
How the Dimension of Autoencoder Latent Vector Affects the Quality of Latent Representation
Hyperparameter tuning in autoencoders — Part 2

Introduction
The dimension of an autoencoder latent representation is important as it significantly affects the quality of latent representation. Today, I’ll visually show you this by running six different autoencoder models.
As I mentioned in a previous article,
The quality of the autoencoder latent representation depends on so many factors such as number of hidden layers, number of nodes in each layer, dimension of the latent vector, type of activation function in hidden layers, type of optimizer, learning rate, number of epochs, batch size, etc. Technically, these factors are called autoencoder model hyperparameters.
Obtaining the best values for these hyperparameters is called hyperparameter tuning. There are different hyperparameter tuning techniques available in machine learning. One simple technique is manually tuning one hyperparameter (here, the dimension of the latent vector) while keeping other hyperparameter values unchanged.
Today, in this special episode, I will show you how the dimension of the latent vector affects the quality of autoencoder latent representation.
The dataset we use
We will use the MNIST dataset (see Citation at the end) to build the autoencoder models here.
Approach
We will build six autoencoder models with different architectures in which we only change the dimension of the latent vector while other hyperparameter values in the models remain unchanged.
Here are the structures of the six autoencoder models that we’ll build today.
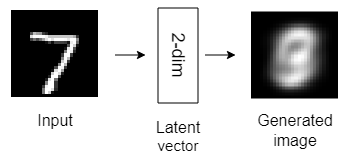
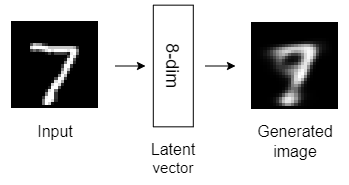
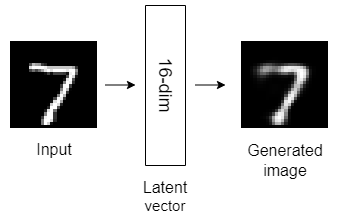
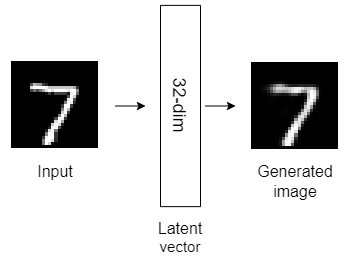
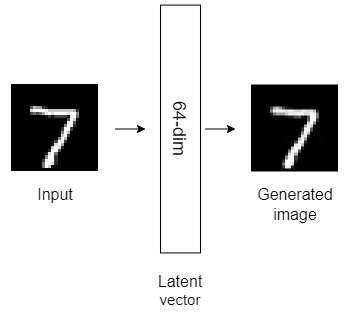
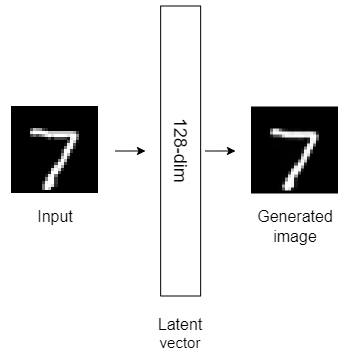
All the above autoencoder models have only one hidden layer with different dimensionality. Autoencoders with only one hidden layer are known as shallow autoencoders.
The only thing that we change in the above models is the dimension of the latent vector. We can create a list that consists of each dimension.
latent_vec_dim_list = [2, 8, 16, 32, 64, 128]We can iterate through this list using a simple for loop to create all six models and get all the outputs at once!
Create autoencoder models and get the outputs

It took about 13.5 minutes to execute the above code when using Google Colab with its free GPU. It took about 5.5 minutes to execute the above code when using Jupyter Notebook on my laptop with the NVIDIA RTX 3050 Ti GPU! It will take hours to execute the above code when running on the CPU only.
As the dimension of the autoencoder latent vector increases, the quality of the latent representation increases significantly!
Another special thing in the above output is that when the latent vector dimension is 128, the output is even better than the original digits with a 784 dimension. This is because the autoencoder model with a 128-dimensional latent vector has eliminated the noise in the input data.
The autoencoder latent vector consists of the most important features of the input data in a lower-dimensional form. But, it requires the right number of dimensions to accurately represent those features. Otherwise, it will fail to generate the required output.
The tf.keras.backend.clear_session()line of code is required to clear the history of the previous model when creating many models in a for loop. Otherwise, you’ll run out of memory or will get abnormal results due to clutter from old models and layers.
Note: If you want to build each model one by one and monitor the train and validation losses independently, download this .ipynb file that includes all the code samples you need!
This is the end of today’s post.
Please let me know if you’ve any questions or feedback.
Read next (Recommended)
- An Introduction to Autoencoders in Deep Learning
- How Number of Hidden Layers Affects the Quality of Autoencoder Latent Representation
- All episodes of my “Neural Networks and Deep Learning Course”

Support me as a writer
I hope you enjoyed reading this article. If you’d like to support me as a writer, kindly consider signing up for a membership to get unlimited access to Medium. It only costs $5 per month and I will receive a portion of your membership fee.
Thank you so much for your continuous support! See you in the next article. Happy learning to everyone!
MNIST dataset info
- Citation: Deng, L., 2012. The mnist database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine, 29(6), pp. 141–142.
- Source: http://yann.lecun.com/exdb/mnist/
- License: Yann LeCun (Courant Institute, NYU) and Corinna Cortes (Google Labs, New York) hold the copyright of the MNIST dataset which is available under the Creative Commons Attribution-ShareAlike 4.0 International License (CC BY-SA). You can learn more about different dataset license types here.
Rukshan Pramoditha 2022–09–08




