. Unlike traditional relational databases, which organize and store data in tabular structures with predefined schemas, NoSQL databases offer a more flexible and scalable data model. Because NoSQL databases prioritize features like horizontal scalability, fault tolerance, and flexible data models, they are often a good choice for applications where requirements can evolve over time.
NoSQL databases emerged in response to the increasing need for handling large volumes of diverse and unstructured data and the demand for high scalability and performance in modern applications. Due to the fact that they can efficiently scale across multiple servers or clusters, NoSQL databases can easily distribute data and workload across nodes, allowing for improved performance and handling of high data volumes. In addition, they often employ techniques like in-memory caching, data denormalisation, and parallel processing to further optimise performance.
NoSQL databases are found in applications in numerous domains, including web applications, big data analytics, content management systems, real-time applications, IoT, and more. They provide a flexible and scalable alternative to traditional relational databases, allowing developers to choose the most appropriate data model and scalability approach based on their specific requirements.
However, NoSQL databases come in a variety of types, with each providing unique ways to organize and query data. The main varieties of NoSQL databases are:
- Key-Value Store
- Document Store
- Wide-column
- Graph
- Search Engine
Let's take a closer look at each of these.
Key-Value Store
A Key-Value database (also known as a Key-Value Store) is a type of NoSQL database that is designed to store and retrieve data in a simple key-value format. Each key is unique and the corresponding value can be of any data type, including strings, arrays, hashes or even more complex objects, such as JSON files.
An important characteristic of a Key-Value database is high scalability. Key-Value databases can easily distribute data across multiple nodes or servers, where each node is responsible for storing a subset of the data. This allows for parallel processing and increased storage capacity as more nodes are added to the cluster. Data can be divided into partitions or shards based on certain criteria, such as the key range or a hashing algorithm. Because each node is responsible for a specific range of keys or shards, workloads can easily be evenly distributed evenly across a cluster to maximise performance. This sharding is also a benefit to fault tolerance as it allows for failover procedures, thus helping to prevent data loss in case of hardware or network failures.
Furthermore, this scalability can occur in response to fluctuating demand in an automated fashion. As the data or traffic volume to your app increases, additional nodes can be automatically added to the cluster to distribute the load and provide additional storage capacity. This elastic scaling allows for the seamless expansion of resources as needed without disrupting the availability or performance of the system.
Another benefit of Key-Value stores is the ability to easily employ caching techniques to improve performance. By caching frequently accessed or computationally expensive data in memory, key-value stores reduce the need to fetch data from slower primary data sources, improving response times and reducing the load on the underlying storage.
The flexibility of Key-value Stores can also be an important appeal. Key-value databases don’t enforce a fixed schema, which means you can store different types of data within the same database without the need for migrations or schema changes. This flexibility is useful in scenarios where data structures may evolve or differ across different entities or versions of an application.
Common use cases of Key-Value Databases
- Online Shopping Carts
- Storing application user sessions
- Game session management
- Caching API replies
- Real-Time Analytics and Leaderboards
Some popular examples of Key-Value databases include Redis, Apache Cassandra, Amazon DynamoDB, and Riak.
Document Store
A Document Store is designed to store formats such as as JSON (JavaScript Object Notation), BSON (Binary JSON), or XML (eXtensible Markup Language). Each record is stored as a single document, with multiple documents forming a ‘collection’. Within a database, you can have multiple collections. Each document can have its own structure so there is no need to define a fixed schema upfront. This makes it easy to handle varying and evolving data structures commonly found in web applications, content management systems, and other modern applications. Document stores provide fast read and write operations by storing related data in a single document, reducing the need for complex joins across multiple tables and can scale horizontally via sharding. The biggest difference between Document Stores and Key-Value stores is in how the data can be queried. Key-value stores offer simple operations for retrieving, storing, and deleting data based on the key. They usually provide basic operations like GET, PUT, and DELETE. Querying is limited to exact key matches and range scans based on the key ordering. Document stores on the other hand, provide more advanced querying capabilities, allowing developers to query based on the contents of the document, including nested fields and values. They typically support a rich query language or API that allows for filtering, sorting, and searching within the document structure.
Another key difference between Document Stores and Key-Value stores is the ability to define relationships between data points. Key-value stores do not have built-in support for expressing relationships between data items. Relationships, if required, need to be managed and enforced at the application level. In contrast, Document stores can naturally represent and store relationships between documents. They often support features like document embedding and referencing, which enable developers to model relationships within the document structure itself.
Common use-cases of Document Databases
- Content management systems
- Real-time analytics
- Catalog management
- Applications with flexible or evolving data models
Popular examples of Document stores include MongoDB, Couchbase, and Amazon DocumentDB (Noting that DynamoDB also provides JSON support).
Wide-Column Databases
Wide-Column databases store data in flexible columns instead of rows. They use multi-dimensional mapping to provide highly-scalable data storage that can handle ambiguous or complex data types. Wide-Column Databases provide schema flexibility by allowing different rows within the same table to have different sets of columns:
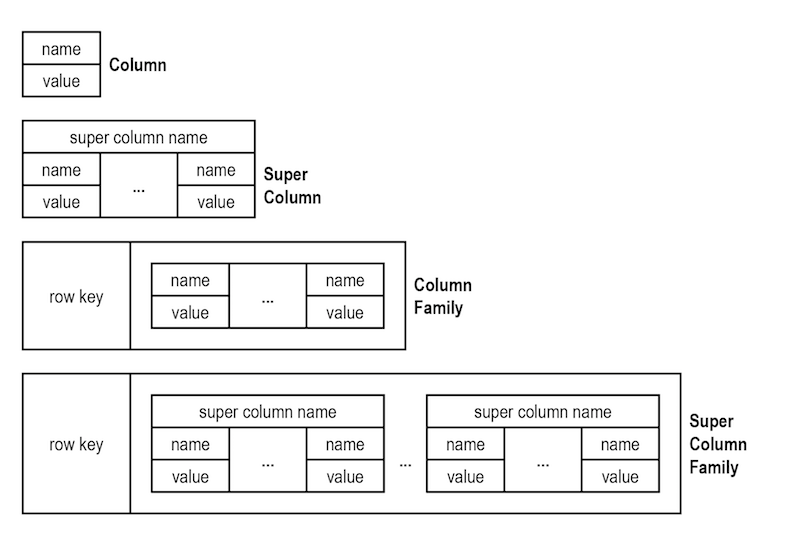
This makes it easier to handle varying and evolving data structures commonly found in analytical applications.
Wide-Column Databases can handle large volumes of data and execute complex queries efficiently due to columnar storage format. Since similar data types are stored together in each column, compression algorithms can be applied more effectively, reducing storage requirements and improving query performance. Furthermore, by selectively retrieving only the required columns, wide-column databases minimise disk I/O and improve query response times. This columnar storage format is particularly beneficial for analytical workloads where queries often involve aggregations, filtering, and selecting specific columns.
Wide-column databases are typically designed to be distributed across multiple nodes in a cluster. This allows them to scale horizontally and handle high data volumes by distributing the data across the cluster and parallelizing query processing.
Common use-cases of Wide-Column Databases
- Real time data analytics
- Time Series data
- Trading data
- Internet of Things (IoT)
Examples of wide-column databases include Apache Cassandra, Apache HBase, and ScyllaDB
Graph Databases
Graph databases are designed to store and navigate relationships between data. In a Graph Database, relationships are as important as the data itself. Data entities are stored as nodes and relationships are stored as edges. Information associated to nodes are properties.
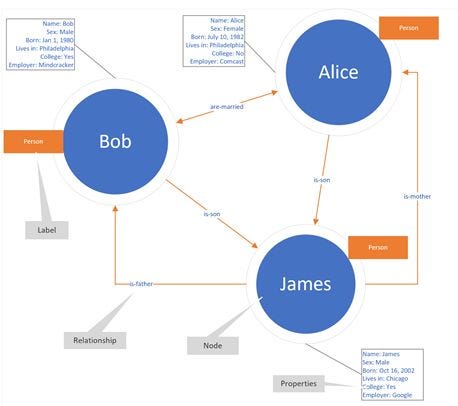
Queries are often fast due to relationships not being calculated during query time, but instead stored in the database. This makes Graph Databases efficient at complex queries, independent of total data size. In addition, some Graph databases provide a specialized query language, such as Cypher (Neo4j) or Gremlin (Apache TinkerPop), which allow for efficient querying of the graph structure. These languages enable you to retrieve data by specifying patterns of nodes and relationships.
As with other NoSQL databases, Graph databases provide schema flexibility, where the structure of the graph can evolve over time without requiring a predefined schema.
Common use-cases of Graph Databases
- Recommendation Engines
- Fraud detection
- Social Networks
- Logistic networks
- Network Analysis
- Metadata Management
- Natural Language processing
Examples of Graph databases include Neo4j, Amazon Neptune and JanusGraph (also available in Microsoft Azure Cosmos DB)
Search Engines Databases
Search Engine datases combine elements of both NoSQL databases and search engine functionality to efficiently store and retrieve large amounts of unstructured or semi-structured data, particularly text or multimedia content, and provide advanced search capabilities over this data.
A Search engine database incorporates features such as full-text search, faceted search, ranking algorithms, and relevance scoring to enable powerful search capabilities. These databases employ indexing techniques and search algorithms optimized for efficient retrieval and querying of data.
Common use-cases of Graph Databases
- Social media analytics
- Full-text search
- Content management systems
- Auto-suggestion / auto-completion
- Textual data-mining
Popular examples of NoSQL search engine databases include Apache Lucene, Elasticsearch, Apache Solr, and MongoDB with its full-text search capabilities.
Questions you should ask when choosing a NoSQL database
What are the primary access patterns for my data?
If your application primarily requires simple get/set operations based on keys, a Key-Value store may be a good fit. However, if you have complex querying requirements that involve searching, filtering, and sorting within the record structure, you might want to consider a Document Store. Furthermore, Document stores often provide rich query languages and indexing capabilities for efficient document-based querying. If your access patterns are likely to support large-scale analytical workloads involving aggregations and filtering, a Wide-Column database may be the optimal choice. If you need to users to have natural language search capabilities, a Search Engine database would be the best option.
Do I require high scalability?
If your application needs to handle large amounts of data and unpredictable heavy traffic then Key-Value, Document Stores and Wide-column all offer flexible and automated scalability. However, Key-Value Stores are often touted as the leaders in offering scalability with ease, due to their native distributed caching mechanisms and in-memory storage options.
How important are relationships between my data entities?
If your application heavily relies on complex relationships or requires advanced querying based on those relationships, you might need to consider a Graph Database or a Document Store. Document stores can handle relationships by embedding related data within a document or by using references to link documents, providing more natural modeling for certain types of relationships. Graph Databases excel at handling relationships as the relationship is embedded in the database, rather than calculated at runtime.
Is speed of data loading the most important factor?
If your application has a high volume of write operations and requires low-latency writes, Wide-column and Key-Value databases excel in handling write-intensive workloads. They are designed to handle massive write throughput, making them suitable for use cases such as event logging, real-time analytics, and systems with frequent data updates.
Is speed of data retrieval the most important factor?
If yes, Key-Value stores are the way to go if your data’s structure allows.
Does the structure of my data lend itself to a particular database?
Consider the nature of your data, can it be effectively represented as Key-Value pairs? If your data has complex relationships or requires nested structures that you need to query, Document Stores or Graph databases may be more appropriate, whereas Wide-Column databases are particularly well suited for Time-series data. Do you have large volumes of textual data that you need to query where a Search Engine database would be of benefit?
Is the flexibility of a schema-less database important for my use case?
If you think your data structures are likely to evolve frequently or differ across entities, a Key-Value store can accommodate those changes without requiring schema modifications. However, a Document store is even more flexible, so if you anticipate frequent changes or evolution in your data model, then a Document Store is potentially the best choice.