
How I Extract Data From My Medium Stories
Accessing stats from my stories to discover what works and what doesn’t

The stats page on Medium is decent, but as a data lover, I want a way to export all that data for further analysis.
Luckily, that’s possible with a few manual steps.
Let me show you how.
Step 1: Go to stats and select a story
First, you choose a story of interest on your stats page. When you do, you only see the data from the current month, but you can change that using the monthly dropdown.
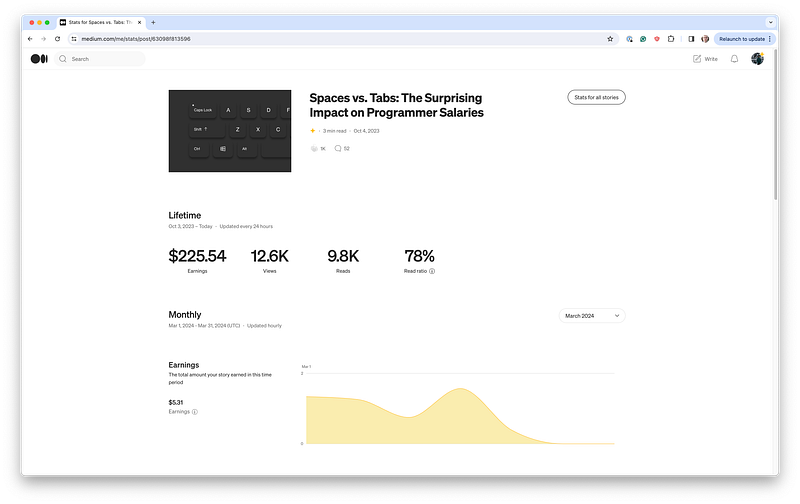
Next, you open the developer tools (for example, by right-clicking anywhere on the page and clicking inspect).
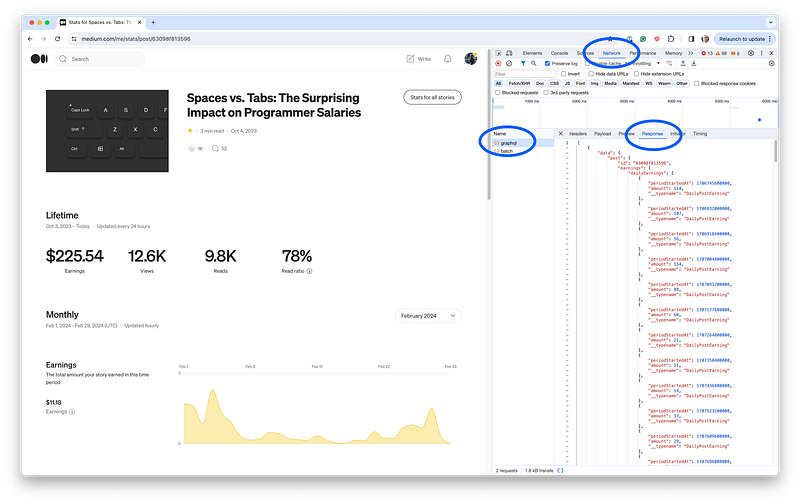
If you change the selected month and go to Network → GraphQL → Response, you can see the JSON data from the server.
I have a folder for each story I want to look at, and I create a JSON file for each month, as shown in the screenshot below.
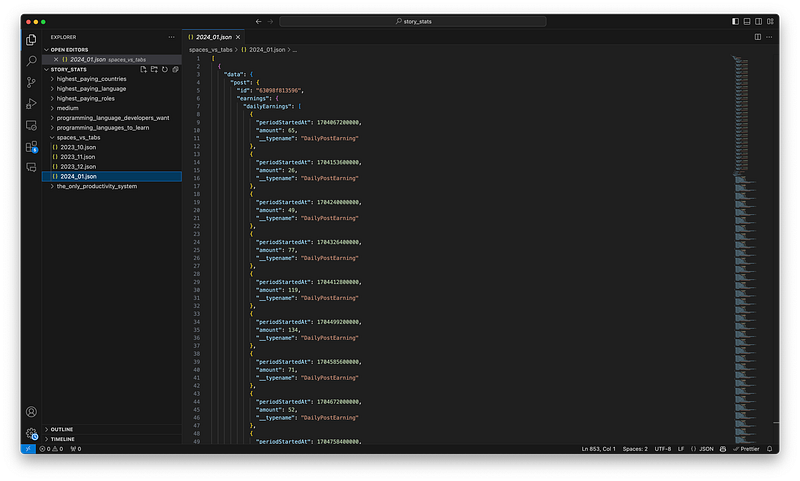
It’s a bit too manual, but it’s good enough since historical data doesn’t change.
Step 2: Reading the data in Python
I use Python to look at the data, and the first step is to utilize the following function that lists all JSON files in my story folder.
def get_files(story_folder):
files = os.listdir(story_folder)
files = [f for f in files if ".json" in f]
files.sort()
return filesI have one function to structure the earnings from the JSON data that looks like this.
def get_earnings(data):
earnings = data["post"]["earnings"]["dailyEarnings"]
earnings = [(
str(pd.to_datetime(e["periodStartedAt"], unit="ms").date()), e["amount"]
) for e in earnings]
return earningsAnd one that works for all other stats.
def get_stats(data):
stats = {}
for d in data["postStatsDailyBundle"]["buckets"]:
date = str(pd.to_datetime(d["dayStartsAt"], unit="ms").date())
if date not in stats.keys():
stats[date] = {"member": {}, "nonmember": {}}
stats[date][d["membershipType"].lower()] = {
"readersThatRead": d["readersThatReadCount"],
"readersThatViewed": d["readersThatViewedCount"],
"readersThatClapped": d["readersThatClappedCount"],
"readersThatReplied": d["readersThatRepliedCount"],
"readersThatHighlighted": d["readersThatHighlightedCount"],
"readersThatFollowed": d["readersThatInitiallyFollowedAuthorFromThisPostCount"],
}
return statsI call these three functions using the following primary function, which returns a dictionary with all the data for that story.
def get_story_stats(story_folder):
files = get_files(story_folder)
story_stats = {}
for file in files:
with open(story_folder + file) as f:
data = json.load(f)[0]["data"]
story_stats = {**story_stats, **get_stats(data)}
for date, amount in get_earnings(data):
story_stats[date]["earning"] = amount
return story_statsHere’s what it looks like in my Jupyter Notebook.
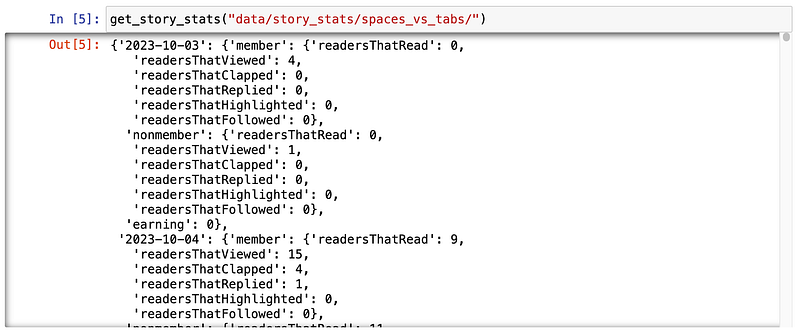
Now, I run my analysis or create a data visualization.
Example: Visualizing my story data
I will cover the code for creating my story data visualization in another post, but here’s what it looks like.
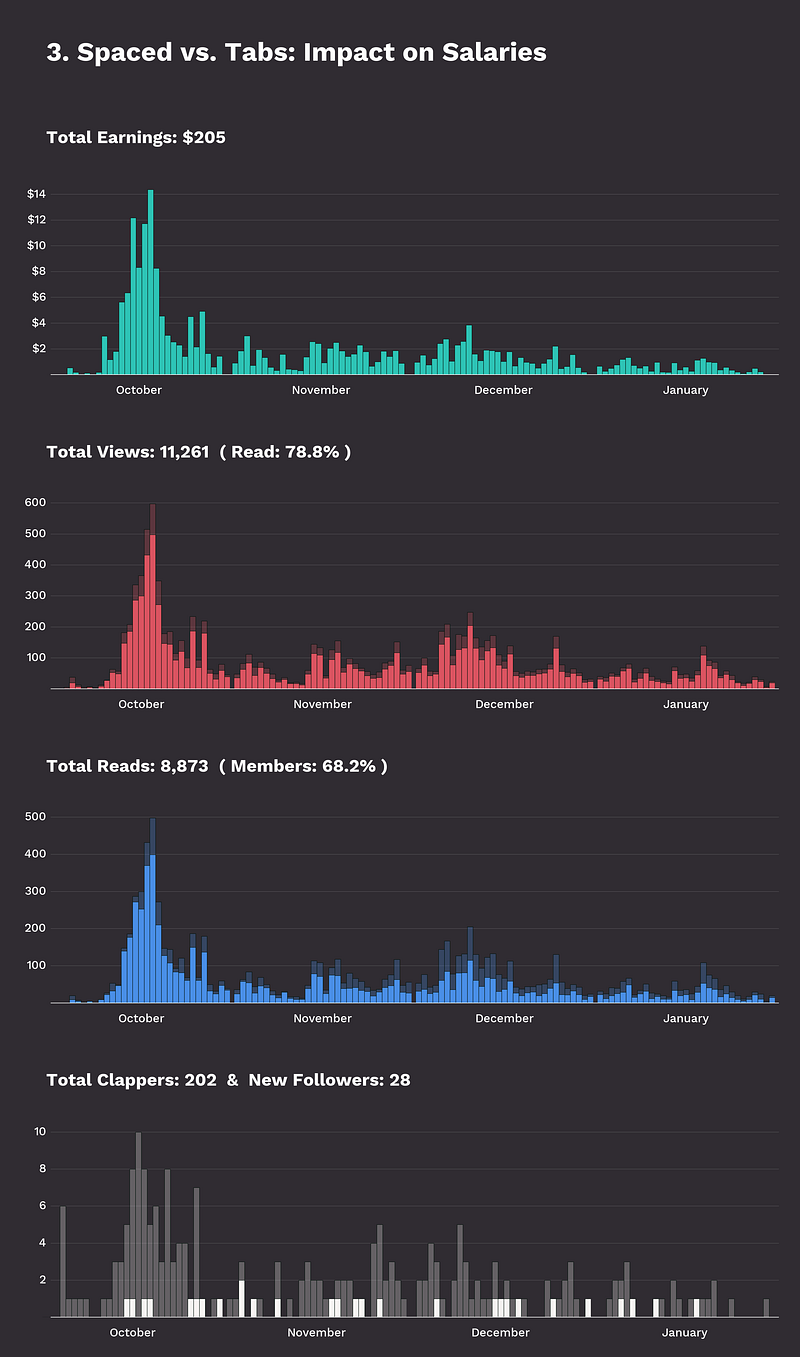
I have created visualizations like this one for my most successful stories, allowing me to detect patterns and differences quickly.
Conclusion
With a few minutes of manual labor, you can extract data from your stories quickly (until there’s a better alternative).
With access to raw data, you can better understand why some of your stories perform better than others.
And you can create beautiful data visualizations that tell you everything you need to know in one look.
Also,
I’m learning about technology, entrepreneurship, and online content creation. It’s a lot of fun, and if you agree, you should have a look at my Free Newsletter! 😄