
How to calculate the entropy of an entire language
Python implementation of calculating the entropy of english language using deep learning.
Table of contents
- Problem Statement
- Entropy
- Entropy of English (theory)
- Character level entropy (code)
- word level entropy(code)
- Shannon’s approach(theory+code)
- Limitations of Shannon’s approach
- Interesting excercises
- References
Problem Statement
Calculate the entropy of english language.
The above statement is inherently vague because —
- Depending on the source of the text we can get different results for entropy.
- There is also a question around using characters, morphemes, words or sentences to calculate the entropy of the language. They might return different results.
We’ll explore these options below.
Entropy
There are many posts on the definition of entropy so I’ll just briefly describe it here. It is the measure of average information content of a variable. It can also be thought of as the minimum number of bits needed to encode a sequence. As an example,
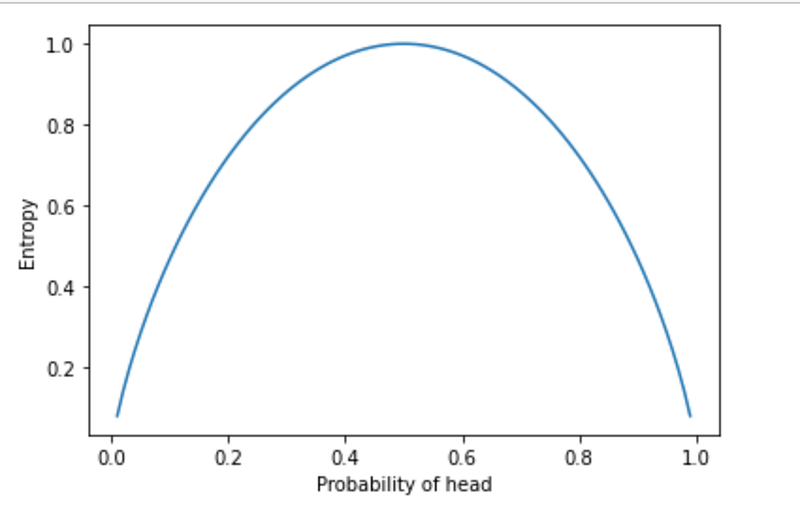
Consider a coin with probability of head = p
Entropy of a Single toss = -p log(p) - (1-p)log(1-p)Plotting this below, we can see that the entropy is maximum when p=0.5(highest uncertainty about the outcome being head or tails) while it is lowest at p=1 and p=0 (certain about the outcome). This means the higher uncertainty about the outcome of a variable implies higher entropy.
Entropy of English
This can be defined as the average number of bits per symbol required to encode an entire sequence of english in binary digits. The symbol can be characters, morphemes or words etc.
A language is a constrained sequence of symbols i.e there is a lot of redundancy in it e.g it is very likely that U follows Q or H follow T etc. There is an element of predictability of the next symbol given the past symbols aka language models. e.g
Y__ C_N PR_D_CT TH_S S_Q__NC_ __SI_LY.This shows that english sequences are predictable given past information. Key thing here is that as far as information is considered, this text with blanks contain the same amount of information as the original text with no blanks because we’re able to get back the full sequence from this reduced sequence. There is no loss of information here. The reduced sequence can be thought of as a lossless encoding of the original sequence. We’ll make use of this insight later.
One way to calculate the entropy of english is by a series of approximations based on N-grams i.e conditional entropy of the sequence given the past. As we keep increasing N, we should converge to the actual entropy of the entire language but that requires an infinite number of samples to estimate the probabilities of the sequences and is therefore intractable for large N.
We’ll make use of equation 1 above to calculate the N-gram entropies.
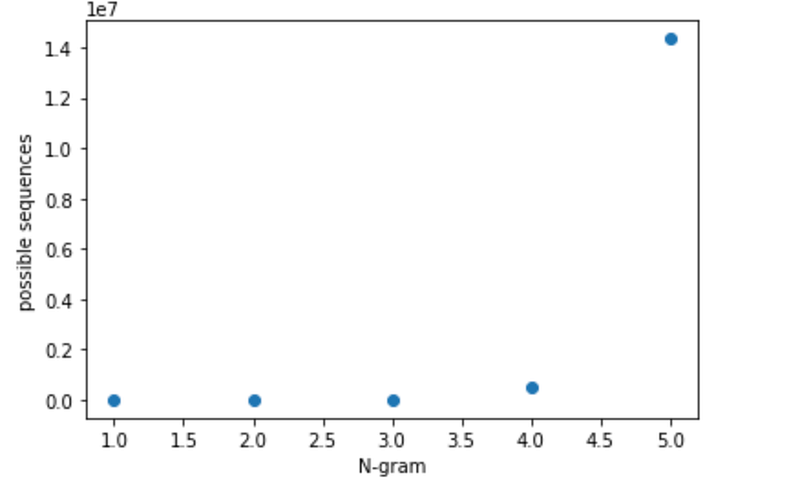
The small range correlations can be captured by few gram entropy but to capture long range correlation we need to go to higher N value. The plot below shows the number of possible patterns as we increase N and remember we need at least 100s of examples to estimate the probability of each such sequence. Therefore, this problem becomes intractable or inaccurate very fast i.e around 4 grams. Therefore, we’ll only calculate the n-gram based entropy till 3-gram and then move to another approach to find an upper bound to the entropy.
Character level entropy
In this approach we’ll treat english language as a sequence of random variables which can take 27 character (alphabets + whitespace) values.
In our example, we’ll be using project Gutenberg novels in nltk. The text size is ~11 million characters. Let’s define some helper functions to preprocess the text,
Let’s calculate the entropy now —
We can see that the entropy drops significantly as we move from 0-gram to 3-gram. This is expected as higher n-grams capture more of the redundancy/structure in the language.
The reason for not calculating 4-gram or above entropy is because our data only has 11 million characters. For a 4-gram, there are 27**4 = 531441 possible sequences. Assuming that we need at least 100 example of each sequence to estimate the probability and all sequences are equally likely to appear in the text, we need ~50 million characters long text. Therefore, calculating n-grams beyond 3-gram is not a good idea. The plot below shows the number of possible sequences till 5 gram. We’ll need at least 100–500 times more examples to estimate the probability correctly.
As we keep increasing N by keeping the number of examples constant, we start getting bad estimate of the probability of the n-gram and thus the entropy start dropping towards 0 as in the end we’ll just have a single 11 million length text with probability 1 thus entropy =0.
Word level entropy
The same calculation as above can be extended to calculate word level entropy. The code for that is —
We get the entropy to be 9.72 bits/word or 2.32 bits/character. This is way lower than even the 3-gram character level entropy which is intuitive as the average number of characters per word is ~4.2 .
Better approach : Prediction+Compression
The previous N-gram based approaches are good first order approximations to the entropy of the language but fails for higher N due to the exponential number of examples needed to estimate correct probabilities. Thinking about the entropy in terms of the minimum number of bits required to encode a sequence into binary and relating it to lossless compression of the sequence, a more generic approach could be formed.
By definition, in lossless compression, we can’t do better than the entropy i.e it is the minimum number of bits required to encode. Therefore, if we can somehow compress english sequences in a lossless way and calculate the entropy of this compressed representation, it should be close to the entropy or at least form an upper bound on the true entropy of the language.
One way to do it is to use a language model. A language model gives the conditional probability of the next character given the previous characters. We’ll rank the predictions based on the conditional probability of each character occurring and then note down number of guesses required to predict the next character. If the same model is used for encoding as well as a decoding, this representation in terms of number of guesses, then this is a lossless compression. While decoding, all we’ll need to do is to choose the character with conditional probability rank equal to the number of guesses in the encoded text. The example below shows the encoding from alphabet to guess space. The second row is the number of guesses required to correctly predict the character in first row given the characters that occurred before it.
THIS IS SUCH AN AMAZING ARTICLE. --- original text
2121111142111121111111114211211. ---- Number of guesses requiredWe can see that towards the end of each word we get 1 compared to the beginning of the word. Also, we get more 1 as we get to know more characters that have occurred. While decoding, we can arrange the predictions in decreasing conditional probability and pick the guesses as the second row to get the characters back e.g 2nd ranked character for the first T and so on.
What we achieve by this approach is a transformation of labels i.e we’re transforming the 26 alphabet+1 whitespace basis to 1 to 27 guesses space.. The benefit of this transformation is that we end up with an unequal probability distribution of guesses as a language model is generally really good at next character prediction given high enough N. Therefore, instead of worrying about the complex linguistic rules and exponential number of examples needed to estimate the N-gram entropy, we can calculate the N-gram entropy by prompting this language model with N-1 gram and predicting the Nth character.
Shannon in his seminal paper argued that humans have a very good language model in their mind and used them for his next character prediction model. He got an entropy of 1.3 bits/character for 100-gram entropy.
As it takes time to ask people to rank their next character predictions over a large sample, I’m going to use a pretrained character level transformers model for this task. This is a pre-trained on 99 million characters so I’m assuming it is good at capturing the general statistics of the language. The model vocab is around 240 character token so i’ve reduced this to 27 characters post prediction as we’re only using 26 alphabets and 1 white space as our vocab.
We’ll use this model to calculate 100 and 500-gram entropy over a small sample.
Note : we can expect that the entropy captured by this model is going to be higher than the entropy that Shannon calculated as this model is not on par with humans so it’ll miss out on some of the redundancies in the language thus increasing the entropy.
Here’s the code to do that —
We get the 100-gram entropy to be 2 bits/character using 250 examples and 500-gram entropy as ~2 bits/character, which is quite higher than what Shannon calculated in 1950. This is expected as our model is way worse than humans. We can also see that the entropy has converged as we get the same result for both 100 and 500 gram. Repeating the same exercise with a better model or humans will return an entropy close to 1.3.
The entropy can also be used for evaluating how good the language models are in capturing redundancies in the language. If it is close to 1.3 bits/symbol, then quite good otherwise worse. This is just an estimate and in no way captures everything about the language i.e 1.3 bits/symbol doesn’t mean the language model has achieved human level understanding of the language but higher entropy definitely means its worse.
There are classical lossless compression algorithms present too e.g Lempel-Ziv-Welch algorithm. I thought it’d be cool to relate this to deep learning, hence the transfomer. :) In the end the idea is to compress the text sequence in a lossless way as much as possible and use that as an upper bound to the entropy since it is always an approximation unless we get the true probability distribution of a language which is not possible.
Limitations
- Number of examples is finite.
- N in N-gram is small and finite.
- The exact likelihood of the prediction is not taken in consideration i.e the conditional probability was discarded after determining the rank which ended up treating the large differences in probabilities to smaller differences. This limitation was addressed in this paper resulting in 1.34 bits/character entropy.
Interesting Exercises
The core idea behind this entropy calculation can be extended. It’d be cool to do these exercises to further understand the concept of entropy-
- Compare entropy of different languages. Finnish seems to have highest entropy.
- Entropy of an image.
- Entropy of speech.
- Entropy of the language to evaluate language models.
References
- Shannon, Claude E. “Prediction and entropy of printed English.” Bell system technical journal 30.1 (1951): 50–64.
- Cover, Thomas, and Roger King. “A convergent gambling estimate of the entropy of English.” IEEE Transactions on Information Theory 24.4 (1978): 413–421.





