

How EMO turns audio into a realistic talking head
Turning audio into expressive talking portraits
The ability to create realistic synthetic talking head videos from a single image and audio has a lot of crazy potential in the world of AI. While major strides have been made with computer graphics and 3D modeling, generating fully authentic and expressive human facial animations from audio and a picture alone remains an elusive challenge.
However, a newly released paper has, I think, redefined what’s possible in this space. The implementation, called EMO, demonstrates that AI-based techniques can produce remarkably vivid talking head videos that capture the nuances of human speech and even singing.
In this article, we’ll see how it works and what you can create with it. Let’s begin!
Subscribe or follow me on Twitter for more content like this!
The Quest for AI-Generated Faces
Synthesizing photorealistic videos of human faces has been an active area of research for decades. Early work focused on 3D modeling and computer animation techniques. More recently, deep learning methods like generative adversarial networks (GANs) have shown prowess at creating completely artificial but convinving human portraits (I have an article on how to use a GAN to enhance an old picture here).
However, generating video of a believable virtual human that moves and speaks naturally is immensely difficult — even models like Sora don’t do this yet. Unlike static images, talking head videos require maintaining the person’s identity, precisely syncing lip movements with the audio, coordinating intricate facial muscles to form expressions, and simulating realistic head motion across potentially thousands of frames.
Previous deep learning systems have made impressive progress but fall short of human-level authenticity. Methods based on 3D morphable face models or datasets of facial landmark motions often produce results that look obviously synthetic. Direct video generation techniques that bypass 3D modeling have trouble maintaining consistency across long videos. The subtle dynamics of personal mannerisms, emotional expressions, and enunciation remain out of reach.
This difficulty motivates research like EMO that aims to unlock the full expressiveness of the human face using AI. Successfully doing so would enable a ton of applications in entertainment, telepresence, and social media.
Related reading: How Sora (actually) works
The EMO System
EMO represents a new milestone in AI-generated talking head videos (you should check out all the examples on the project site here if you haven’t seen them). It demonstrates that given sufficient data and an appropriate algorithmic framework, an AI system can begin to replicate the intricacy of human vocalizations in facial animations
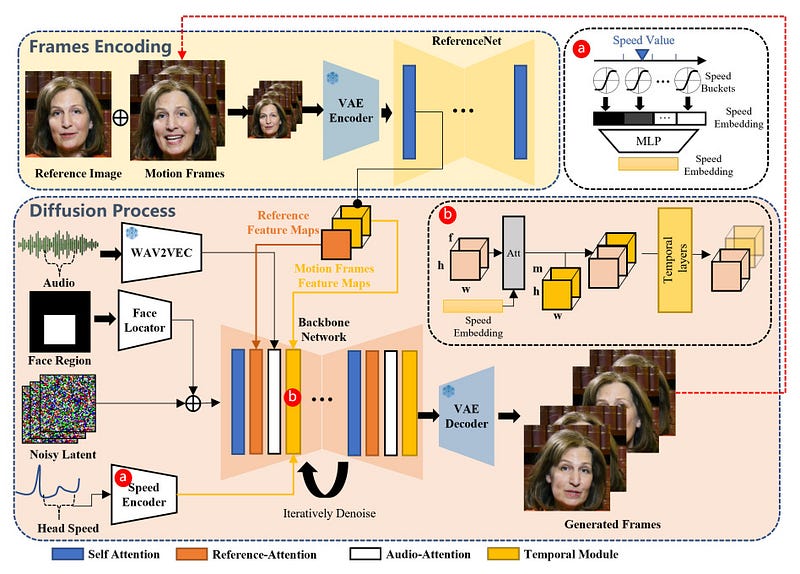
At the core of EMO is a deep neural network trained using a technique called diffusion models. First developed for image generation, diffusion models have proven remarkably effective at creating highly realistic visual content. They work by taking noisy inputs and iteratively denoising them into pristine outputs. When conditioned on textual descriptions, they can produce images that strongly match the text prompt.
The key insight is this: EMO adapts diffusion models to video generation by conditioning them on audio data rather than text. The system tries to reverse-engineer the facial motions that synchronize with and express the corresponding sounds. This allows generating videos directly from audio without predefined animations.
The neural architecture incorporates key components that together enable creating stable, identity-preserving videos:
- An encoder that analyzes acoustic features related to speech, tones, and rhythm from the input audio clip. This drives generation of motions like mouth shapes and head poses.
- A reference encoder that captures the visual identity of the person in the input image. This person’s likeness is preserved throughout the generated video.
- Temporal modules that help maintain smooth transitions between video frames and fluid motions over time.
- A facial region mask that focuses detailing on core face areas like the mouth and eyes.
- Speed control layers that stabilize the pace of head movements across long videos.
Training on a massive labeled dataset of talking head videos containing 150 million frames in diverse styles gives EMO exposure to the myriad intricacies of human speech, song, accents, tones, and mannerisms crucial for photorealistic results.
Performance
In evaluations against other state-of-the-art talking head models, EMO demonstrated superior performance on multiple metrics:
- Realism: The quality of individual frames as measured by Fréchet Inception Distance was significantly better.
- Expressiveness: EMO’s facial animations were rated as more vivid and human-like based on expression modeling.
- Lip sync: Audio-visual alignment was competitive, with convincing mouth shapes matching the sounds.
- Consistency: Videos flowed smoothly over time, maintaining identity and natural expressions as assessed by Fréchet Video Distance.
User studies found EMO capable of producing highly convincing talking head videos of people engaged in speech or song with intricate mouth movements and appropriate emotional affect in their facial expressions.

“The qualitative comparisons with several talking head generation works.” — from the paper
Remarkably, it worked for illustrated faces in addition to photorealistic ones, synthesizing anime characters speaking with the same audio clip in a consistent style.
Limitations and Future Work
While a major advance, EMO represents just one step forward in replicating human facial motions. Some limitations provide opportunities for improvement:
- Generation speed is relatively slow due to computational complexity.
- Strange artifacts like random gestures sometimes occur.
- Subtle quirks of individual mannerisms and expressions are not fully captured.
- Modeling vocal nuances like breath, laughter, yawning remains difficult.
Addressing these limitations could involve training larger models, developing better conditioning techniques, and incorporating additional modalities like text for greater contextual grounding.
Nonetheless, EMO exemplifies the rapid progress in realistic human synthesis using AI. It demonstrates that given enough data and compute, neural networks can begin to decode the intricacies of facial expressions and motion from audio. Such innovations point to exciting possibilities for interactive AI avatars, visually engaging videogame characters, and personalized talking head applications.
Subscribe or follow me on Twitter for more content like this!





