
How To Calculate the Mean and Standard Deviation — Normalizing Datasets in Pytorch
Neural networks converge much faster if the input data is normalized. Learn how you can calculate the mean and standard deviation of your own dataset.

Why normalization allows faster convergence
The normalization of a dataset is mostly seen as a rather mundane task, although it strongly influences the performance of a neural network. With unnormalized data, numerical ranges of features may vary strongly. Take for example a machine learning application where housing prices are predicted from several inputs (surface area, age, …). Surface areas will typically range from 100 to 500m², while the age is more likely between 0 and 25. If this raw data is inputted in our machine learning model, slow convergence will occur.
As illustrated left, the steepest gradient is searched, which is somewhat in the correct direction but also possesses quite a large oscillation part. This can be explained by reasoning about the learning rate. A relatively large learning rate is required for the surface area feature since its range is quite large. However, this large learning rate is too large for the age. The optimizer overshoots each step, which results in oscillation and hence slow convergence.
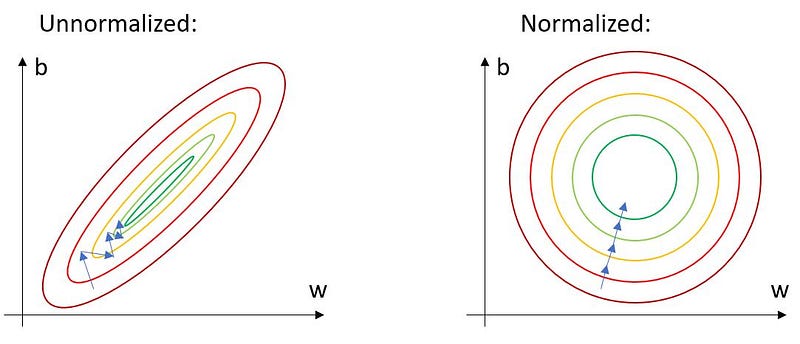
The data can be normalized by subtracting the mean (µ) of each feature and a division by the standard deviation (σ). This way, each feature has a mean of 0 and a standard deviation of 1. This results in faster convergence.
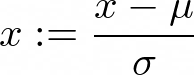
In machine vision, each image channel is normalized this way.
Calculate the mean and standard deviation of your dataset
First, some imports are required.
I will use the CIFAR dataset with its color images as an example. However, the same code works on the MNIST dataset with grayscale images as well.
The training examples are downloaded and transformed to tensors, after which the loader fetches batches of 64 images.
The mean has to be calculated over all the images, their height, and their width, however, not over the channels. In the case of colored images, an output tensor of size 3 is expected.
The standard deviation can be calculated with the following formula:
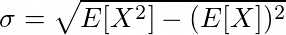
E[X²] represents the mean of the squared data, while (E[X])² represents the square of the mean of the data.
Finally, the mean and standard deviation are calculated for the CIFAR dataset.
Mean: tensor([0.4914, 0.4822, 0.4465])
Standard deviation: tensor([0.2471, 0.2435, 0.2616])Integrate the normalization in your Pytorch pipeline
The dataloader has to incorporate these normalization values in order to use them in the training process. Therefore, besides the ToTensor() transform, normalization with the obtained values follows.
Note that since the network is trained on normalized images, every image (be it while validating or inferencing) must be normalized with the same obtained values.

Conclusion
Data normalization is an important step in the training process of a neural network. By normalizing the data to a uniform mean of 0 and a standard deviation of 1, faster convergence is achieved.
If you have any questions, please don’t hesitate to contact me!





