
How to Become a Data Engineer
A shortcut for beginners in 2024

This story explains an accelerated way of getting into the data engineering role by learning the required skills and familiarising yourself with data engineering tools and techniques. It will be useful for beginner-level IT practitioners and intermediate software engineers who would like to make a career change. Through my years as a Head of Data Engineering for one of the most successful start-ups in the UK and mid-east, I learned a lot from my career and I would like to share this knowledge and experience with you. This is a reflection of my personal experience in the data engineering field I acquired over the last 12 years. I hope it will be useful for you.
Data engineer — the role
First and foremost, why data engineer?
Data engineering is an exciting and very rewarding field. It’s a fascinating job where we have a chance to work with everything that touches data — APIs, data connectors, data platforms, business intelligence and dozens of data tools available in the market. Data engineering is closely connected with Machine learning (ML). You will create and deploy all sorts of data and ML pipelines.
It definitely won’t be boring and it pays well.
It pays well because it’s not easy to build a good data platform. It starts with requirements gathering and design and requires considerable experience. It’s not an easy task and requires some really good programming skills as well. The job itself is secure because as long businesses generate data this job will be in high demand.
The companies will always hire someone who knows how to process (ETL) data efficiently.
Data engineering has been one of the fastest-growing careers in the UK over the last five years, ranking 13 on LinkedIn’s list of the most in-demand jobs in 2023 [1]. The other reason to join is the scarcity. In IT space it is incredibly difficult to find a good data engineer these days.
As a “Head of Data Engineering” I receive 4 job interview invites on LinkedIn each week. On average. Entry level data engineering roles are in higher demand.
According to tech job research conducted by DICE Data Engineer is the fastest growing tech occupation:
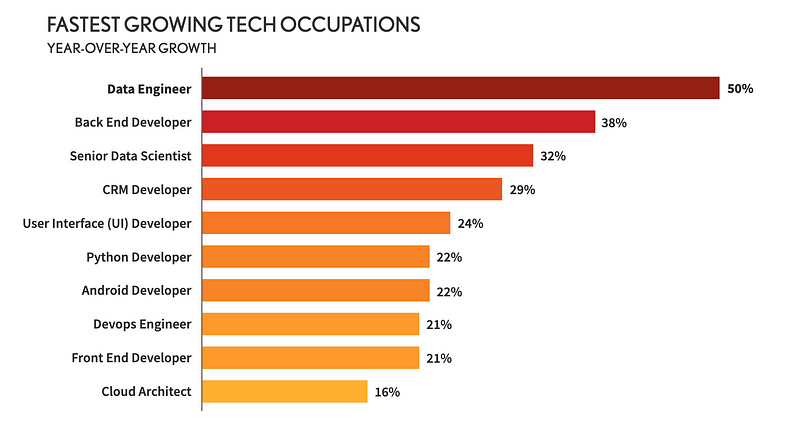
Modern data stack
Modern data stack refers to a collection of data processing tools and data platform types.
Are you in the space?
“Are you in the space?” — This is the question I was asked during one of my job interviews. You would want to be able to answer this one, and be aware of the news, IPOs, recent developments, breakthroughs, tools and techniques. Familiarise yourself with common data platform architecture types, i.e. data lake, lakehouse, data warehouse and be ready to answer which tools they use. Check this article for some examples:
Data pipelines
As a data engineer, you will be tasked with data pipeline design almost every day. You would want to familiarise yourself with data pipeline design patterns and be able to explain when to use them. It is crucial to apply this knowledge in practice as it defines which tools to use. The right set of data transformation tools can make the data pipeline extremely efficient. So, we need to know exactly when to apply streaming data processing and when to apply batch. One can be very expensive and the other one can save thousands. However, business requirements might be different in each case. This article has a comprehensive list of data pipeline design patterns:
Data modelling
I would say data modelling is an essential part of data engineering. Many data platforms are designed in a way that data is being loaded into the data warehouse solution “as is”. This is called the ELT approach. Data engineers are tasked to create data transformation pipelines using standard SQL dialect very often. Good SQL skills are a must. Indeed, SQL is natural for analytics querying and pretty much is a standard this day. It helps to query data efficiently and enables all business stakeholders with the power of analytics easily.
Data engineers must know how to cleanse, enrich and update datasets. For example, using MERGE to perform incremental updates. Run this SQL in your workbench or data warehouse (DWH). It explains how it worls:
create temp table last_online as (
select 1 as user_id
, timestamp('2000-10-01 00:00:01') as last_online
)
;
create temp table connection_data (
user_id int64
,timestamp timestamp
)
PARTITION BY DATE(_PARTITIONTIME)
;
insert connection_data (user_id, timestamp)
select 2 as user_id
, timestamp_sub(current_timestamp(),interval 28 hour) as timestamp
union all
select 1 as user_id
, timestamp_sub(current_timestamp(),interval 28 hour) as timestamp
union all
select 1 as user_id
, timestamp_sub(current_timestamp(),interval 20 hour) as timestamp
union all
select 1 as user_id
, timestamp_sub(current_timestamp(),interval 1 hour) as timestamp
;
merge last_online t
using (
select
user_id
, last_online
from
(
select
user_id
, max(timestamp) as last_online
from
connection_data
where
date(_partitiontime) >= date_sub(current_date(), interval 1 day)
group by
user_id
) y
) s
on t.user_id = s.user_id
when matched then
update set last_online = s.last_online, user_id = s.user_id
when not matched then
insert (last_online, user_id) values (last_online, user_id)
;
select * from last_online
;Some advanced SQL hints and tricks can be found here:
Coding
This is really important as data engineering is not only about data modelling and SQL. Consider data engineers as software engineers instead. They must have good knowledge of ETL/ELT techniques and also must be able to code at least in Python. Yes, it is obvious that Python is no doubt, the most convenient programming language for data engineering but everything you can do with Python can be easily done with any other language, i.e. Java Script or Java. Don’t limit yourself, you’ll have time to learn any language your company chose as the main one for their stack.
I would recommend to start with data APIs and requests. Combining this knowledge with Cloud services gives us a very good foundation for any ETL processes we might need in the future.
We can’t know everything and it’s not required to be a coding guru but we must know how to process data.
Consider this example of loading data into BigQuery data warehouse. It will use BigQuery client libraries [5] to insert rows into a table:
from google.cloud import bigquery
...
client = bigquery.Client(credentials=credentials, project=credentials.project_id)
...
def _load_table_from_csv(table_schema, table_name, dataset_id):
'''Loads data into BigQuery table from a CSV file.
! source file must be comma delimited CSV:
transaction_id,user_id,total_cost,dt
1,1,10.99,2023-04-15
blob = """transaction_id,user_id,total_cost,dt\n1,1,10.99,2023-04-15"""
'''
blob = """transaction_id,user_id,total_cost,dt
1,1,10.99,2023-04-15
2,2, 4.99,2023-04-12
4,1, 4.99,2023-04-12
5,1, 5.99,2023-04-14
6,1,15.99,2023-04-14
7,1,55.99,2023-04-14"""
data_file = io.BytesIO(blob.encode())
print(blob)
print(data_file)
table_id = client.dataset(dataset_id).table(table_name)
job_config = bigquery.LoadJobConfig()
schema = create_schema_from_yaml(table_schema)
job_config.schema = schema
job_config.source_format = bigquery.SourceFormat.CSV,
job_config.write_disposition = 'WRITE_APPEND',
job_config.field_delimiter =","
job_config.null_marker ="null",
job_config.skip_leading_rows = 1
load_job = client.load_table_from_file(
data_file,
table_id,
job_config=job_config,
)
load_job.result()
print("Job finished.")We can’t know everything and it’s not required to be a coding guru but we must know how to process data.
We can run it locally or deploy it in the cloud as a serverless application. It can be triggered by any other service we choose. For example, deploying an AWS Lambda or GCP Cloud Function can be very efficient. It will process our data pipeline events with ease and almost at zero cost. There is plenty of articles in my blog explaining how easy and flexible it can be.
Airflow, Airbyte, Luidgi, Hudi…
Play with 3rd party frameworks and libraries that help to manage data platforms and orchestrate data pipelines. Many of them are open-source such as Apache Hudi [6] and help to understand what is data platform management from different angles. Many of them are really good at managing batch and streaming workloads. I learned a lot simply by using them. Apache Airflow, for example, offers a lot of ready data connectors. We can use them to run our ETL tasks with ease with any cloud vendor (AWS, GCP, Azure).
It’s very easy to create batch data processing jobs using these frameworks. If we take a look under the hood it definitely makes things much clearer in terms of what the actual ETL is.
Consider this example of ML pipeline I built using airflow connectors to train the recommendation engine:
"""DAG definition for recommendation_bespoke model training."""
import airflow
from airflow import DAG
from airflow.contrib.operators.bigquery_operator import BigQueryOperator
from airflow.contrib.operators.bigquery_to_gcs import BigQueryToCloudStorageOperator
from airflow.hooks.base_hook import BaseHook
from airflow.operators.app_engine_admin_plugin import AppEngineVersionOperator
from airflow.operators.ml_engine_plugin import MLEngineTrainingOperator
import datetime
def _get_project_id():
"""Get project ID from default GCP connection."""
extras = BaseHook.get_connection('google_cloud_default').extra_dejson
key = 'extra__google_cloud_platform__project'
if key in extras:
project_id = extras[key]
else:
raise ('Must configure project_id in google_cloud_default '
'connection from Airflow Console')
return project_id
PROJECT_ID = _get_project_id()
# Data set constants, used in BigQuery tasks. You can change these
# to conform to your data.
DATASET = 'staging' #'analytics'
TABLE_NAME = 'recommendation_bespoke'
# GCS bucket names and region, can also be changed.
BUCKET = 'gs://rec_wals_eu'
REGION = 'us-central1' #'europe-west2' #'us-east1'
JOB_DIR = BUCKET + '/jobs'
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['[email protected]'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 5,
'retry_delay': datetime.timedelta(minutes=5)
}
# Default schedule interval using cronjob syntax - can be customized here
# or in the Airflow console.
schedule_interval = '00 21 * * *'
dag = DAG('recommendations_training_v6', default_args=default_args,
schedule_interval=schedule_interval)
dag.doc_md = __doc__
#
#
# Task Definition
#
#
# BigQuery training data export to GCS
training_file = BUCKET + '/data/recommendations_small.csv' # just a few records for staging
t1 = BigQueryToCloudStorageOperator(
task_id='bq_export_op',
source_project_dataset_table='%s.recommendation_bespoke' % DATASET,
destination_cloud_storage_uris=[training_file],
export_format='CSV',
dag=dag
)
# ML Engine training job
training_file = BUCKET + '/data/recommendations_small.csv'
job_id = 'recserve_{0}'.format(datetime.datetime.now().strftime('%Y%m%d%H%M'))
job_dir = BUCKET + '/jobs/' + job_id
output_dir = BUCKET
delimiter=','
data_type='user_groups'
master_image_uri='gcr.io/my-project/recommendation_bespoke_container:tf_rec_latest'
training_args = ['--job-dir', job_dir,
'--train-file', training_file,
'--output-dir', output_dir,
'--data-type', data_type]
master_config = {"imageUri": master_image_uri,}
t3 = MLEngineTrainingOperator(
task_id='ml_engine_training_op',
project_id=PROJECT_ID,
job_id=job_id,
training_args=training_args,
region=REGION,
scale_tier='CUSTOM',
master_type='complex_model_m_gpu',
master_config=master_config,
dag=dag
)
t3.set_upstream(t1)
It will create a simple data pipeline graph to export data into cloud storage bucket and then train the ML model using MLEngineTrainingOperator.
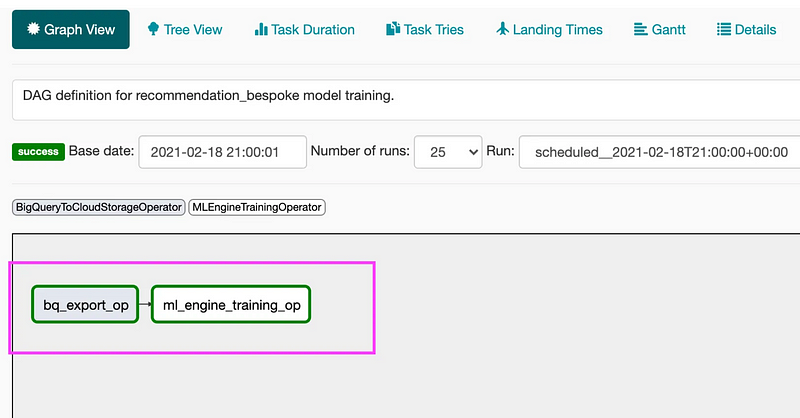
Orchestrate data pipelines
Frameworks are great but data engineers must know how to create their own frameworks to orchestrate data pipelines. This brings us back to raw vanilla coding and working with client libraries and APIs. A good advice here will be to familiarise yourself with data tools and their API endpoints. Very often it is much more intuitive and easier to create and deploy our own microservice to perform ETL/ELT jobs.
Orchestrate data pipelines with your own tools
For example, we can create a simple serverless application that will consume data from the message broker, such as SNS. Then it can process these events and orchestrate other microservices we create to perform ETL tasks. Another example is a simple AWS Lambda that is being triggered by new files created in the data lake, then based on the information it reads from the pipeline configuration file it can decide which service to invoke or which table to load data into. Consider this application below. It’s a very simple AWS Lambda that can be run locally or when it’s deployed in the cloud.
./stack
├── deploy.sh # Shell script to deploy the Lambda
├── stack.yaml # Cloudformation template
├── pipeline_manager
| ├── env.json # enviroment variables
│ └── app.py # Application
├── response.json # Lambda response when invoked locally
└── stack.zip # Lambda package`app.py` can be anything with ETL, we just need to add some logic like we did with data loading into BigQuery in the previous example using a couple of client libraries:
# ./pipeline_manager/app.py
def lambda_handler(event, context):
message = 'Hello {} {}!'.format(event['first_name'], event['last_name'])
return {
'message' : message
}No we can run it locally or deploy using infrastructure as code. This command line script will run this service locally:
pip install python-lambda-local
cd stack
python-lambda-local -e pipeline_manager/env.json -f lambda_handler pipeline_manager/app.py event.jsonAlternatively it can be deployed in the cloud and we can invoke it from there. This brings us into the Cloud.
Cloud services providers
Everything is managed in the cloud these days. That’s why learning at least one vendor is crucial. It can be AWS, GCP or Azure. They are the leaders and we would want to focus on one of them. It will be ideal to get a Cloud certification, such as “Google Cloud Professional Data Engineer” [7] or similar. These exams are difficult but it is worth getting one as it gives a good overview of data processing tools and makes us look very credible. I did one, have written down my experience in an article and you can find it in my stories.
Everything data engineers create with cloud functions and/or docker can be deployed in the cloud. Consider this AWS CloudFormation stack template below. We can use it to deploy our simple ETL microservice:
# stack.yaml
AWSTemplateFormatVersion: '2010-09-09'
Description: AWS S3 data lake stack.
Parameters:
ServiceName:
Description: Data lake microservice to process data files and load them into __ BigQuery.
Type: String
Default: datalake-manager
StackPackageS3Key:
Type: String
Default: pipeline_manager/stack.zip
Testing:
Type: String
Default: 'false'
AllowedValues: ['true','false']
Environment:
Type: String
Default: 'staging'
AllowedValues: ['staging','live','test']
AppFolder:
Description: app.py file location inside the package, i.e. ./stack/pipeline_manager/app.py.
Type: String
Default: pipeline_manager
LambdaCodeLocation:
Description: Lambda package file location.
Type: String
Default: datalake-lambdas.aws
Resources:
PipelineManagerLambda:
Type: AWS::Lambda::Function
DeletionPolicy: Delete
DependsOn: LambdaPolicy
Properties:
FunctionName: !Join ['-', [!Ref ServiceName, !Ref Environment] ] # pipeline-manager-staging if staging.
Handler: !Sub '${AppFolder}/app.lambda_handler'
Description: Microservice that orchestrates data loading into BigQuery from AWS to BigQuery project your-project-name.schema.
Environment:
Variables:
DEBUG: true
LAMBDA_PATH: !Sub '${AppFolder}/' # i.e. 'pipeline_manager/'
TESTING: !Ref Testing
ENV: !Ref Environment
Role: !GetAtt LambdaRole.Arn
Code:
S3Bucket: !Sub '${LambdaCodeLocation}' #datalake-lambdas.aws
S3Key:
Ref: StackPackageS3Key
Runtime: python3.8
Timeout: 360
MemorySize: 128
Tags:
-
Key: Service
Value: Datalake
LambdaRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
-
Effect: Allow
Principal:
Service:
- "lambda.amazonaws.com"
Action:
- "sts:AssumeRole"
LambdaPolicy:
Type: AWS::IAM::Policy
DependsOn: LambdaRole
Properties:
Roles:
- !Ref LambdaRole
PolicyName: 'pipeline-manager-lambda-policy'
PolicyDocument:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}If we run this shell script in our command line it will deploy our service and all required resources such as IAM policies, in the cloud:
aws \
cloudformation deploy \
--template-file stack.yaml \
--stack-name $STACK_NAME \
--capabilities CAPABILITY_IAM \
--parameter-overrides \
"StackPackageS3Key"="${APP_FOLDER}/${base}${TIME}.zip" \
"AppFolder"=$APP_FOLDER \
"LambdaCodeLocation"=$LAMBDA_BUCKET \
"Environment"="staging" \
"Testing"="false"After that we can invoke our service using SDK by running this CLI command from our command line tool:
aws lambda invoke \
--function-name pipeline-manager \
--payload '{ "first_name": "something" }' \
response.jsonMaster command line tools
Command line tools from Cloud vendors are very useful and help to create scripts to test our ETL services when they are deployed in the cloud. Data engineers use it a lot. Working with data lakes we would want to master CLI commands that help us manage Cloud storage, i.e. upload, download and copy files and objects. Why do we do this? Very often files in cloud storage trigger various ETL services. Batch processing is a very common data transformation pattern and in order to investigate bugs and errors we might need to download or copy files between buckets.
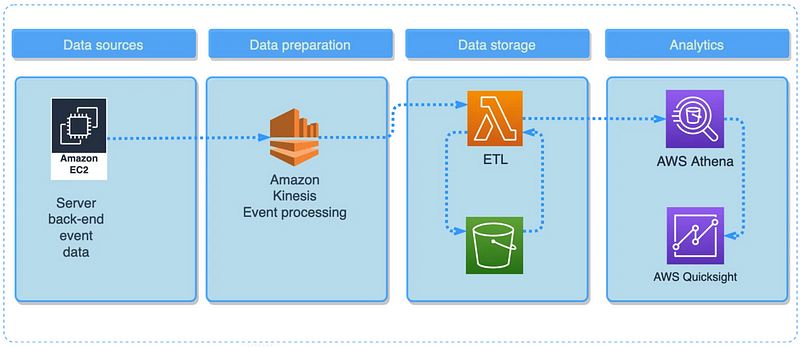
In this example, we can see that the service outputs data into Kinesis and then it is stored in the data lake. When file objects are being created in S3 they trigger the ETL process handled by AWS Lambda. The result is being saved in the S3 bucket to consume by AWS Athena in order to generate a BI report with AWS Quicksight.
Here is the set of AWS CLI commands we might want to use at some point:
Copy and upload file
mkdir data
cd data
echo transaction_id,user_id,dt \\n101,777,2021-08-01\\n102,777,2021-08-01\\n103,777,2021-08-01\\n > simple_transaction.csv
aws s3 cp ./data/simple_transaction.csv s3://your.bucket.aws/simple_transaction_from_data.csvRecursively copy/upload/download all files in the folder
aws s3 cp ./data s3://your.bucket.aws --recursiveRecursively delete all contents
aws s3 rm s3://your.bucket.aws/ --recursive --exclude ""Delete a bucket
aws s3 rb s3://your.bucket.aws/
There are more advanced examples but I think the idea is clear.
We would want to manage cloud storage efficiently with scripts.
We can chain these commands into shell scripts which makes CLI a very powerful tool.
Consider this shell script for example. It will check if storage bucket for lambda package exists, upload and deploy our ETL service as a Lambda Function:
# ./deploy.sh
# Run ./deploy.sh
LAMBDA_BUCKET=$1 # your-lambda-packages.aws
STACK_NAME=SimpleETLService
APP_FOLDER=pipeline_manager
# Get date and time to create unique s3-key for deployment package:
date
TIME=`date +"%Y%m%d%H%M%S"`
# Get the name of the base application folder, i.e. pipeline_manager.
base=${PWD##*/}
# Use this name to name zip:
zp=$base".zip"
echo $zp
# Remove old package if exists:
rm -f $zp
# Package Lambda
zip -r $zp "./${APP_FOLDER}" -x deploy.sh
# Check if Lambda bucket exists:
LAMBDA_BUCKET_EXISTS=$(aws s3 ls ${LAMBDA_BUCKET} --output text)
# If NOT:
if [[ $? -eq 254 ]]; then
# create a bucket to keep Lambdas packaged files:
echo "Creating Lambda code bucket ${LAMBDA_BUCKET} "
CREATE_BUCKET=$(aws s3 mb s3://${LAMBDA_BUCKET} --output text)
echo ${CREATE_BUCKET}
fi
# Upload the package to S3:
aws s3 cp ./${base}.zip s3://${LAMBDA_BUCKET}/${APP_FOLDER}/${base}${TIME}.zip
# Deploy / Update:
aws --profile $PROFILE \
cloudformation deploy \
--template-file stack.yaml \
--stack-name $STACK_NAME \
--capabilities CAPABILITY_IAM \
--parameter-overrides \
"StackPackageS3Key"="${APP_FOLDER}/${base}${TIME}.zip" \
"AppFolder"=$APP_FOLDER \
"LambdaCodeLocation"=$LAMBDA_BUCKET \
"Environment"="staging" \
"Testing"="false"More advanced examples can be found in my previous stories.
Data quality
Now when we know how to deploy ETL services, perform requests and pull data from external APIs we need to learn how to observe the data we have in our data platform. Ideally, we would want to check data quality in real-time as data flows into our data platform. It can be done both ways using the ETL or ELT approach. Streaming applications built with Kafka or Kinesis have libraries to analyze data quality as data flows in the data pipeline. ELT approach is preferable when data engineers delegate data observability and data quality management to other stakeholders working with the data warehouse. Personally, I like the latter approach as it saves time. Consider data warehouse solutions as a single source of truth for everyone in the company. Finance, marketing and customer services teams can access data and check for any potential issues. Among these we typically see the following:
- missing data
- data source outages
- data source changes when schema fields are updated
- various data anomalies such as outliers or unusual application/user behaviour.
Data engineers create alarms and schedule notifications for any potential data issues so data users stay always informed.
Consider this example when a daily email is sent to stakeholders informing them about data outage:
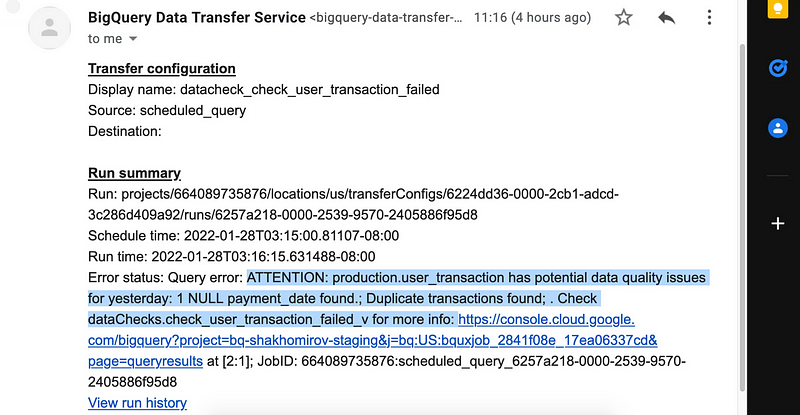
In my stories you can find an article explaining how to schedule such data monitoring workflow using SQL.
Consider this snippet below. It ewill check yeterday data ffor any missing field using row conditions and send a notification alarm if any were found:
with checks as (
select
count( transaction_id ) as t_cnt
, count(distinct transaction_id) as t_cntd
, count(distinct (case when payment_date is null then transaction_id end)) as pmnt_date_null
from
production.user_transaction
)
, row_conditions as (
select if(t_cnt = 0,'Data for yesterday missing; ', NULL) as alert from checks
union all
select if(t_cnt != t_cntd,'Duplicate transactions found; ', NULL) from checks
union all
select if(pmnt_date_null != 0, cast(pmnt_date_null as string )||' NULL payment_date found', NULL) from checks
)
, alerts as (
select
array_to_string(
array_agg(alert IGNORE NULLS)
,'.; ') as stringify_alert_list
, array_length(array_agg(alert IGNORE NULLS)) as issues_found
from
row_conditions
)
select
alerts.issues_found,
if(alerts.issues_found is null, 'all good'
, ERROR(FORMAT('ATTENTION: production.user_transaction has potential data quality issues for yesterday: %t. Check dataChecks.check_user_transaction_failed_v for more info.'
, stringify_alert_list)))
from
alerts
;Data environments
Data engineers test data pipelines. There are various ways of doing this. In general, it requires a data environment split between production and staging pipelines. Often we might need an extra sandbox for testing purposes or to run data transformation unit tests when our ETL services trigger CI/CD workflows. This is a common practice and job interviewers might ask a couple of questions regarding this. It might seem a little tricky in the beginning but this diagram below exlpains how it works.
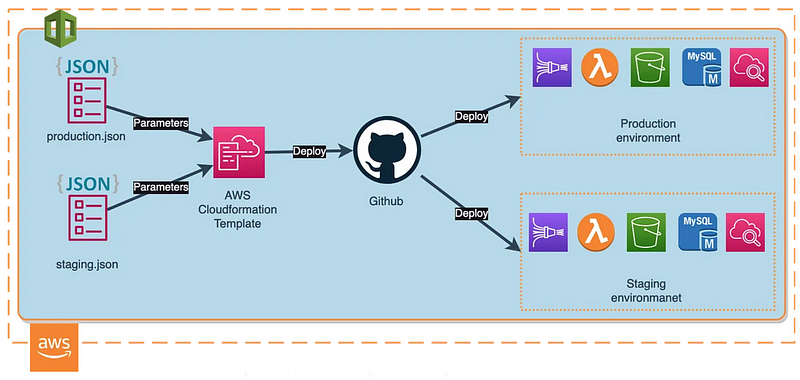
For example, we can use infrastructure as code and GitHub Actions to deploy and test staging resources on any pull request from the development branch. When all tests are passed and we are happy with our ETL service we can promote it to production by merging into the master branch.
Consider this GitHub action workflow below. It will deploy our ETL service on staging and do the testing. Suc approach helps reduce errors and deliver data piplelines faster.
# .github/workflows/deploy_staging.yaml
name: STAGING AND TESTS
on:
#when there is a push to the master
push:
branches: [ master ]
#when there is a pull to the master
pull_request:
branches: [ master ]
jobs:
compile:
runs-on: ubuntu-latest
steps:
- name: Checkout code into workspace directory
uses: actions/checkout@v2
- name: Install AWS CLI v2
run: |
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o /tmp/awscliv2.zip
unzip -q /tmp/awscliv2.zip -d /tmp
rm /tmp/awscliv2.zip
sudo /tmp/aws/install --update
rm -rf /tmp/aws/
- name: test AWS connectivity
run: aws s3 ls
env:
AWS_ACCESS_KEY_ID: ${{ secrets.MDS_AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.MDS_AWS_SECRET_ACCESS_KEY }}
AWS_DEFAULT_REGION: "eu-west-1"
- name: Deploy staging
run: |
cd stack
date
TIME=`date +"%Y%m%d%H%M%S"`
base=${PWD##*/}
zp=$base".zip"
rm -f $zp
pip install --target ./package pyyaml==6.0
cd package
zip -r ../${base}.zip .
cd $OLDPWD
zip -r $zp ./pipeline_manager
# Upload Lambda code (replace with your S3 bucket):
aws s3 cp ./${base}.zip s3://datalake-lambdas.aws/pipeline_manager/${base}${TIME}.zip
STACK_NAME=SimpleCICDWithLambdaAndRole
aws \
cloudformation deploy \
--template-file stack_cicd_service_and_role.yaml \
--stack-name $STACK_NAME \
--capabilities CAPABILITY_IAM \
--parameter-overrides \
"StackPackageS3Key"="pipeline_manager/${base}${TIME}.zip" \
"Environment"="staging" \
"Testing"="false"
env:
AWS_ACCESS_KEY_ID: ${{ secrets.MDS_AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.MDS_AWS_SECRET_ACCESS_KEY }}
AWS_DEFAULT_REGION: "eu-west-1"There is a full solution example in one of my stories.
Machine learning
Adding a machine learning component will make us a machine learning engineer. Data engineering and ML are very close as data engineers create data pipelines that are consumed by ML services often.
We don’t need to know every machine-learning model
We can’t compete with cloud service providers such as Amazon ang Google in machine learning and data science but we need to know how to use it. There are numerous managed ML services provided by cloud vendors and we would want to familiarize ourselves with them. Data engineers prepare datasets for these services and it will definitely be useful to do a couple of tutorials on this. For example, consider a churn prediction project to understand user churn and how to use managed ML services to generate predictions for users. This can easily done with BigQuery ML [9] by creating a simple logistic regression model like so:
CREATE OR REPLACE MODEL sample_churn_model.churn_model
OPTIONS(
MODEL_TYPE="LOGISTIC_REG",
INPUT_LABEL_COLS=["churned"]
) AS
SELECT
* except (
user_pseudo_id
,first_seen_ts
,last_seen_ts
)
FROM
sample_churn_model.churnAnd then we can generate predictions using SQL:
SELECT
user_pseudo_id,
churned,
predicted_churned,
predicted_churned_probs[OFFSET(0)].prob as probability_churned
FROM
ML.PREDICT(MODEL sample_churn_model.churn_model,
(SELECT * FROM sample_churn_model.churn)) #can be replaced with a proper test dataset
order by 3 descConclusion
I’ve tried to summarise a set of data engineering skills and techniques that are typically required for entry-level data engineering roles. Based on my experience these skills can be acquired within two to three months of active learning. I would recommend starting with cloud service providers and Python to build a simple ETL service with a CI/CD pipeline for staging and production split. It doesn’t cost anything and we can learn fast by running them both locally and when they are deployed in the cloud. Data engineers are in high demand in the market right now. I hope this article will help you to learn a couple of new things and prepare for job interviews.
Recommedned read
[1] https://www.linkedin.com/pulse/linkedin-jobs-rise-2023-25-uk-roles-growing-demand-linkedin-news-uk/
[2] https://towardsdatascience.com/data-platform-architecture-types-f255ac6e0b7
[3] https://towardsdatascience.com/data-pipeline-design-patterns-100afa4b93e3
[4] https://readmedium.com/advanced-sql-techniques-for-beginners-211851a28488
[5] https://cloud.google.com/python/docs/reference/bigquery/latest
[6] https://hudi.apache.org/docs/overview/
[7] https://cloud.google.com/learn/certification/data-engineer
[8] https://towardsdatascience.com/automated-emails-and-data-quality-checks-for-your-data-1de86ed47cf0
[9] https://cloud.google.com/bigquery/docs/bqml-introduction




