
How to Auto-Generate a Summary from Long Youtube Videos Using AI
A step-by-step guide to resume a talk by Stephen Wolfram using Whisper and BART models on your local PC

Motivation
In today’s rapidly changing world, staying informed and inspired can be challenging, especially when time is short. Personally, I am a huge fan of YouTube podcasts and talks. The podcasts and the talks are goldmines of knowledge, fully packed with insights from the brightest minds across various fields. However, due to time constraints, it’s not possible for me to watch every interesting video since they typically exceed one hour in length. This led me to wonder: what if I could create an end-to-end solution to extract automatically the main highlights? As a result, I started exploring AI-generative solutions to help me get auto summaries of some of the podcasts/talks I missed.
In this article, I discuss the end-to-end solution on a local PC. First, I will cover the transcription process of one of Stephen Wolfram's talks about ChatGPT, AI, and AGI available on Youtube, using the open-source Whisper Model available on HuggingFace Hub. Then, I will demonstrate how to summarize long text using the open-source BART model.
Let’s see how to achieve this.
Keep in mind, it is crucial to verify that the copyright/licence permits downloading the content before you proceed with the download.
A bit of context
Whisper is an open-source automatic speech recognition model, trained on 680,000 hours of multilingual data gathered from the internet. It relies on an end-to-end encoder-decoder Transformer architecture.
BART is a transformer-based seq2seq model that combines a bidirectional (BERT-style) encoder with an autoregressive (GPT-style) decoder. It’s pre-trained by randomly adding noise and learning to rebuild the original content.It performs well on tacks such as summmarization and translation.
HuggingFace transformers library provides a user-friendly solution to use and customize models. Additionally, it comes with APIs you can use to fine-tune the models to better fit your data.
PyTube is a depenency-free Python library for downloading and streaming YouTube videos.
NLTK is a Natural Language Toolkit standard Python library widely used for natural language processing(NLP) tasks.
The end-to-end process
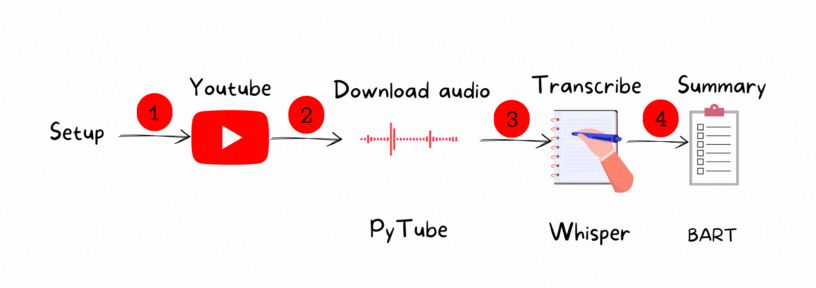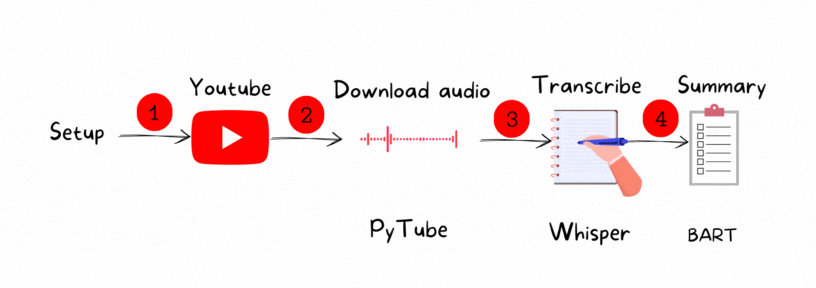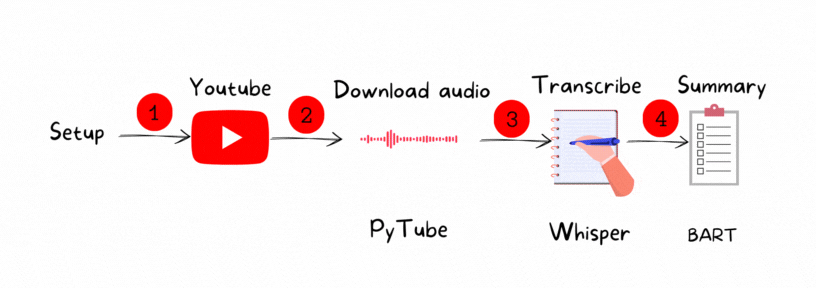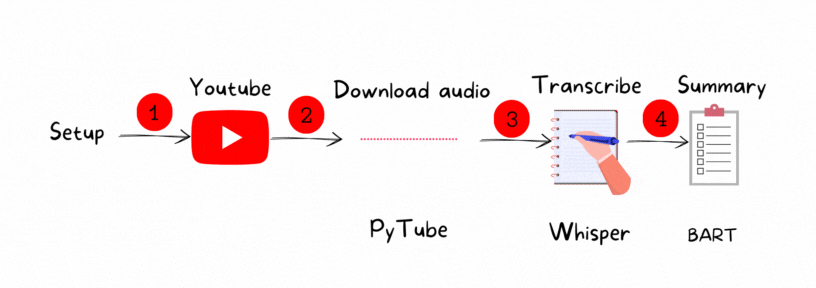
The process contains four main steps:
1. Set up the environment
2. Download the YouTube video : PyTube
3. Transcribe the audio: Whisper
4. Summarize the generated text: BART
1. Set up the environment
My environment setup looks as follows:
- Jupyter Notebook running in a virtual environment with Python 3.10
- Models: OpenAI Whisper, BART
- Libraries: pytube, transformers, unstructured, ffmpeg-python
1.1 Install the libraries
Several remarks:
👉 ️Please be aware that you need ! only if you install the libraries from a notebook cell.
👉 Install the latest update of the Whisper model directly from GitHub.
👉 Troubleshoot PyTube. In case you run into the following error "pytube: AttributeError: ‘NoneType’ object has no attribute ‘span’ cipher.p" y go to {home}/.local/lib/{your_pythonversion: ex. python3.10}/site-packages/pytube/cipher.py Line 411 and replace the value of thetransform_plan_raw variable as follows:
1.2 Import the libraries
1. Download the YouTube video
Let’s get the summary of the following talk “ChatGPT, AI, and AGI with Stephen Wolfram (Founder & CEO of Wolfram Research)” available on YouTube (Creative Commons Attribution license (reuse allowed)).
To download locally the video as an audio file we use the YouTube class of the PyTube library. Make sure to provide a valid URL.
2. Transcribe the audio
Once we have downloaded the audio locally, we should see a file called demo.mp3. To transcribe the audio, we load the medium Whisper multilingual model, which has 769 million parameters and is available in either English or a multilingual format. You can review the list of language models available and choose the more convenient one for your setup. For more accuracy, you can use the large Whisper multilingual model.
The resulting concatenated string will be stored in the result[‘text’] variable, which is saved locally in demo.txt file.
❗️ It’s important to note that the transcription process may take over an hour, depending on your PC’s configuration. To test the demo, you may choose a shorter video.
3. Summarize the generated text
Because of the model’s incapacity to handle multiple tokens at once, it’s important to split the text into smaller segments, each containing a maximum of 4000 tokens. To do this, we can use the punkt pre-trained sentence tokenizer model, which is part of the Natural Language Toolkit (NLTK) library and is effective in processing natural language. Once we’ve divided the text into smaller sentence chunks, we can store them in the text_chunks variable for further use.
We use sentence tokenization to prevent any loss of information
3.1 Divide the large text into chunks
Here’s the code that can be used to do the work.
The code consists of two functions: read_file() that reads the demo.txt file and split_text_into_chunks() that splits the text into chunks.
3.2 Text Summarization with BART
To summarize the text we use the HuggingFace Transformerslibrary and the pre-trained multilingual BART-large model, facebook/bart-large-cnn fine-tuned on the CNN Daily Mail dataset. The Transformers library by Hugging Face offers many ready-to-use models for various tasks like text, images, or sounds. For instance, it provides an easy-to-use text summarization pipeline for the BART model:pipeline("summarization", model="facebook/bart-large-cnn"). This makes it easy and user-friendly.
The code for performing the summarization is provided below.
Overall, the code creates an instance of the BART summarizer, generates a summary for the given text chunks, and saves it tosummary_demo.txt file only if the summary is successfully generated. If the summary has more than 5000 characters we will proceed by applying once gain the Bart summarizer. The output is saved in the short_summary_demo.txt file.
Here is the summary:
The Wolfram language could be the basis for a more systematic exploration of the nature and the depths of large language models. It’s a precise computational language, but it talks about the real world. There’s not a lot of boilerplate in LLM. Chat GPT is showing us, I think, an important piece of science. We’ve automated out the boilerplate. My guess is that increasingly as people use it for real, they’ll just edit the code. And it will have done a large part of the work in making the initial five lines of code. There are more regularities to describe meaning. It’s really a question of where the boundaries are between what the LLM can produce, what we can catch with our natural language understanding system. We’ve had billions of years to evolve, to deal with the way that nature is. Microsoft Research published a 154-page analysis of GPT-4 where they conclude, and it is in the title of their paper, they are seeing glimpses of AGI. The computational universe of possible things you can do is very big. We humans care about only a small fraction of that. The question is to connect those things that are out in the computational universe with things that we humans are interested in. In 1900, people would not have been surprised to think that space would be discrete. One of the things that I’m sort of hoping for in the not too distant future is we’ll actually find a phenomenon that is kind of like the Brownian motion of space and where we’ll be able to see, we can tell that it’s discrete.
Key takeaways
The tutorial is part of a personal side project focused on exploring generative AI tools.
To conclude, the Whisper model gave excellent results on all tested videos. Although it occasionally misidentified product or person names, I am quite happy with the outcome and will definitely keep using it.
On the other hand, the BART model offers a trustworthy open-source option for summarization. Its summaries are quite effective. I compared it to the T5 model from Google Research and BART’s summaries were superior. Indeed, it may not always capture all the key facts, but it delivers good results, so I’ll continue using it for my personal summary tasks.
Overall AI-generative solutions like Whisper and BART help me efficiently extract important insights from long podcasts and talks. This way I can stay informed even when I am running out of spare time.
I hope that you enjoyed the article.
Thank you for reading!
Don’t forget to subscribe if you want to get my future stories in your inbox.
If you enjoy reading my story and want to support me as a writer, consider signing up to become a Medium member and gain access to thousands of Data Engineering and Data Science articles.
Find me on LinkedIn and Twitter!
See my collection of Generative AI, MLOps, and Responsible AI articles





