
How to Build a Simple Movie Recommender System with Tags
A content-based approach to finding similar movies

Introduction
Let’s suppose you’re launching the next great subscription video-on-demand (SVOD) streaming service and you’ve secured the rights to stream all major movie titles released in the past 100 years. Congrats on this incredible feat!
Now that’s a lot of movies. Without some sort of recommender system, you’re concerned that users may be inundated over time with movies they don’t care about. This could drive customer churn which is the last thing you want!
So you decide to build a movie recommender system. Since your service is new, you don’t have enough data yet on what movies are being watched by which users. This is known as the cold start problem and it precludes you from recommending movies based only on the historical viewership of users.
Luckily, even without adequate viewership data we can still build a decent recommender system with movie metadata. That’s where MovieLens comes in. MovieLens provides a public dataset with keyword tags for each movie. These tags are quite informative. For example, check out the top community tags below for Good Will Hunting.

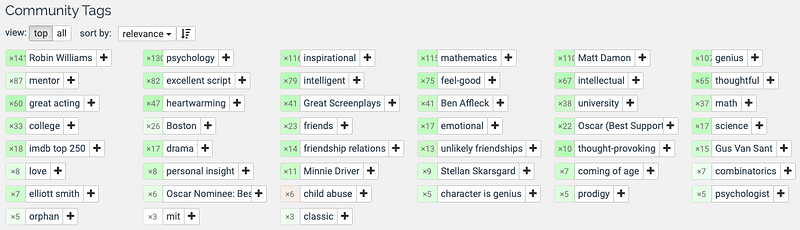
In the rest of this post, I’ll answer three business questions that are critical to building a simple content-based recommender system with tags from MovieLens:
- How many tags do we need for each movie?
- How do we use tags to measure the similarity between movies?
- How do we use tags to generate movie recommendations for a user?
Excerpt from wikipedia page on content-based recommender systems:
“Content-based filtering methods are based on a description of the item and a profile of the user’s preferences. These methods are best suited to situations where there is known data on an item (name, location, description, etc.), but not on the user. Content-based recommenders treat recommendation as a user-specific classification problem and learn a classifier for the user’s likes and dislikes based on product features.”
The code for this analysis can be found here along with the data and Conda environment YAML file for you to easily reproduce the results.
1) How many tags do we need for each movie?
There are about 10K unique movies and 1K unique tags in the MovieLens tags genome dataset. Each movie has a relevance score for every tag so that’s about 10M movie-tag pairs. The relevance score ranges from 0 to 1.
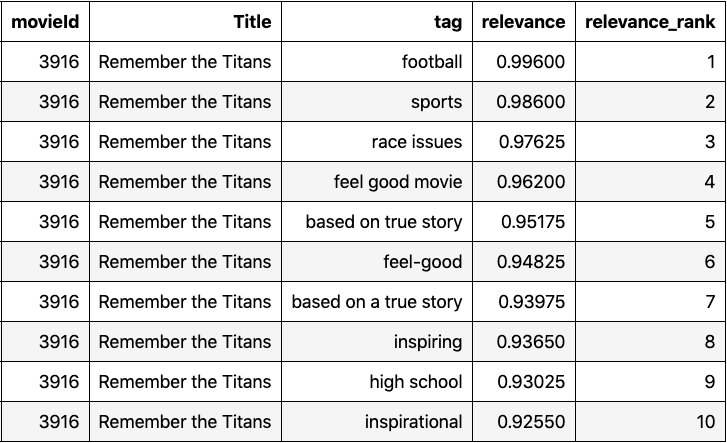
Not every tag is relevant for a movie so we need to only keep the most relevant tags. First, we can rank order the tags for each movie based on the relevance score. For example, below top 10 tags for Remember the Titans. Note that the relevance scores are well above 0.9 which indicate that they’re very relevant tags.
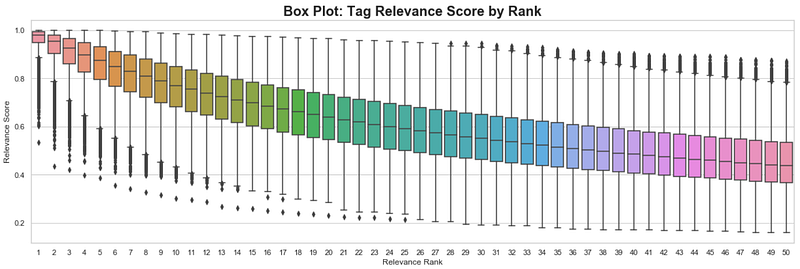
Next, we confirm in the chart below that higher ranked tags for a movie tend to have higher median relevance scores. Tags in the 1st rank for a movie have a median relevance score of almost 1. We can see that the median relevance score gradually decreases as we go down to the 50th rank.
To find the most relevant tags for a movie, we can keep the top N tags for a movie based on relevance score. Here, we need to pick N carefully. If N is small, we have very relevant but few tags. If N is large, we have many tags but a lot of them could be irrelevant.
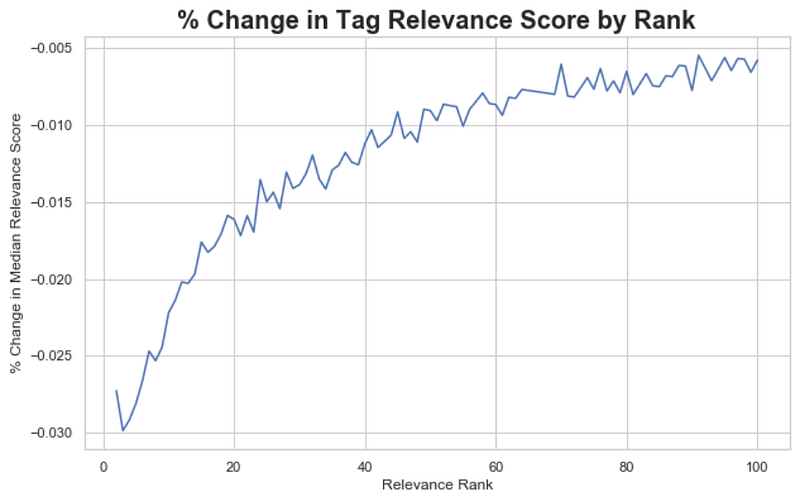
Chart below shows the percent change in median relevance score as we go from tags in the 1st to 100th rank. We see an inflection point around the 50th rank when the relevance score starts to become more stable. Thus, we can chose N = 50 as a reasonable number of tags to keep for each movie. Note that this is quite a simple “elbow method” styled approach which can be optimized later.
Now we can get the list of top 50 tags for each movie which we’ll use in the next sections. For example, below top 50 tags for Toy Story.

2) How do we use tags to measure the similarity between movies?
Before generating movie recommendations for a user, we need a way to measure the similarity between movies based on their top 50 tags. In content-based recommender systems, users will be recommended movies that are similar to movies they’ve already watched.
Here, I’ll demonstrate two ways of measuring similarity:
- Jaccard Index of two sets of movie tags
- Cosine Similarity of movie vectors (aka content embeddings) based on tags
Jaccard Index
The first approach with Jaccard Index measures the similarity between two sets A and B as the size of the intersection divided by the size of the union. When measuring the similarity between movies, we can compute this index for the two sets of movie tags.
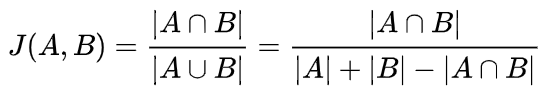
For example, let’s say we have three movies below and their top 3 tags:
- movie A tags = (action, space, friendship)
- movie B tags = (adventure, space, friendship)
- movie C tags = (romantic, comedy, coming-of-age)
Intuitively, we can see that movie A is more similar to B than C. This is because movies A and B share two tags (space, friendship) whereas movies A and C don’t share any tags.
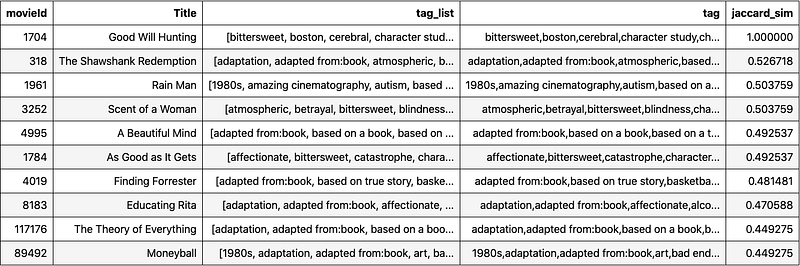
Below top 10 movies similar to Good Will Hunting based on Jaccard Index. For viewers of Good Will Hunting, these look like reasonable recommendations. Note that I included Good Will Hunting on the list to show that the Jaccard Index = 1 when comparing a movie with itself.
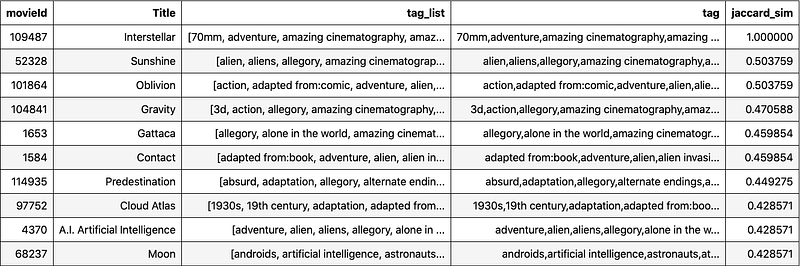
Below top 10 movies similar to Interstellar based on Jaccard Index. For viewers of Interstellar, these also look like reasonable recommendations.
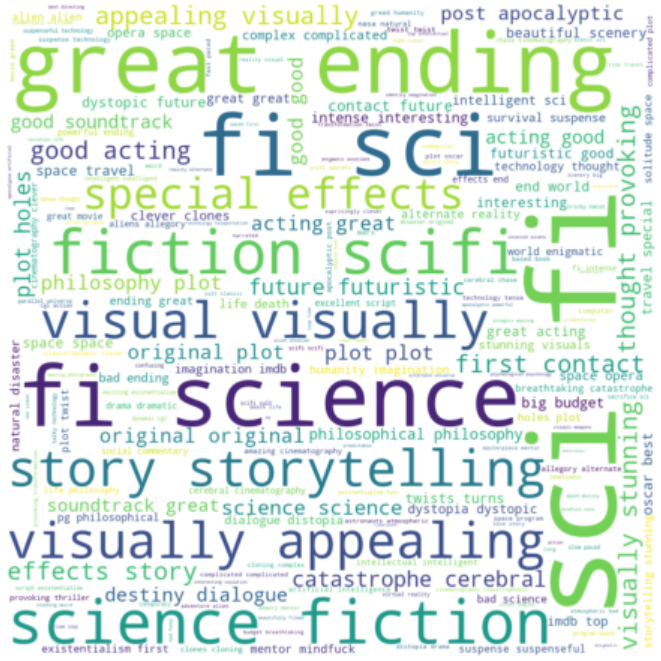
To further illustrate the effectiveness of Jaccard Index, see below word cloud based on tag frequency from movies similar to Interstellar. Here, we can see which tags are more prominent in the similarity calculation (e.g. science fiction, great ending, dystopic future, philosophical, cerebral).
Cosine Similarity of Movie Vectors (aka Content Embeddings)
The first approach with Jaccard Index helped us build an intuition about what it means to be similar with tags. The second approach here with cosine similarity is a bit more complex. It requires that we represent our movies as a vector. Here, a vector is just a set of numbers.
For example, we can represent the same movies before as a set of three real numbers:
- movie A = (1.1, 2.3, 5.1)
- movie B = (1.3, 2.1, 4.9)
- movie C = (5.1, 6.2, 1.1)
Intuitively, again we can see that movie A is more similar to B than C. This is because movies A and B have closer numbers in each dimension (e.g. 1.1 vs 1.3 in the first dimension).
To find a good vector representation of movies, I use the Doc2Vec (PV-DBOW) technique from this paper which takes a movie (document) and learns a mapping to a latent K dimensional vector space based on its tags (words in the document). I won’t go into the details here, but this is how we can represent movies as a vector based on tags.
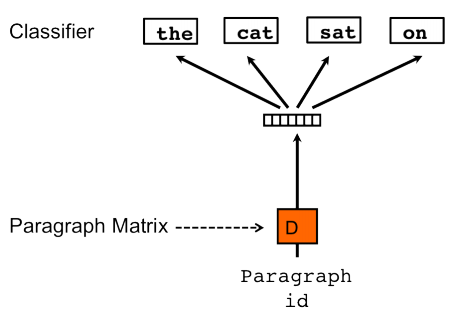
Once we can represent each movie as a vector, we can compute the cosine similarity between vectors to find movies that are similar. I won’t go into the details of cosine similarity here, but at a high level it tells us how similar movie vectors are to each other which we can use to generate recommendations.
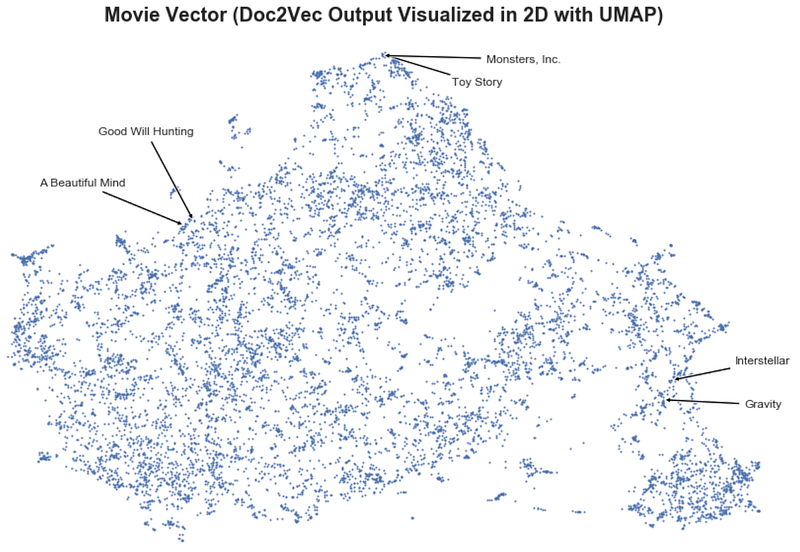
Below I visualize the movie vectors in 2D with UMAP which is a popular non-linear dimensionality reduction technique. We can see that movies that are closer together in this vector space are more similar (e.g. Toy Story and Monsters, Inc.).
3) How do we use tags to generate movie recommendations for a user?
Now that we can measure the similarity between movies with tags, we can start generating movie recommendations to users.
Remember that in content-based recommender systems, users will be recommended movies that are similar to movies they’ve already watched. If the user has only seen one movie (e.g. Good Will Hunting), we can simply use the Jaccard Index (or Cosine Similarity) as before to generate a list of similar movies to recommend.
More realistically, a user will have watched a set of movies and we need to generate recommendations based on the combined attributes of these movies.
One simple way is to compute a user vector as an average of the movie vectors that they’ve seen. These user vectors can represent the user’s profile of movie preferences.
For example, if a user has only seen movies A and B below:
- Movie A = (1, 2, 3)
- Movie B = (7, 2, 1)
- User vector = average of movies A and B = (4, 2, 2)
Below are movies that I watch and enjoy. How do we generate movie recommendations using tags from these movies?
Interstellar, Good Will Hunting, Gattaca, Almost Famous, The Shawshank Redemption, Edge of Tomorrow, Jerry Maguire, Forrest Gump, Back to the Future
Well my user vector would be an average of the movie vectors for the nine movies above. I can take my user vector and find the most similar movies (based on cosine similarity) that I haven’t watched yet. Below are my movie recommendations which are surprisingly good considering we’re only using movie tags here! Feel free to play with the notebook and generate your own recommendations.
The Theory of Everything
Cast Away
Dead Poets Society
Charly
Rain Man
Groundhog Day
Pay It Forward
A Beautiful Mind
E.T. the Extra-Terrestrial
Mr. Holland's Opus
On Golden Pond
It's a Wonderful Life
Children of a Lesser God
The Curious Case of Benjamin Button
Star Trek II: The Wrath of Khan
Cinema Paradiso
Mr. Smith Goes to Washington
The Terminal
Her
The World's Fastest Indian
The Truman Show
Star Trek: First Contact
The Family ManBelow summary of our content-based recommender system. Note that we can precompute the user vector and similarity scores in a batch process to speedup the serving of recommendations if we deploy our system as an API.
- Input: User vector (average of movie vectors learned from tags)
- Output: List of movies that are similar to the user based on cosine similarity of user and movie vectors





