
How applications work with the PC’s memory (Stack vs Heap)

There are a lot of factors that affect how an application’s memory usage is managed, such as the OS and the language runtime (e.g. C++, Java, etc). But the focus of this article is to give a high level view of how memory is managed via the heap and the stack; which should remain consistent regardless of the factors mentioned above.
The first thing to know when talking about allocating memory on the stack or the heap is both of them are stored in RAM. Secondly the stack and heap is not to be confused with the stack and heap data structures. The stack and a stack data structure do share the LIFO property but there’s no commonality between the heap and a heap data structure.
What is the stack
Every thread has their own stack. The OS allocates the stack for every thread and when the thread exits, the stack is reclaimed. Each function call will have it’s own stack and it will be local to the function execution and the stack is reclaimed when the execution returns from the function.
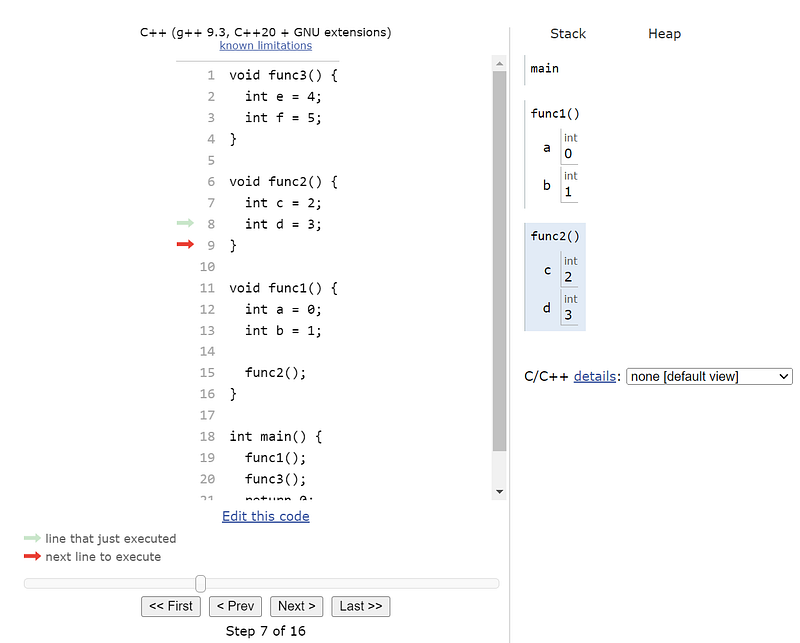
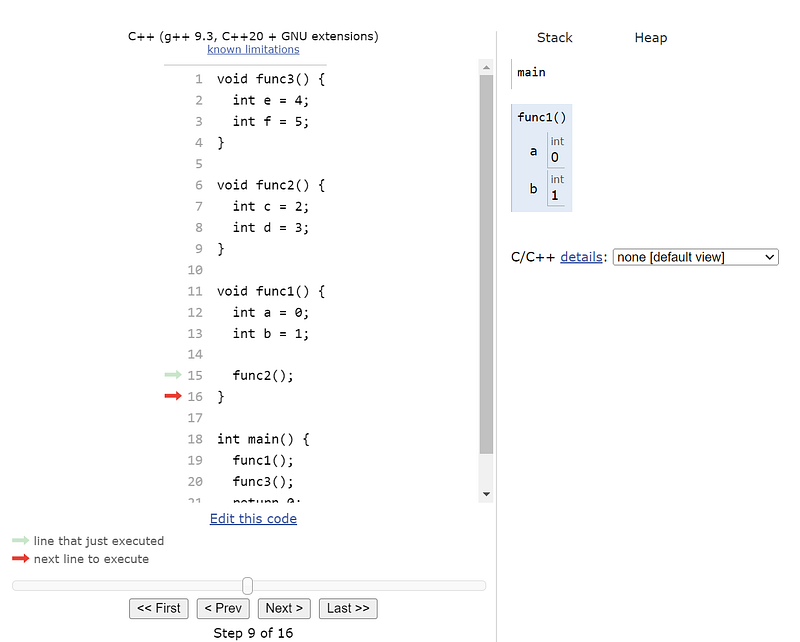
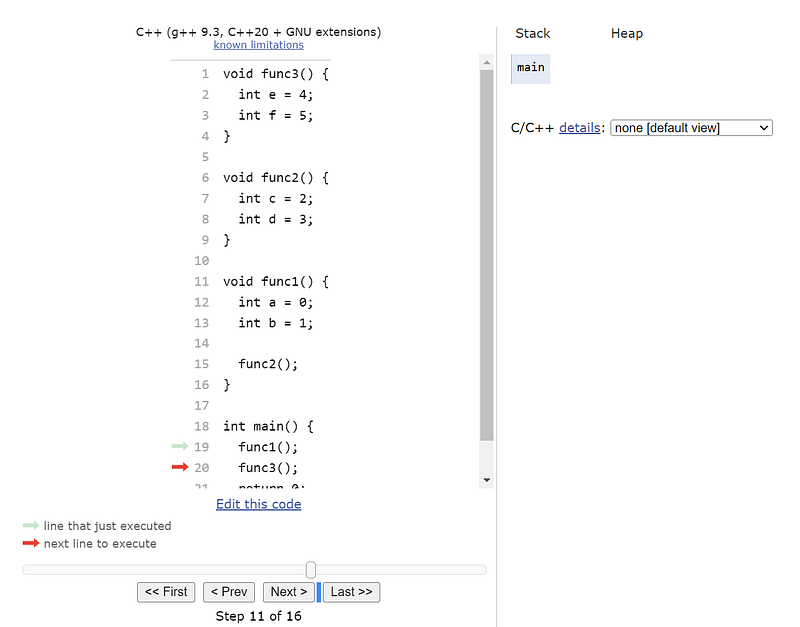
To illustrate the functional scope using the stack see below code, and the following tool to visualize the stack allocation of the code step by step.
void func3() {
int e = 4;
int f = 5;
}
void func2() {
int c = 2;
int d = 3;
}
void func1() {
int a = 0;
int b = 1;
func2();
}
int main() {
func1();
func3();
return 0;
}
The stack is much faster than the heap. This is due the localization and optimization in modern CPUs. This is because the data on the stack is contiguous and when the CPU fetches the data of a specific address, it also pulls in the neighboring address into the CPU’s cache because it’s very likely that the program will need the neighboring data as well.
Finally the stack is a fixed size that is determined by the OS at runtime when the thread is created. When the stack runs out of memory, it will result in a stack overflow exception, this is usually caused by calling nested functions too many times.
What is the heap
The head is global and is shared by all threads. This means there must be some sort of synchronization if multiple threads are accessing the same data. Also, allocation and deallocation doesn’t follow any fixed pattern and can occur ad-hocly. (Note: This applies mainly for languages like c++ where developers can control allocating and deallocating memory freely. But even with languages like JAVA, the same concept applies to the garbage collector. When you exit from a function, it’s not guaranteed the garbage collector will run and consequently the memory allocated in the heap from the function call is not freed on function exit. Eventual the garbage collector will run and reclaim the memory but it’s determined by the language runtime)
To help visualize heap allocation, see the below c++ code that explicitly allocated and deallocates memory on the heap to illustrate the global nature of the heap. It also illustrates how memory leaks can occur when working with languages that allows manual heap allocation.
void func3() {
int e = 4;
int f = 5;
}
void func2() {
int* c = new int(2);
int* d = new int(3);
delete c;
}
void func1(int** a) {
*a = new int(0);
int* b = new int(1);
func2();
delete b;
}
int main() {
int* a;
func1(&a);
func3();
return 0;
}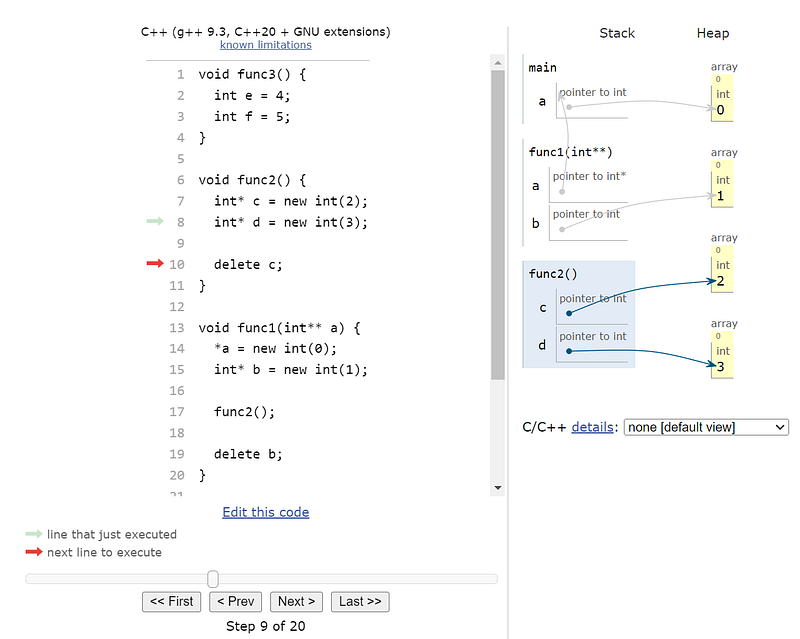
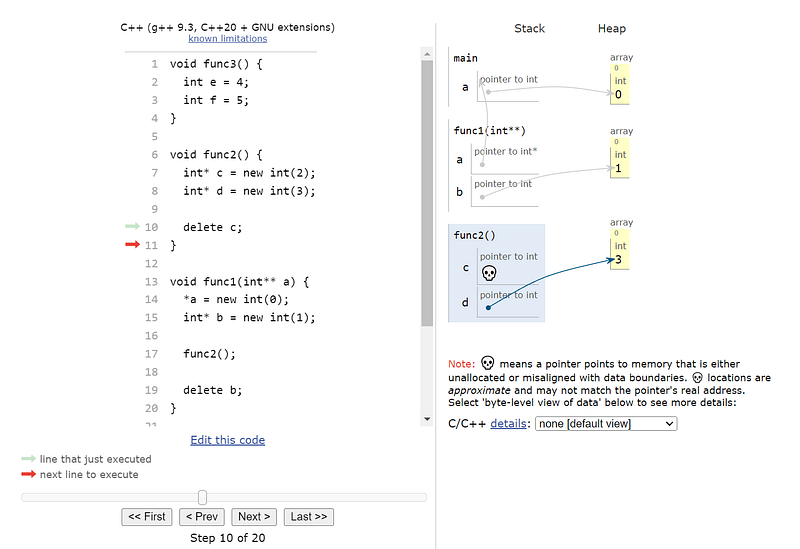
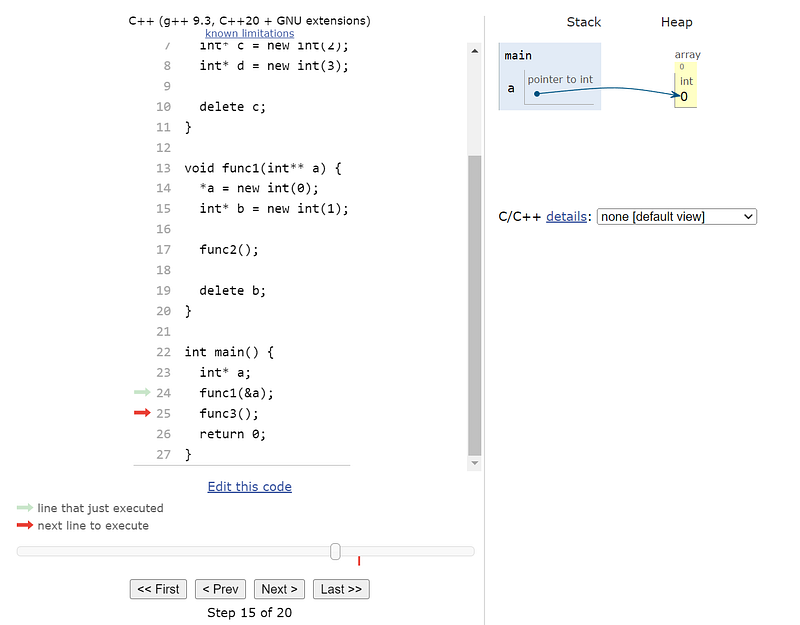
Note: There are many memory leaks in the above code that is not conveyed in the visualization. Any allocation on the heap must be cleaned up, either manually (e.g. via delete) or automated (via smart pointers).
The heap is much slower than the stack because there is much more complex bookkeeping involved in allocating and deallocating memory (especially in multithreaded environments). Since the heap is a global resource there is a performance hit in each allocation and deallocation because of requiring synchronization with “all” heap access in the program.
The stack can grow whenever extra memory is necessary, however the program is still limited by how much RAM is available
Resources
https://www.programmerinterview.com/data-structures/difference-between-stack-and-heap/