
How does Adaptive Query Execution fix your Spark performance issues?
In Spark versions before 3.0, the common performance issues encountered are:
- Data skewness, inadequate partitioning, causing uneven distribution.
- Suboptimal query plan choices, where Spark might choose a static plan without considering runtime statistics, leading to inefficiencies.
- The lack of adaptability in handling varying data sizes between stages poses another performance hurdle.
These issues are now fixed with the help of Adaptive Query Execution (AQE), which we’ll discuss in detail in this article.
What’s Adaptive Query Execution (AQE)?
Before Spark 3.0, a notable downside was that once the best-optimized plan was determined, no further optimization could be performed until the end of the Spark application. This limitation hindered the ability to adapt and improve execution dynamically during the application’s runtime. However, since Spark 3.0, it has become possible to perform runtime optimization with the help of AQE.
In the short term, AQE is an optimization technique in Spark SQL that utilizes runtime statistics to choose the most efficient query execution plan.
This feature is enabled by default starting from Apache Spark 3.2.0.
How Does AQE Perform Optimizations?
The AQE feature provides three techniques to tackle the issues mentioned in the introduction. It achieves this by applying the optimization techniques below:
- Dynamic Coalescing of Shuffle Partitions
- Dynamic Handling of Skewed Joins
- Dynamic Switching of Join Strategies
Let’s explore these techniques in detail.
1. Dynamic Coalescing of Shuffle Partitions
What’s the issue?
When dealing with large datasets, shuffle operations significantly impact performance due to the necessity of redistributing data across the network. Shuffling is costly, involving the movement of data to fulfill downstream operator requirements.
The number of partitions in the shuffle is a crucial factor, but determining the optimal number is challenging due to varying data sizes between stages and queries.
- Too few partitions lead to large partition sizes, potentially causing disk spills and slowing down queries.
- Too many partitions result in small partition sizes, leading to inefficient I/O patterns and an increased burden on the Spark task scheduler.
The issue is how to determine the right balance for efficient query execution.
How the issue is fixed?
First, we start by enabling the two parameters spark.sql.adaptive.enabled=true and spark.sql.adaptive.coalescePartitions.enabled=true.
To tackle this problem, a practical solution is to start with a higher number of shuffle partitions. As the application runs, the approach involves merging adjacent small partitions into larger ones, guided by shuffle file statistics.
The following example shows two partitions with the same size (P0 and P2) and two patitions with a small size (P1 and P3).
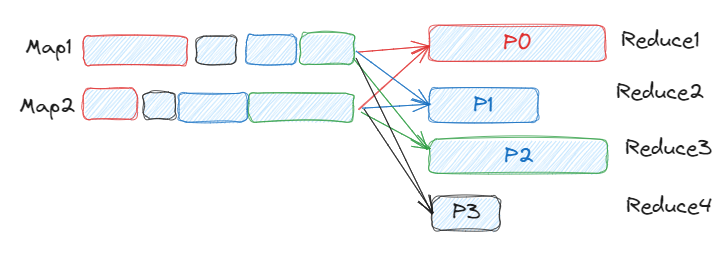
Once we enable the AQE with coalesce partitions, we'll get three partitions of the same size.
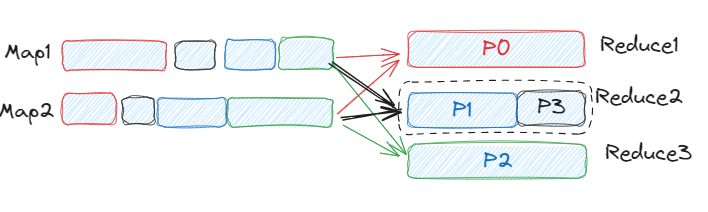
2. Dynamic Handling of Skewed Joins
What’s the issue?
The Skewed Joins deals with a well-known issue related to Data Skew. Let’s briefly recall what is this issue.
Data skew refers to uneven or asymmetric data distribution. As depicted in the image below, all the data is concentrated in one partition (or some partitions). This can severely downgrade the performance of join queries, as all other executors remain idle while only some executors will work.
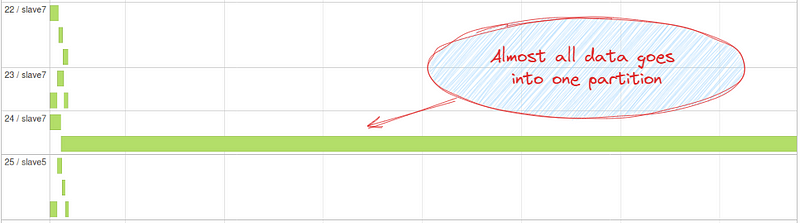
How the issue is fixed?
This functionality effectively addresses skew in SortMerge Join by dynamically dividing (and replicating when necessary) skewed tasks into tasks of approximately equal size. For instance, the optimization involves breaking down excessively large partitions into subpartitions and subsequently joining them with the corresponding partition on the other side of the join.
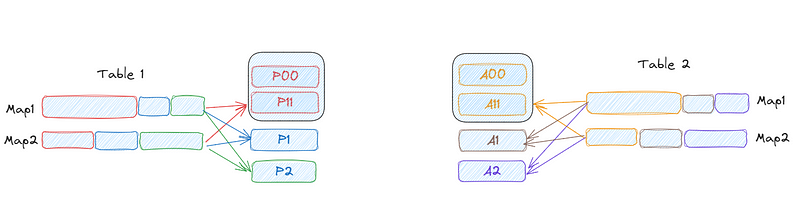
As we can observe in the image below, the partitions P0 and A0 in tables Table 1 and Table 2, respectively, are large, indicating data skew.
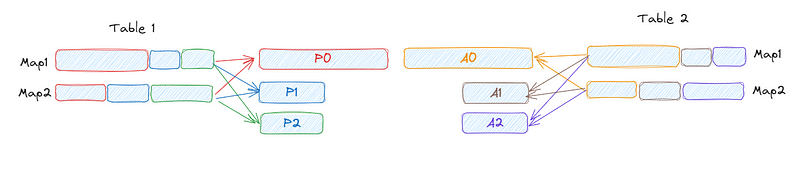
When enabling the two parameters spark.sql.adaptive.enabled=true and spark.sql.adaptive.skewJoin.enabled=true, AQE's skew join optimization automatically detects skew from shuffle file statistics. It evenly repartitions the data, resulting in the partitions below, where we have eight partitions of equal size.
3. Dynamic Switching of Join Strategies
What’s the issue?
Spark offers various join strategies, with Broadcast Hash Join often being the most efficient when one side fits well in memory. To determine whether to plan a broadcast hash join, Spark estimates the size of a join relation and compares it to the broadcast-size threshold. The parameter used to set the threshold is spark.sql.autoBroadcastJoinThreshold and the default value is 10MB. However, inaccuracies in size estimation, such as selective filters or complex operators, can lead to suboptimal plans.
How the issue is fixed?
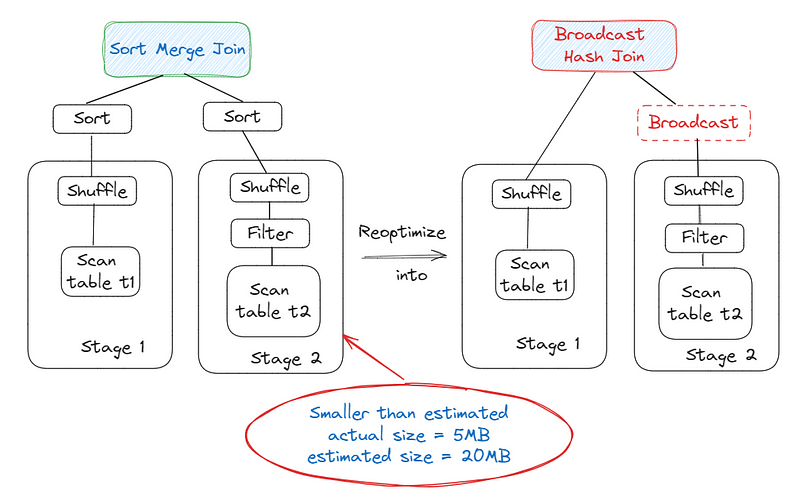
You need first to enable the two parameters spark.sql.adaptive.enabled=true and spark.sql.adaptive.coalescePartitions.enabled=true.Then Adaptive Query Execution (AQE) addresses this issue by dynamically replanning the join strategy at runtime, using the most accurate join relation size.
In the example below, AQE identifies that the right side of the join is significantly smaller than estimated and can be broadcasted. The actual size is 5 MB, while the estimated size is 20 MB, indicating that the table can be broadcasted since the actual size is less than the threshold (10 MB). Consequently, the initially planned Sort Merge Join is reoptimized to a Broadcast Hash Join for improved performance.
Thank you for reading 🙌🏻 😁 I hope you found it helpful. If so, feel free to give a clap “Hit the button 👏” . If you have any other tips or tricks that you would like to share, please leave a comment below.