
How to Build a Data Platform: A Comprehensive Guide for Technical Teams

Welcome to my article on building a data platform! In this article, I am going to walk you through the process of designing, building, and deploying a data platform that meets the needs of your organization.
A data platform is a centralized system that collects, stores, processes, and analyzes data from multiple sources. It provides a secure and scalable infrastructure for managing large volumes of data, and allows organizations to gain insights and make informed decisions based on that data. A well-designed data platform can help you improve operational efficiency, reduce costs, and drive innovation.
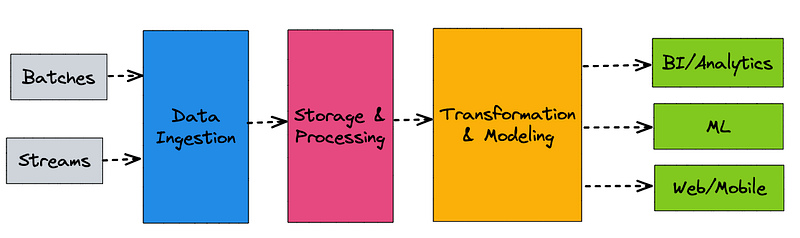
Building a data platform is a complex and multi-faceted process that requires careful planning and execution. It involves a wide range of technical and business considerations, such as choosing the right data storage and processing technologies, ensuring data quality, and maintaining data security and compliance.
In this guide, I’m going to take you through each step of the process, providing detailed technical guidance and best practices along the way. By the end of this guide, you’ll have a solid understanding of what it takes to build a robust and scalable data platform that can meet the needs of your organization.
So, let’s get started!
Planning and Design
Careful planning and design are crucial to ensure that the platform meets the specific needs of your organization. First, it’s important to define your business requirements. What are the specific use cases for your data platform? What types of data do you need to collect and store? What are the performance and scalability requirements? It’s important to hash out these requirements beforehand as different data needs different tools for data ingestion and transformation.
Once you have a clear understanding of your business requirements, the next step is to identify your data sources. This can include a variety of different data types, such as structured and unstructured data, data from various applications and systems, and data from external sources. It’s important to ensure that your data sources are reliable, accessible, and compatible with your chosen data storage technologies.
Speaking of data storage technologies, there are a variety of options to choose from, including relational databases, NoSQL databases, and data lakes. Each option has its own pros and cons, so it’s important to carefully evaluate which option is the best fit for your organization’s specific needs. You can combine multiple technologies based on your scalability and accessibility needs.
Once you have chosen your data storage technology, you’ll need to design your data models. This involves defining the structure of your data, including the relationships between different data elements. Your data models should be flexible and scalable, allowing you to add new data types and attributes as needed. This become even more important when dealing with structured data. If you don’t follow best practices, you’ll soon see a lot of models with a lot of overlap, whereas if you had followed star schema, you might have avoided a lot of unnecessary joins and unions.
Finally, you’ll need to select the appropriate data processing tools for your platform. This can include tools for data ingestion, preprocessing, transformation, integration, storage, and access. You’ll want to choose tools that are compatible with your chosen data storage technology and data models, and that can scale with your organization’s needs over time. I have a dedicate article on data processing tools that you can find it in the references section.
Roles and Responsibilities of the Builders
As I described earlier, building a data platform is a complex and multifaceted endeavor that involves a range of roles and responsibilities. In this section, I am going to share some of the key roles involved in building a data platform and their responsibilities. Needless to say that for smaller organizations sometimes one or two engineers wear multiple hats and play different roles.
- Data Architects: They are responsible for designing and implementing the data architecture of the platform. This includes defining data models, choosing data storage technologies, and designing the data pipeline.
- Data Engineers: They are responsible for implementing the data pipeline and ensuring that data is ingested, transformed, and loaded into the platform efficiently and accurately. They also ensure that the data platform is scalable and can handle large volumes of data.
- Data Analysts: They are responsible for analyzing and interpreting the data stored in the platform. They use tools such as SQL queries, data visualization, and statistical analysis to identify trends, patterns, and insights in the data.
- Data Scientists: They are responsible for developing predictive models and algorithms that can be used to make data-driven decisions. They use machine learning techniques and statistical analysis to identify patterns and make predictions based on historical data.
- Security and Compliance Officers: They are responsible for ensuring that the data platform is secure and compliant with relevant regulations such as HIPAA, GDPR, or CCPA. They identify potential risks and vulnerabilities and implement security measures to mitigate them.
- Business Analysts: They are responsible for understanding the business needs and requirements for the data platform. They work with stakeholders to identify key performance indicators, metrics, and goals for the platform and ensure that the platform is designed to meet those needs.
- Project Managers: They are responsible for managing the overall project and ensuring that the data platform is delivered on time and within budget. They coordinate the activities of the various teams involved in the project, communicate progress and issues to stakeholders, and ensure that the project stays on track.
Building the Data Pipeline
Now that you’ve defined your data models and selected the right data processing tools, it’s time to start building the data pipeline that will power your platform. This is where all the magic happens, as data flows through the pipeline and undergoes various transformations and processing steps before being stored in your data repository. There are two popular data pipeline design paradigm that you can research on your own, but here I try to keep things in a high level and explain the core.
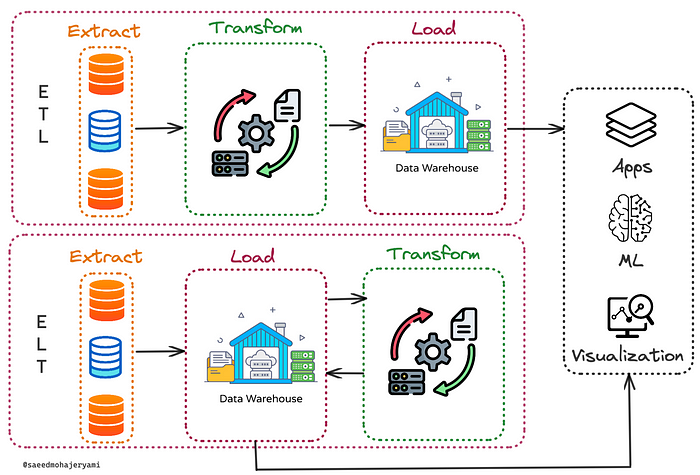
The first step in building your data pipeline is data ingestion. This involves collecting data from various sources and bringing it into your pipeline. Depending on the data sources, you may need to use different data ingestion techniques such as APIs, file transfers (FTP, SFTP, etc), or message queues. It’s important to ensure that your data ingestion process is reliable, efficient, and secure, as any errors or delays can cause issues downstream. Especially security (i.e. authentication and authorization) plays an important role here.
Once data is ingested into the pipeline, it needs to be preprocessed to ensure that it is in the correct format and structure. This may involve data cleaning, data deduplication, or data enrichment. It’s also a good idea to perform some basic quality checks at this stage to ensure that your data is valid and consistent.
The next step is data transformation, which involves converting data from one format to another and applying various data processing techniques such as filtering, aggregation, and normalization. This is where your data processing tools come into play, as they can help you automate many of these transformations and make them more efficient. This is where you might use big data technologies such as Spark or cloud data-warehousing internal distributed computation engines.
After data is transformed, it needs to be integrated with other data sources and systems. This may involve merging data from different sources, performing entity resolution, or enriching data with external sources such as social media or web data. This step might not be necessarily present in all data platforms.
Once data is integrated, it needs to be stored in your data repo. This may involve using a database, a data warehouse, or a data lake, depending on your specific requirements. It’s important to choose the right storage technology that can handle the volume, variety, and velocity of your data, while also providing the necessary data security and accessibility features.
Finally, data needs to be made accessible to users through data access and query tools. This may involve using SQL or NoSQL databases, data visualization tools, or data analytics platforms. It’s important to ensure that your data access and query tools are user-friendly, flexible, and scalable, so that your users can easily find and analyze the data they need. Data access and security would be applicable at this stage.
Ensuring Data Quality
As the saying goes, “garbage in, garbage out.” Building a data platform is not just about collecting as much data as possible — it’s also about ensuring that the data is accurate, reliable, and usable. In this section, I am going to take a look at some of the key techniques for ensuring data quality.
Data Profiling
The first step in ensuring data quality is to understand the data you’re working with. Data profiling involves analyzing the data to identify patterns, inconsistencies, and anomalies. This can help you determine the data’s overall quality and identify areas for improvement.
Data Cleaning
Once you’ve identified any issues with the data, the next step is to clean it up. This involves fixing errors, removing duplicates, and standardizing the data so that it’s consistent and easy to work with. Data cleaning can be a time-consuming process, but it’s essential for ensuring that the data is accurate and reliable.
Data Validation and Verification
After the data has been cleaned, it’s important to verify that it meets your organization’s standards and requirements. This involves validating the data against predefined rules and ensuring that it’s complete, accurate, and consistent. Data validation and verification can be automated using tools and scripts, which can save time and reduce the risk of errors. There are many paid or open source tools that can help you validate your data.
Data Monitoring and Logging
Finally, it’s important to continuously monitor the data to ensure that it remains accurate and up-to-date. This involves setting up alerts and notifications to track changes in the data and identify any issues as soon as possible. Logging can also be useful for tracking changes to the data over time, which can help with auditing and compliance. In smaller organization this task is typically done by data QAs, but larger organizations can afford to use in-house or third party tools to monitor the trend changes in your data to detect anomalies.
By following these techniques for ensuring data quality, you can ensure that your data platform is built on a solid foundation of accurate, reliable data. This will not only improve the overall quality of your data analysis and insights but also help you build trust with your stakeholders and customers.
Securing the Data Platform
Security is the bane of every data platform builder’s existence. But don’t worry, for we can make security work for us, not against us. Here are some key steps to secure your data platform:
Authentication and authorization — this is your first line of defense. Make sure only authorized users can access your data, and grant them the appropriate levels of access. Use strong authentication methods like multi-factor authentication to protect against password cracking. Don’t forget zero-trust security, it’s your friend in the era of modern data platform. You can find more about it in another article of mine (here).
Encryption — your data is valuable, and you don’t want it to fall into the wrong hands. Encrypt your data both in transit and at rest. Use industry-standard encryption algorithms and keys, and store your keys securely. If you’re using cloud service, you’re fortunate that this task is outsourced to your cloud provider, but it’s still important to have a good key rotation and key management systems.
Network security — protect your data as it moves across your network. Use firewalls and intrusion detection systems to block unauthorized access attempts. Secure your APIs and endpoints, and limit access to only authorized users.
Auditing and compliance — make sure you’re meeting all the relevant compliance requirements for your industry. Keep detailed logs of all access and activity on your platform, and use analytics to detect anomalies and potential security breaches.
Remember, security is not a one-time job, it’s a continuous process. Stay up-to-date on the latest security threats and best practices, and be proactive in protecting your data platform. By doing so, you’ll ensure that your platform is a secure and trusted environment for your data and users.
Scaling and Performance Optimization
Scaling your data platform is all about ensuring that it can handle the increasing volume of data that your organization generates over time. There are two main types of scaling: horizontal and vertical.
Horizontal scaling involves adding more nodes to your data platform’s infrastructure. This allows you to distribute the workload across multiple nodes, which can help improve performance and handle larger amounts of data. On the other hand, vertical scaling involves upgrading your existing nodes with more powerful hardware, such as more RAM or CPU cores. This topic is slowly becoming less relevant in the era of modern cloud services; however, in organizations that use hybrid strategies, it’s still a relevant topic.
When it comes to scaling your data platform, it’s important to plan ahead and design your infrastructure with scalability in mind. This means choosing technologies that can scale horizontally or vertically. Also, you should make a decision whether you want to manage the scaling issues yourself or you want to use a managed cloud services that manage scalability on your behalf.
In addition to scaling, performance optimization is also critical to ensuring that your data platform can handle large amounts of data efficiently. Performance tuning involves identifying and resolving bottlenecks in your data platform’s infrastructure and software, such as slow queries or network latency. In this situation, it’s always beneficial to educate your entire data team on best practices in data warehousing and building models. Some common performance tuning techniques include optimizing data models, caching frequently accessed data, and using compression to reduce the amount of data that needs to be transferred across the network.
Testing and Validation
Testing and validation are critical components of building a robust data platform. In this section, I explore the different types of testing you should perform to ensure that your platform is reliable, efficient, and accurate.
Unit testing is the first type of testing you should perform. It involves testing individual components of your platform to ensure that they work correctly. Unit tests should be automated and run frequently to catch bugs early in the development process.
Integration testing comes next. This type of testing focuses on how different components of your platform work together. You should test the integration of each component with other components to ensure that they work together seamlessly.
Acceptance testing is another crucial type of testing. This involves testing the entire platform end-to-end to ensure that it meets the business requirements. Acceptance tests should be performed by users who are not involved in the development process to ensure objectivity. Or even better, if you use CI/CD and real data to automate the test.
Finally, regression testing is essential to ensure that changes made to the platform don’t break existing functionality. You should perform regression tests whenever you make significant changes to your platform to ensure that it continues to function correctly.
In summary, testing and validation are critical to building a reliable and efficient data platform. By performing unit, integration, acceptance, and regression testing, you can ensure that your platform is accurate, reliable, and meets the business requirements.
Deployment and Maintenance
Deploying and maintaining a data platform can be a challenging task, but with the right strategies and tools, it can also be a rewarding one. In this section, I share some of the key considerations for deploying and maintaining a data platform, from choosing a deployment strategy to monitoring and troubleshooting the system.
Deployment Strategies
One of the first decisions you’ll need to make when deploying a data platform is how to deploy it. There are several deployment strategies you can choose from, including:
- On-premises deployment: This involves deploying the data platform on your own hardware, either in your own data center or in a third-party data center. This approach gives you full control over the hardware and software, but also requires you to manage and maintain the infrastructure yourself.
- Cloud deployment: This involves deploying the data platform in a public cloud environment such as AWS, Azure, or GCP. This approach provides scalability, flexibility, and ease of management, but also requires careful consideration of security and compliance issues.
- Hybrid deployment: This involves deploying the data platform across multiple environments, such as on-premises and cloud. This approach provides the best of both worlds, but also requires careful integration and management of the different environments.
System Administration
Once your data platform is deployed, you’ll need to manage and administer it to ensure that it is running smoothly and securely. This involves tasks such as:
- Configuring and monitoring the system: You’ll need to configure the system according to your specific needs, and then monitor it regularly to ensure that it is performing as expected.
- Managing users and permissions: You’ll need to manage user accounts and permissions to ensure that only authorized users have access to the system and the data.
- Backing up and restoring data: You’ll need to establish a backup and restore strategy to ensure that your data is protected in case of hardware or software failures.
- Upgrading and patching software: You’ll need to keep the software up to date by installing updates and patches as they become available.
Monitoring and Troubleshooting
Finally, you’ll need to monitor and troubleshoot the data platform to ensure that it is running smoothly and to identify and resolve any issues that arise. This involves tasks such as:
- Monitoring system performance: You’ll need to monitor the system performance regularly to ensure that it is meeting your performance requirements. This also include costs. You need to keep an eye on it to tune expensive queries.
- Identifying and resolving issues: You’ll need to be able to identify and resolve issues that arise, such as hardware failures, software bugs, or security breaches, or even silly events such as broken third party package that can affect your entire CI/CD and development process.
- Logging and auditing: You’ll need to log and audit system activity to ensure that you can track down issues and identify potential security breaches.
By following these best practices for deploying and maintaining a data platform, you can ensure that your platform is highly scalable, secure, and efficient, and that it provides the data insights you need to drive your business forward.
Data Platform Anti-patterns
While building a data platform can be a complex and challenging task, there are certain practices that can lead to common pitfalls or anti-patterns. In this section, I am going to discuss some of the most common anti-patterns in data platform building.
- Building a monolithic data platform: A monolithic data platform is one that is designed as a single, large system that handles all aspects of data processing and storage. This can make the system difficult to scale and maintain, as any changes to one part of the system can have unintended consequences on other parts of the system.
- Focusing on technology instead of business requirements: A data platform should be built to meet the specific needs of the business, not simply to use the latest and greatest technology. Focusing too much on technology can lead to a platform that doesn’t effectively solve the business’s problems.
- Not designing for data quality: Data quality is a critical component of any data platform. Failing to design for data quality can lead to inaccurate or incomplete data, which can have serious consequences for decision-making and analysis.
- Ignoring security and compliance: A data platform that doesn’t prioritize security and compliance can put sensitive data at risk, and can expose the organization to legal and financial penalties.
- Neglecting testing and validation: Testing and validation are critical components of building a data platform. Failing to thoroughly test and validate the platform can lead to unexpected errors and issues that can be difficult to diagnose and fix.
- Failing to plan for scalability: A data platform that isn’t designed to scale as the business grows can lead to performance issues and can limit the platform’s usefulness over time.
Conclusion
Building a data platform can be a challenging but highly rewarding endeavor. By creating a centralized platform for storing, processing, and analyzing data, organizations can gain valuable insights, improve decision-making, and enhance overall business performance. However, building a data platform requires careful planning, technical expertise, and a deep understanding of data management and security. Obviously, if you’re a small startup and you don’t have a complex data needs, data platform might be an overkill, but any orgs will reach a maturity that building a data platform is inevitable and allows for scalability and growth.
Throughout the article, I explored the key components of building a data platform, from planning and design to deployment and maintenance. I tried to cover topics such as data ingestion, preprocessing, transformation, integration, storage, and access, as well as data quality, security, and scalability.
I also discussed the importance of testing and validation, as well as deployment strategies, system admin, monitoring, and troubleshooting. By following these best practices and using the right tools and technologies, I hope you’d be able to build a data platform that meets your specific needs and requirements.
Of course, building a data platform is not without its challenges. Organizations must carefully balance the trade-offs between performance, scalability, and security, and must be prepared to adapt to changing business needs and technological advancements.
References
- Designing a data warehouse from the ground up: Tips and Best Practices (link)
- Query Optimization 101: Techniques and Best Practices (link)
- Advanced Strategies for Partitioning and Clustering in BigQuery (link)
- Building a Secure Future: An Introduction to Zero Trust Security (link)
- From Hadoop to Spark: An In-Depth Look at Distributed Computing Frameworks (link)
- Implementing Data Governance: A Step by Step Guide for Achieving Compliance and Data-Driven Insights (link)
- Data Catalog: A Key to Unlocking Business Insights (link)
- Metadata Management: A Key Component of Data Governance (link)
- Ensuring Data Quality: Best Practices, Challenges and Solutions (link)
- Data Security: Essential Considerations for Data Engineers (link)
- Data integrity vs. Data quality (link)
- Exploring the Benefits and Challenges of Using Data Integration APIs (link)
- Data Processing Evolution: ETL vs ELT- Which One Suits Your Business Needs? (link)
- Data Orchestration 101: Understanding the Different Types of Tools and Their Use Cases (link)
- The Evolution of SQL: A Look at the Past, Present, and Future of SQL Standards (link)
- Advanced Dynamic SQL Topics: Stored Procedures, ORM, and BI Tools (link)
I hope you enjoyed reading this 🙂. If you’d like to support me as a writer consider signing up to become a Medium member. It’s just $5 a month and you get unlimited access to Medium 🙏 . Before leaving this page, I appreciate if you follow me on Medium and Linkedin 👉 Also, if you are a medium writer yourself, you can join my Linkedin group. In that group, I share curated articles about data and technology. You can find it: Linkedin Group. Also, if you like to collaborate, please join me as a group admin.





