

How NLP has evolved for Financial Sentiment Analysis
Do we still need humans to read boring financial statements?
Machine learning models aim to learn a good representation of its input data to perform its task. The way models learn to represent words with Natural language processing (NLP) has evolved in recent years, and in this article, we explore the notable changes in how models understand language to make financial decisions.
We focus on a direct application of NLP to financial markets: Automate sentiment classification of a text document to make fast and accurate investment calls that are free of human bias.
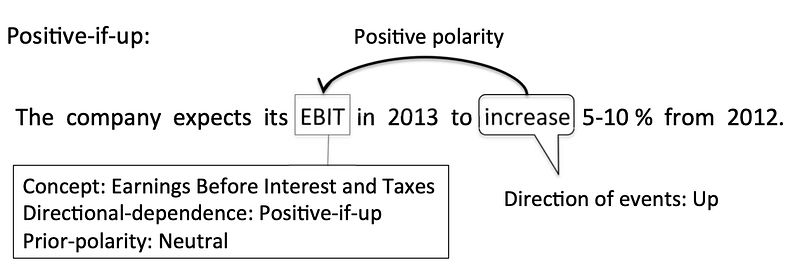
For us to compare meaningfully across the technology shifts, we use a Financial Phrase Bank[1] that contains labelled financial phrases (example below):
Bag-Of-Words/Lexicon Methods

If we wanted a 8 year old to interpret the phrase above, we could give her a list of words with positive, neutral and negative labels, and ask her to tell us if the text contain any of those words — that is essentially what a lexicon method is. The most popular financial lexicon is the Loughran Macdonald dictionary[2]. If you are interested to try it out, use this code snippet that runs pretty quickly.
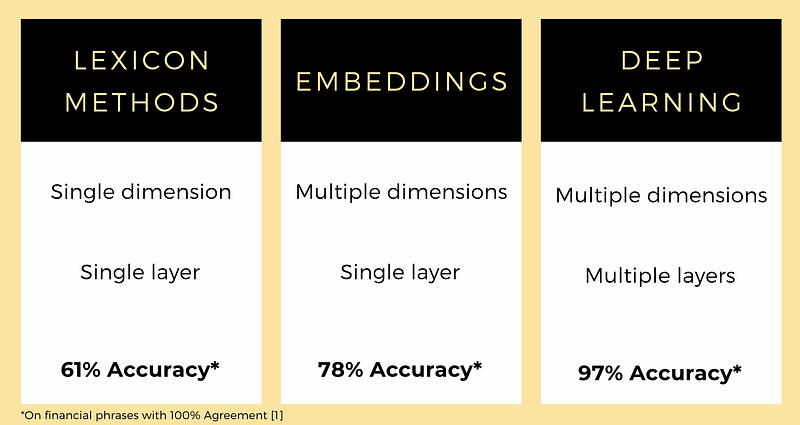
Overall accuracy using LM is not great — 61% [1]. So even though we can classify a text sequence quickly and understand why we classify them, we are heavily reliant on the words having a place in the dictionary. And even then, the words only have 1 dimension. Perhaps we will have better results representing every single word in a higher dimension, say 300?
Embeddings
Embeddings take each word in a sequence and project them into a multi-dimensional space. We can think of embeddings as a wide lookup table — We have 300 columns with the words acting as the lookup index.

The SOTA embeddings is likely ELMO’s[2] contextual embeddings, i.e. embeddings that take into account the word and its surrounding context. The embeddings has three components: two are from bi-directional contextual representations and one is a context-independent representation.

The embeddings by themselves are just representations — that alone cannot classify sentiment. So we have to train a model that uses the embeddings as inputs and learns to predict sentiment. I couldn’t find any papers that tested on the phrase bank, so I did a quick experiment here.
Side: Wasn’t as quick as I thought — tensorflow/keras is much more iffy/painful than I remember. In the end I took the embeddings from a plug and play library called pymagnitude and used my trusty ol’ random forest.
Overall accuracy went up to 78%. Higher than LM dictionary, but still not fantastic. Embeddings are able to create multi-dimensional representations from words, but even if the embeddings are contextual, it is only a single layer of representations, no matter how big the dimensions are. It is time to explore a multi-layered representation with high dimensions, i.e. deep learning.
Deep Learning

Recent advancements in architecture and training methods have greatly improved the way deep learning models are able to learn language and perform downstream tasks.
The transformer architecture and BERT[4] need no further introduction — refer to this great article to learn more — but in short, the use of self-attention and token masking allows a truly bi-directional contextual relationship to be learnt.
The use of transfer learning in NLP was first introduced in ULMFiT[5], where a network first learns to predict the most probable word from a huge corpora of text, and then performs other tasks using the pre-trained weights from language modelling — this has led to improvements in convergence and reduced the need for a huge labelled dataset.
There is a nice paper, FinBERT, that applied BERT and transfer learning to the phrase bank and achieved 97% accuracy! Btw, if you’re interested to see how you can use FinBERT to trade on corporate filing sentiment, I made a video that brings you through the entire process from parsing the filings to backtesting the results!
What’s Next?

So are we done? Can machines analyse financial documents and churn out accurate and objective sentiment while we sip on our martinis? Do we no longer need human analysts to pore through reams of financial statements and be on the constant alert for Bloomberg headlines?
Not quite.
There are practical limits in current BERT models, like the quadratic increase in computational cost with input length — the maximum input length usually caps at 512/1024 tokens. Reformer and Longformer are recent papers that try to solve it by simplifying the self-attention mechanism.
Also, BERT cannot do mental sums — it only contains text representations. This is a major bottleneck for machines to fully understand and analyse financial documents which typically contain lots of numbers. I found a paper that tries to augment BERT with a program to do basic math — but it’s likely a long wait before BERT can perform human level reasoning. **Update: GPT-3 released by OpenAI is able to do zero-shot calculations without being trained beforehand!
Most importantly, financial text can be ambiguous and often require contextual knowledge that text alone cannot provide — the high accuracy achieved by BERT was on phrases that had 100% agreement among human annotators. The other phrases that even humans disagree on makes it very unlikely that machines will trump human analysts. More likely, a quantamental approach will dominate the markets, where financial analysts are augmented with machine learning to make accurate, fast and objective investment decisions.
What do you think is next for financial sentiment analysis? Leave a comment.
[1] Pekka Malo, Ankur Sinha, Pekka Korhonen, Jyrki Wallenius, and Pyry Takala. 2014. Good debt or bad debt: Detecting semantic orientations in economic texts. Journal of the Association for Information Science and Technology 65, 4 (2014), 782–796. https://doi.org/10.1002/asi.23062 arXiv:arXiv:1307.5336v2
[2] Loughran, T. and Mcdonald, B. When is a liability not a liability? Textual analysis, dictionaries, and 10-Ks. The Journal of Finance 66, 1 (2011), 3565.
[3] Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018a. Deep contextualized word representations. In NAACL.
[4] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
[5] J. Howard and S. Ruder. Universal language model fine-tuning for text classification. Association for Computational Linguistics (ACL), 2018.




