
How Organizational Data Strategy needs to change with GenAI and Large Language Models (LLMs) in mind.
Problem Statement
Data Strategies and Data Management are heart of any data oriented organization. Companies have spend years to build and mature their data strategies. Most of the data strategies have been very analytical till now. With the implementation of large scale data lakes and lake houses, we have mastered the art of managing structured data for analytical purposes.
GenAI brings with it new challenges, we as organizations have not totally focussed on unstructured content (and rightly so) till now — mostly coz of the lack of analytical capabilities these unstructured content provides. However, with the arrival of LLMs, everything changed. Now, just having a analytical data strategy will not suffice. We need to bring in “enterprise data strategy” which focussed on all kinds of data. And going by statistics, maybe only 10% of organizational data are analytical, which means we need to figure out how to solve the data strategy for the rest of 90% of data locked in as information/ knowledge within these enterprise repositories of data.
Over last few weeks, I had many a conversation with my customers, leaders of AI and Gen AI companies and also from various professors from academia. Based on these 1–1 discussions, I plan to provide my 2 cents on a series of questions regarding “how GenAI will shape the Data Strategy Landscape”. Even though this blog is designed as a question/ answer based blog, but this will cover the technical details and blueprints of the data management for GenAI in details.
Solution
Let us formulate the answers through a series of questions. That way I can translate my 1–1 discussions and observations into a logical sequence of processes.
Question 1: Customers have spend 5–7 years shaping and re-shaping the data-lakes and lake houses, does that mean we have to do a “do over” with GenAI?
- No, not at all. Data lakes were build for a specific purpose- for gathering and implementing business insights and values from structured (mostly) & analytical data. GenAI cannot replace the analytical workloads that is powered by deterministic and probabilistic (based on structured data) processes/jobs. For those workloads and more we still need data lakes and we need them to be even more matured (like adoption of data mesh and building organization wide data products etc.). Also enterprise wide business processed that are powered by GenAI also needs to use structured analytical data (along with unstructured knowledge). So, in future, projects will mostly be powered by both data lakes and knowledge repos.
Question 2 : You just mentioned knowledge repos in the same breadth as data lakes- what do you mean ?
- Data lakes store mostly structured data. The lake house architecture wants us to organize data into Bronze->Silver->Gold. In this kind of structure, we need to extract information from raw datasets and save structured content into the silver and gold zones. For pure unstructured content which needs to be processed by large language models, we don’t have to pre-process data all the time. However, for unstructured content, we have separate challenges. For example, how to search content from vast sea of unstructured content and build context (more of this later). But unlike data lake where extraction and organizing data was critical, for unstructured data, search is critical. Now, lake-houses and even the data warehouses (which is typically the Gold zone) does not support these text search based on numerical representation of data ( aka embeddings). So, we need special databases where we can store all unstructured content with the capability of search on these embeddings. Hence Knowledge repository is typically a combination of special databases which can store numerical representation of unstructured content (text/ images etc.) along with the ability to search these contents. We typically represent these knowledge repositories as vector stores. In some cases, we might need the ability to organize the content into relationship, but more of those later too!
Question 3: We have invested in Bronze->Silver->Gold data lake house architecture, how will this change with the Unstructured content and LLMs
- See below.
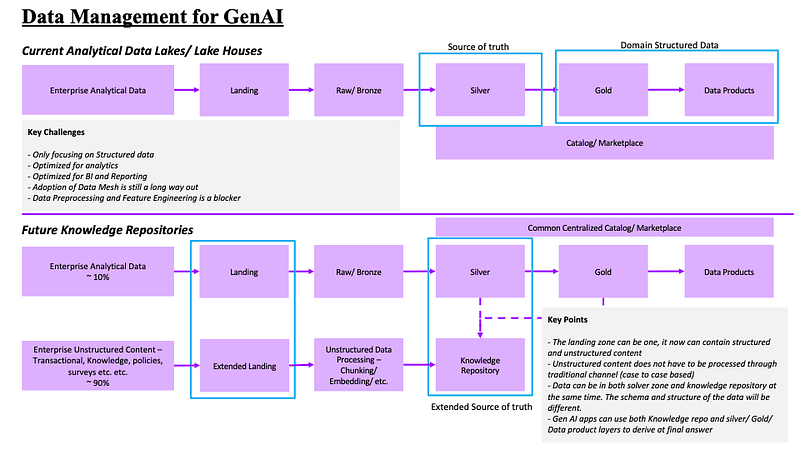
- The above image is a representation of how things might be different as well as similar. Let me explain. Organizations having the lake house architecture will currently face new issues with the arrival of new applications which are powered by the unstructured content through LLMs. Issues will pertain to lack of organized way to store and process unstructured content, to lake houses not being optimized for search, to lake houses only optimized for BI and Reporting but not search and retrieval, to lack of single source of truth and silos of data across business domains, to challenges in adoption and time to market due to engineering heavy requirements of feature engineering and analytics. To overcome some of these challenges, we have below recommendations. Step1 — extend the landing zone, for lake houses, all files used to land as is into the landing zone, we can keep the same zone and just extend the same to house unstructured file content as well — like the PPTs and PDFs etc. Step2- is where things change a bit. In lake houses, the movement of data from landing to RAW (Bronze) and Curated (Silver) used to happen through Data Quality/ Data Standardization/ Data Augmentation and Data Enrichment process. In the new world, we should focus on horses for courses. When a PPT file reaches landing zone, then 2 different processes can work on the same file. First — an unstructured file processor can extract content (text, images, handwriting, tables etc.) from the file and then chunk (slide the content into smaller and manageable text blobs) them up to be saved into Knowledge repository; Second( and only if it is needed for this dataset and there is a definitive use case) — another file / data processor that can extract entities, relationships from the text content and then use the engines (rules, data quality, augmentation etc.) to save the extracted content (it is no longer extracted text bit we converted the text to information now) into Curated/ Silver zone. In a nutshell, structured data processing does not change a bit but for unstructured data, we need a pipeline to load text into knowledge repository and at the same time (only if use case permits), load extracted data content (not text) using existing analytical processes into silver / curated zones.
Question 4: What happens to the data products and Gold zones.
- Data Products are specific data assets that have a special purpose. They represent a single source of truth within a business unit and organization. They have processed and analyzed data content. Now, within the realm of LLMs and LLM powered applications, we typically face multiple use cases which needs answers from these analyzed and pre-processed content. Use cases like “next best action”, “best deals and offerings”, “churn prediction” etc. needs content from both the unstructured Knowledge repository and structured processed data. So, in all reality, the LLM powered application will really be powered by contents from knowledge repository and processed sources like Silver data assets, Gold data assets and Data Products. From the diagram above, the source of truth which was the original Curates/Silver zone of data is extended to host unstructured chunked contents. Further, if you see, the dotted lined from Gold and Data products into the knowledge repository was intended to show that the “whole” of knowledge is stored as a combination of structured and unstructured content. Lastly, just to re-iterate, the extended silver zone containing the structured data and unstructured text does not have same information even if they sometimes can be derived from same file. (for more details of these use cases, check my other blogs with same name !)
Question 5: What is special unstructured data onboarding
- The question can be best answered by 3 key points. What does data loading into knowledge repository means; why is search important and how does users search the knowledge in the knowledge repository; and finally how is retrieval achieved for converting content to context. The below diagram provides a quick view of all the 3 capabilities. In general, the data loading for unstructured needs independent processes and jobs which can have the ability to handle and process data from multiple sources and multiple formats. The search is also associated with the accuracy of extracting the right piece of information for a given question. Finally, how and who can retrieve what kind of data and what permissions are available for fetching the right content is critical to powering the right LLM application.

Question 6: So do I design a centralized Knowledge repo or a federated one.
- Tough question. Answer is both — based on maturity, skills, organization size etc. Let us dive in. In an ideal world, we should have a single source of truth across the organization. The knowledge repository should be centrally managed and federated-ly “owned”. In this kind of hypothetical scenario, the organization should be matured to an extend where there is a core engineering team with unlimited capacity who can prioritize every request from every business unit to load a new data source into the central knowledge repository through proper discovery (so that the data is not available in knowledge repository etc.), tagging, fingerprint and other details so that the knowledge repository does not have conflicting information. Similarly, when users get response/ result from the central knowledge repository, the results should be based on the user persona and what permissions he/she has to view data from cross domain regions etc. There are many a reasons why this centralized knowledge repository is a hard problem to solve. However, I have seen both types of customer who started their journey with the intention of building a truly centralized knowledge repository VS others where they start the GenAI journey with one or two business domains with the promise of merging these siloed knowledge repositories soon.
Conclusion
This is just the tip of iceberg. I will keep adding more content and details in this section. Do check out more of my blogs and leave a comment if you like the content.
Check some of the blogs which are relavant to this topics -





