
How to avoid Overfitting in Neural Networks.
Learn and understand everything about overfitting in neural networks

Overfit Model: A model that learns the training dataset too well, performing well on the training dataset but does not perform well on a hold-out sample.
Too much learning and the model will perform well on the training dataset and poorly on new data, the model will overfit the problem.
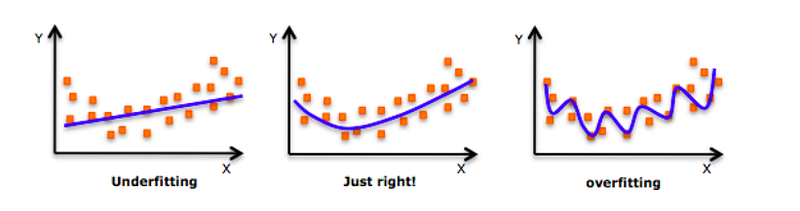
Regularization Methods for Neural Networks
What is Regularization? Regularization is a technique that makes slight modifications to the learning algorithm such that the model generalizes better. This in turn improves the model’s performance on the unseen data as well.
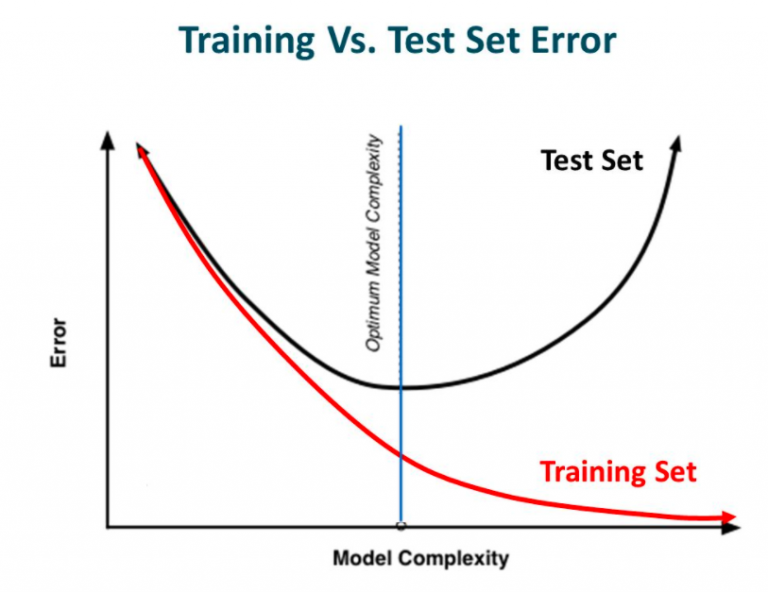
The model tries to learn too well the details and the noise from the training data, which ultimately results in poor performance on the unseen data. In other words, while going towards the right, the complexity of the model increases such that the training error reduces but the testing error doesn’t.
Different Regularization Techniques in Deep Learning
1. L2 & L1 regularization
L1 and L2 are the most common types of regularization. These update the general cost function by adding another term known as the regularization term.
Cost function = Loss (say, binary cross entropy) + Regularization termDue to the addition of this regularization term, the values of weight matrices decrease because it assumes that a neural network with smaller weight matrices leads to simpler models. Therefore, it will also reduce overfitting to quite an extent. However, this regularization term differs in L1 and L2.
In L2, Here, lambda is the regularization parameter. It is the hyperparameter whose value is optimized for better results. L2 regularization is also known as weight decay as it forces the weights to decay towards zero (but not exactly zero).
In L1, In this, we penalize the absolute value of the weights. Unlike L2, the weights may be reduced to zero here. Hence, it is very useful when we are trying to compress our model. Otherwise, we usually prefer L2 over it.
2. Dropout
This is one of the most interesting types of regularization techniques. It also produces very good results and is consequently the most frequently used regularization technique in the field of deep learning. At every iteration, it randomly selects some nodes and removes them along with all of their incoming and outgoing connections as shown below. So each iteration has a different set of nodes and this results in a different set of outputs.
It can also be thought of as an ensemble technique in machine learning
Dropout provides an inexpensive approximation to training and evaluating a bagged ensemble of exponentially many neural networks. Dropout trains the ensemble consisting of all sub-networks that can be formed by removing non-output units from an underlying base network.
3.Data Augmentation
The simplest way to reduce overfitting is to increase the size of the training data. In machine learning, we were not able to increase the size of training data as the labeled data was too costly. One way is to create fake data and add it to our training dataset, for some domains this is fairly straightforward and easy. Dataset Augmentation is a very popular approach for Computer vision tasks such as image classification or object recognition as Images are high dimensional and include an enormous variety of factors of variation, many of which can be easily simulated.
4.Early Stopping of Training
When training a large model on a sufficiently large dataset, if the training is done for a long amount of time rather than increasing the generalization capability of the model, it increases the overfitting. As in the training process, the training error keeps on reducing but after a certain point, the validation error starts to increase hence signifying that our model has started to overfit.
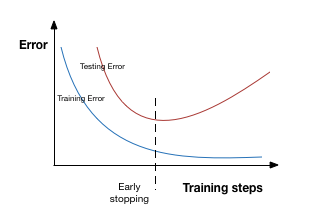
The idea of early stopping of training is that as soon as the validation error starts to increase we freeze the parameters and stop the training process. Or we can also store the copy of model parameters every time the error on the validation set improves and return these parameters when the training terminates rather than the latest parameters. Early stopping has an advantage over weight decay that early stopping.
What are other techniques you use to stop overfitting in your Models? Please share your views in the comments.
Recommended Articles
In this article, we discussed how to avoid/deal Overfitting our NN model You can also go through our other suggested articles to learn more –
- PyTorch 1.9 — Towards Distributed Training and Scientific Computing
- Why you need a BI platform and how to choose one.
- Top 10 Data Science Tools Everyone Needs to Know
- Q&A for Time Series Analysis
- 8 books about Data Science for beginners
- What’s Better: Tensorflow or Pytorch?
- 5 Real Examples of Business Intelligence in Action
- Tips to Succeed with Big Data in Data Science
- Importance of NLP in Data Science
About me
I am a Data Science freelancer with over 2years of experience. I am always looking to connect so please feel free to:
Please feel free to comment below if you have any questions
Don’t forget to follow The Lean Programmer Publication for more such articles, and subscribe to our newsletter tinyletter.com/TheLeanProgrammer





