
How RAG will change with Multi Modal LLM and Generative AI Introduction
Problem Statement
So, RAG is pretty 2023, and with the availability of GPT4 vision models, we are talking about multi-modal RAG. What needs to be considered now, what changes we might encounter and what new updates we need to focus on for this multi-modal LLMs is covered as part of this blog. My focus for this blog is to consolidate some of the “asks” from my customers with some new use cases around multi-modal LLMs and publish them as thoughts and patterns. Some of these patterns are little futuristic and might be art of possible with the multi-modal RAGs.
So, let us dive into the RAG for multi-modals.
Solution
The multi modal LLMs give us more power. There were many projects in the past where infographic information like bar charts and pie charts that contained tons of content and materials were simply ignored coz we did not had the means (or the means was expensive and not time to material conducive) to decipher and use the knowledge to power our applications. Now, with the arrival of multi modal LLMs (we will be discussing with GPT4 Vision)- we have the option to extend our existing RAG based solutions and make them even better!
Although multi modal LLMs have opened up new use cases and options which I might discuss in a separate blog. In this one, I am focussing on RAG itself (hence the title). For RAG based solution in LLMs, below are some of the patterns emerging on how these text and images can be combined.
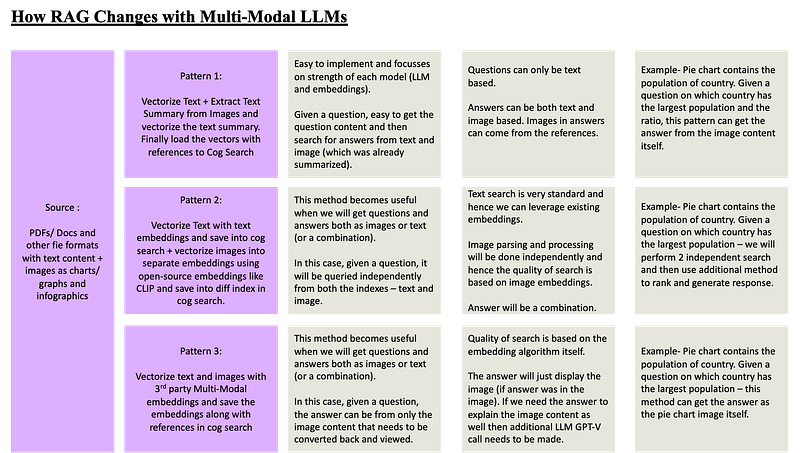
There are 3 clear patterns — (I am sure we can come up with more), but for now lets discuss more on these 3.
Imagine a use case where we received 100s of files of varied formats. The formats can be PDFs or DocX or similar etc. Now the content of the files have images ( not OCR data but info graphics like bar charts or graphs or even images that have maps and overlays etc.), our responsibility is to educate our RAG application to learn on the knowledge from these documents that include the text as well as images.
We have 3 implementation patterns we can adopt. It is too early to tell which one is better coz each one works well based on specific scenarios.
Pattern 1 is where I feel most of the existing RAG can benefit without any disruptive changes. In this case we extract the images from the documents into an isolated landing area. We build and run execution process that can load each image at a time and process them using GPT4 vision model to extract content, summary, synopsis and key value pairs as text blob. Once the information is available we can use existing embedding models to convert text into vectors to be stored into cognitive search ( or any other vector DB). When the application is invoked by the users ( or system), the question is converted to embedding ( or we can do advanced similarity search on question) and used for search against the vector database. The results will be either content from the text or the image ( text synopsis of the image ). For generating the response, we can pass the content itself or if we have added reference of the image to the image synopsis then we can also retrieve the original content and display image.
One of the downside of this approach is that we can only ask questions as text.
For pattern 2 – we have a hybrid option. In this case, we build 2 indexes ( again minimum disruption)- one we build with text embeddings using the usual models and save in existing index. The other is where we use a multi modal embeddings ( like CLIP) to vectorise the image itself and save in a separate index. Once the application executes and someone asks a question, either providing a text question or image uploaded as question; either way the question can be converted to an embedding ( based on type) and used to search across both the indexes to gather possible answer and finally using LLM to generate response.
The third and final pattern is a bit disruptive but this will become the standard process soon as more and more companies will implement their own multi modal embeddings model. In this case – we build a single index. The index will contain both the text and image embeddings. We run 2 pipelines – one to process the text where the text content is embedded with multi modal embeddings like CLIP and stored in vector database with references and links. The second pipeline is exactly same as first one (with multi modal embeddings etc) except that instead of text we process images and load them into the vector DB. Once all the data is loaded then any question asked ( image or text based) will be first embedded and then used to perform a search against the single index that has all the embedded data now . The result then can be used as a context and used for response generation.
Conclusion
Multi Modal LLM based RAGs are making things interesting. As this is an evolving space and I am sure more patterns will evolve and new options will change the landscape. I will keep updating this blog as I learn more and publish some pros and cons of these options. Do add your comments and your suggestions below.





