
How To Add Chat History And Custom Metadata In Langchain QnA
Is Langchain capable of providing a good experience for Retrieval Augmented Generation (RAG) in performing Question and Answer (QnA) over a document, especially with their new documentation?

An example of the QnA interface that developers often adopt in such cases is a chatbot.
When users are provided with a chatbot interface, they will assume that the bot will be able to understand the context and communicate intelligently with them (similar to the experience provided by ChatGPT).
However, in my experience using Langchain, the Langchain RetrievalQA function (commonly used for QnA over documents) does not provide a way to ask questions with the chat history in mind.
Luckily, Langchain has updated its documentation for RAG, and now they give example how to do RAG and adding chat history in it.
You can read the detail documentation in here Add chat history | 🦜️🔗 Langchain.
Since Langchain already addresses the chat history aspect, I’d like to discuss how to perform QnA for custom metadata and also add external chat history in this implementation.
If you observe the current metadata in the example below, it only contains pagecontent, with no additional information.
Document(
page_content='LayoutParser : A Uni\x0ced Toolkit for Deep\nLearning Based Document Image Analysis\nZejiang Shen1( \x00), [cs.CV] 21 Jun 2021',
metadata={'source': 'example_data/layout-parser-paper.pdf', 'page': 0}
)This article will show to you, how to do QnA over document with added chat history and custom metadata.
Before we starting the coding part, here is the libraries setup that I used in my local machine.
langchain==0.0.353
langchain-community==0.0.7
langchainhub==0.1.14
openai==0.28.1
faiss-cpu==1.7.3
If you are ready, let’s started
Step 1. Prepare the Document
In this part, we need to prepare the document that we want to embed. In other words, this is the document from which we want to ask questions and get answers from it.
In our case, we need to ensure that metadata information is added for each document.
Below is what our document looks like:
from langchain.schema import Document
docs = [
Document(
page_content="A bunch of scientists bring back dinosaurs and mayhem breaks loose",
metadata={
"year": 1993,
"rating": 7.7,
"director": "Steven Spielberg",
"genre": "science fiction",
},
),
Document(
page_content="Leo DiCaprio gets lost in a dream within a dream within a dream within a ...",
metadata={
"year": 2010,
"director": "Christopher Nolan",
"genre": "science fiction",
"rating": 8.2,
},
),
Document(
page_content="A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea",
metadata={
"year": 2006,
"director": "Satoshi Kon",
"genre": "science fiction",
"rating": 8.6,
},
),
Document(
page_content="A bunch of normal-sized women are supremely wholesome and some men pine after them",
metadata={
"year": 2019,
"director": "Greta Gerwig",
"genre": "drama",
"rating": 8.3,
},
),
Document(
page_content="Toys come alive and have a blast doing so",
metadata={
"year": 1995,
"director": "John Lasseter",
"genre": "animated",
"rating": 9.1,
},
),
Document(
page_content="Three men walk into the Zone, three men walk out of the Zone",
metadata={
"year": 1979,
"rating": 9.9,
"director": "Andrei Tarkovsky",
"genre": "science fiction",
},
),
]Step 2. Custom Prompt to add metadata to the prompt
The following step involves modifications to the previous Langchain documentation. Here, we attempt to create one big prompt by combining all the documents we have into a single string, and formatting each document to follow the provided template.
The format_docs function plays the role of creating this large prompt. As a reminder, we also have a retriever function here. The retriever will play a role in selecting a document that has a similar value to our question, so not all documents will be used for each question.
from langchain.schema import format_document
from langchain.prompts import PromptTemplate
from langchain_community.embeddings.openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.chat_models import AzureChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
import os
os.environ["OPENAI_API_KEY"] = "Your_Open_AI_KEY"
os.environ["OPENAI_API_BASE"] = "Your_azure_endpoint"
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_VERSION"] = "2023-05-15"
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs, embeddings)
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
llm = AzureChatOpenAI(azure_deployment="<your_llm_model>")
def format_docs(docs):
template = PromptTemplate(
input_variables=["year","rating","director","genre", "page_content"],
template="""
<year>
{year}
</year>
<rating>
{rating}
</rating>
<director>
{director}
</director>
<genre>
{genre}
</genre>
<content>
{page_content}
</content>
"""
)
doc_strings = [format_document(doc, template) for doc in docs]
return "\n\n".join(doc_strings)
Step 3. Contextualize the chat history
While reading the documentation, I came across an interesting concept. Instead of listing the previous answer in the chat history, Langchain suggests reformulating the context from the previous answer as a question.
I believe this approach serves as a solution to the chat history issue when working with RetrievalQA.
Previously, when asking to clarify the previous chat, the RetrievalQA always required a similarity check in our vector store, as most of our clarification question will related to previous answer, the similarity check will not able to find the similar question in the vector store, it will return nothing. As a result, RetrievalQA would never work effectively with chat history.
Another observation I made is that Langchain has started to provide documentation using LCEL (LangChain Expression Language) rather than relying solely on functions.
You can see the use of this syntax, |in most of their documentation now. This approach offers better code readability, eliminating the need to be anxious about which input to provide for each function/class, as the output of one component will be fed as input to the next component. You can read a comprehensive explanation about LCEL below.
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
contextualize_q_system_prompt = """Given a chat history and the latest user question \
which might reference context in the chat history, formulate a standalone question \
which can be understood without the chat history. Do NOT answer the question, \
just reformulate it if needed and otherwise return it as is."""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
contextualize_q_chain = contextualize_q_prompt | llm | StrOutputParser()Step 4. Put everything together
Now let’s stitch everything together. I make a nice diagram to explained the flow of the code below.
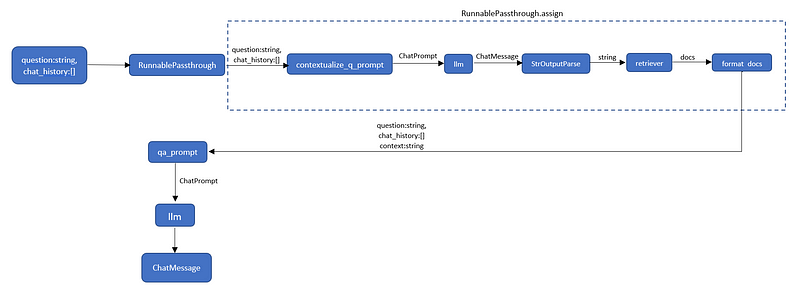
One of important point is the context variable, as we run using RunnablePassthrough.assign() we need to understand that this function will added new input to our first input.
Because we want the new input key name as context , we need to formulate the LCEL to looks like this context= contextualized_question | retriever | format_docs
At the end, we will get below new input after RunnablePassthrough.assign() syntax
{
context: "string",
question: "string",
chat_history: "string"
}qa_system_prompt = """You are an assistant for question-answering tasks. \
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
def contextualized_question(input: dict):
if input.get("chat_history"):
return contextualize_q_chain
else:
return input["question"]
rag_chain = (
RunnablePassthrough.assign(
context=contextualized_question | retriever | format_docs
)
| qa_prompt
| llm
)Now, after we finish with the code, we can start asking the question with this format
from langchain_core.messages import AIMessage, HumanMessage
chat_history = []
question = "any film with genre science fiction?"
ai_msg1 = rag_chain.invoke({"question": question, "chat_history": chat_history})
chat_history.extend([HumanMessage(content=question), ai_msg])
print(ai_msg1)
second_question = "who is the director of that film in 1993?"
ai_msg2 = rag_chain.invoke({"question": second_question, "chat_history": chat_history})
print(ai_msg2)It gave really good answer
#ai_msg1
content='Yes, there are three films with the genre of science fiction:\n\n1. A film from 1993 directed by Steven Spielberg about scientists who bring back dinosaurs, leading to mayhem.\n2. A film from 2006 directed by Satoshi Kon, which involves a psychologist/detective getting lost in a series of dreams within dreams.\n3. A film from 2010 directed by Christopher Nolan featuring Leonardo DiCaprio getting lost in a dream within a dream.'
#ai_msg2
content='The director of the 1993 film is Steven Spielberg.'Step 5. Add External Chat History
In step 4, we can asking the question directly yo user, but it’s not a good method. Imagine you have multiple user, how you can differentiate each user session and user chat history.
In this case external chat history, become very helpful.
I will use redis for my chat history storage, as it’s easy to install for our own PoC
You need to run this docker command in your machine to install redis
docker run -d --name redis-stack-server -p 6379:6379 redis/redis-stack-server:latest
When Redis is ready, now you can start implement the langchain code for RedisChatMessageHistory
from langchain.memory import RedisChatMessageHistory
history = RedisChatMessageHistory(session_id="Session_id_for_different_user", url = 'redis://localhost:6379/0')
def ask_with_redis_chat_history(question):
ai_msg1 = rag_chain.invoke({"question": question, "chat_history": history.messages})
history.add_user_message(question)
history.add_ai_message(ai_msg1)
print(ai_msg1)From above code, RedisChatMessageHistory needs 2 values
- session_id = String value to differentiate chat history for different user and different user, you can take control how you want to define it. When you want to access the chat history again you need to provide this session_id value
- url = The address to access your redis storage, if you installed in your localhost, you can access it using this value “redis://localhost:6379/0”
After that setup now, we can ask the question by passing our question as an input to ask_with_redis_chat_history(question) function.
ask_with_redis_chat_history("any film with genre science fiction?")
#answer
content='Yes, there are three films with the genre of science fiction:\n\n1. A film from 1993 directed by Steven Spielberg with a rating of 7.7. The content is about a bunch of scientists who bring back dinosaurs and mayhem breaks loose.\n\n2. A film from 2006 directed by Satoshi Kon with a rating of 8.6. The content is about a psychologist/detective who gets lost in a series of dreams within dreams within dreams, and Inception reused the idea.\n\n3. A film from 2010 directed by Christopher Nolan with a rating of 8.2. The content is about Leo DiCaprio getting lost in a dream within a dream within a dream within a ...'Follow up question
ask_with_redis_chat_history("who is the director of that film in 1993?")
#answer
content='The director of the film from 1993 is Steven Spielberg.'Hope this documentation can help you with your endeavor in this very interesting field.
I attached the python script for this documentation below




