
How AI Can See Better Than Your Eyes Do
Convolutional Neural Networks explained, in plain English.
In this article, we introduce the key ideas in modern computer vision. We explore how to stack several layers with hundreds of neurons that learn low-level features in images. We motivate our quest by first looking at how vision works on mammals.

Vision, made in Nature
Neurons in the visual cortex of mammals are organized to process images in layers, some of which has a particular function at recognizing localized features such as lines and edges; some layers are activated when position and orientation change; other layers react to complex shapes such as crossing lines.

This motivates stacked convolutional layers, which consists of restricting the visual field of every neuron to a small area of the input image. The size of the receptive field is given by the filter size, also called kernel size. When the filter slides through the image, it works like a convolution in signal processing, therefore it allows features detection.
A convolution is an integral that expresses the amount of overlap of one function (kernel or filter) as it is shifted over another function (input). Convolution is used to filter signals (1D audio, 2D image processing), to check how much a signal is correlated to another or to find patterns in signals.
For example, specific kernels can be used to extract edges from an image.
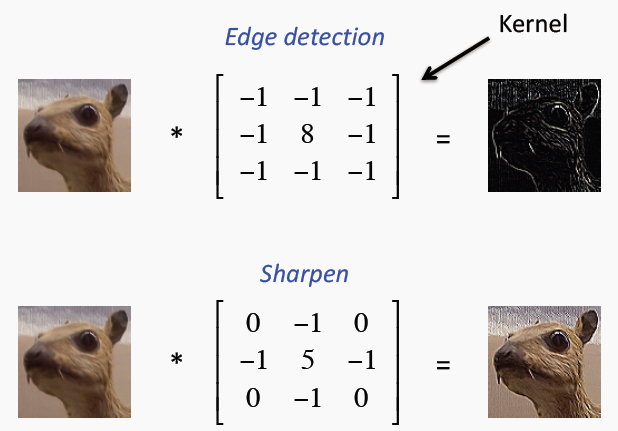
We can have many of those filters to detect all the valuable features of the image. Initially, those filters were built by hand; later they were learned from the images themselves. The process of finding weights during training also creates those filters.
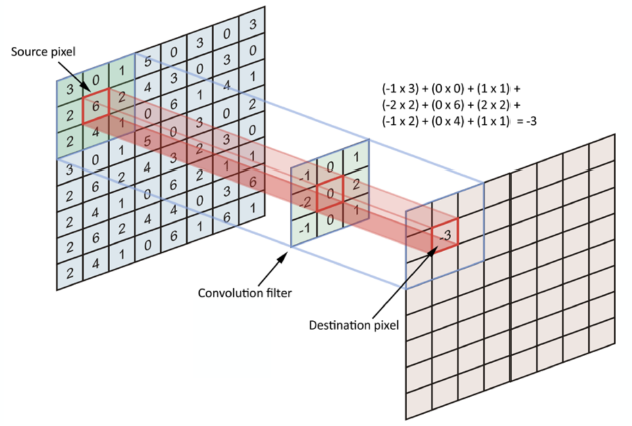
Features Map
How many such convolutions do we need? By introducing the notion of scale, borrowed from fractal mathematics, convolutional neural networks stack several convolutional layers, so that the first layers recognize smaller features and the deeper layers specialize in bigger features.
A fractal is an image with infinite scales. We typically have as many layers as we need to detect scales. The purpose of a single convolution layer is to learn a set of features at a particular single scale.
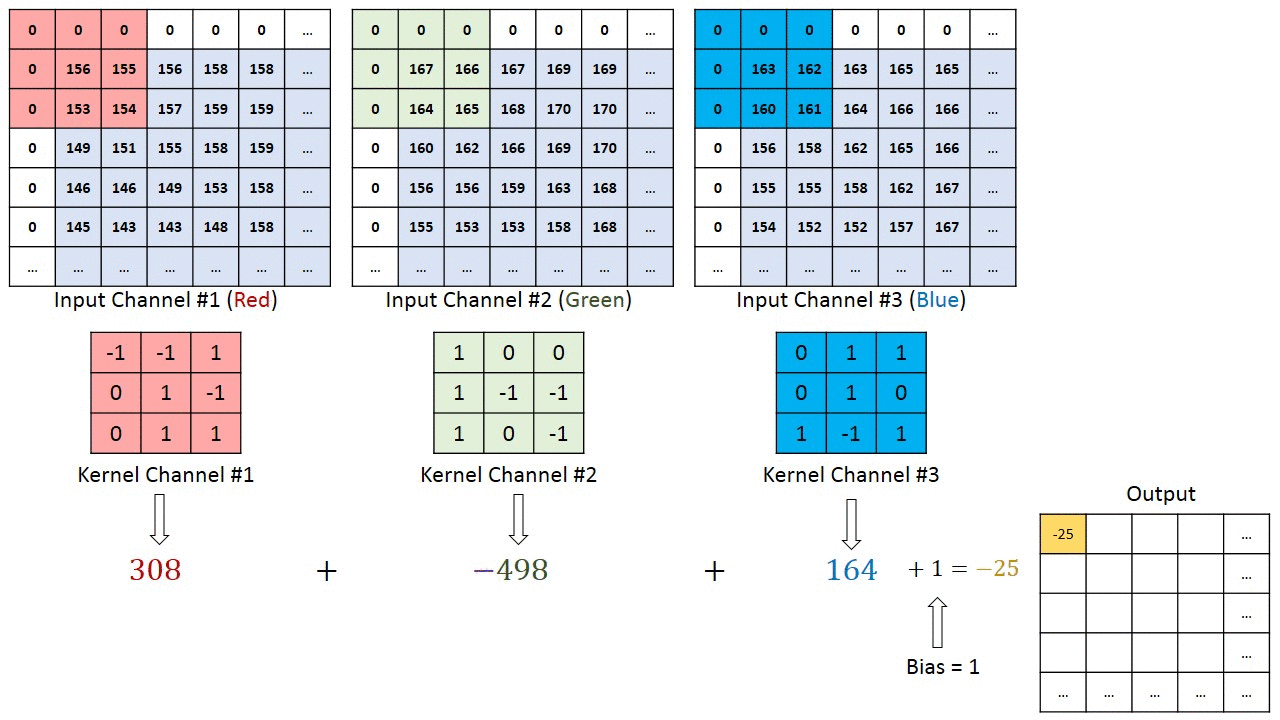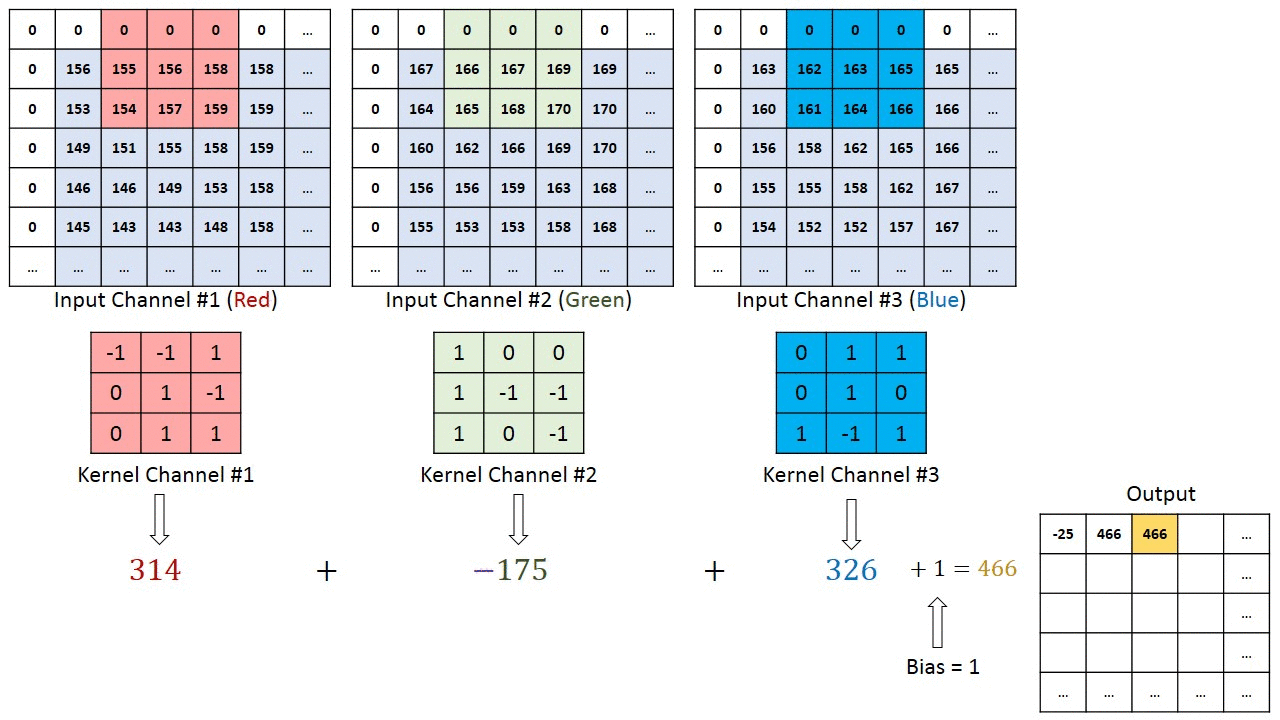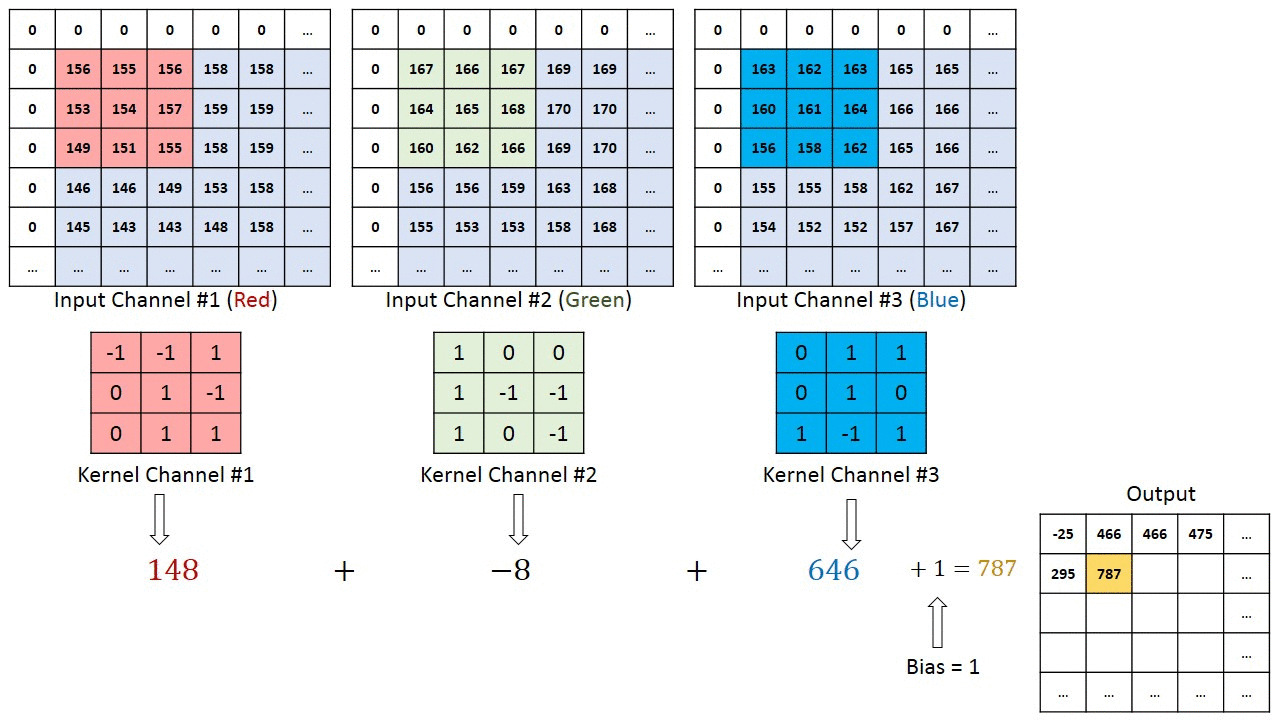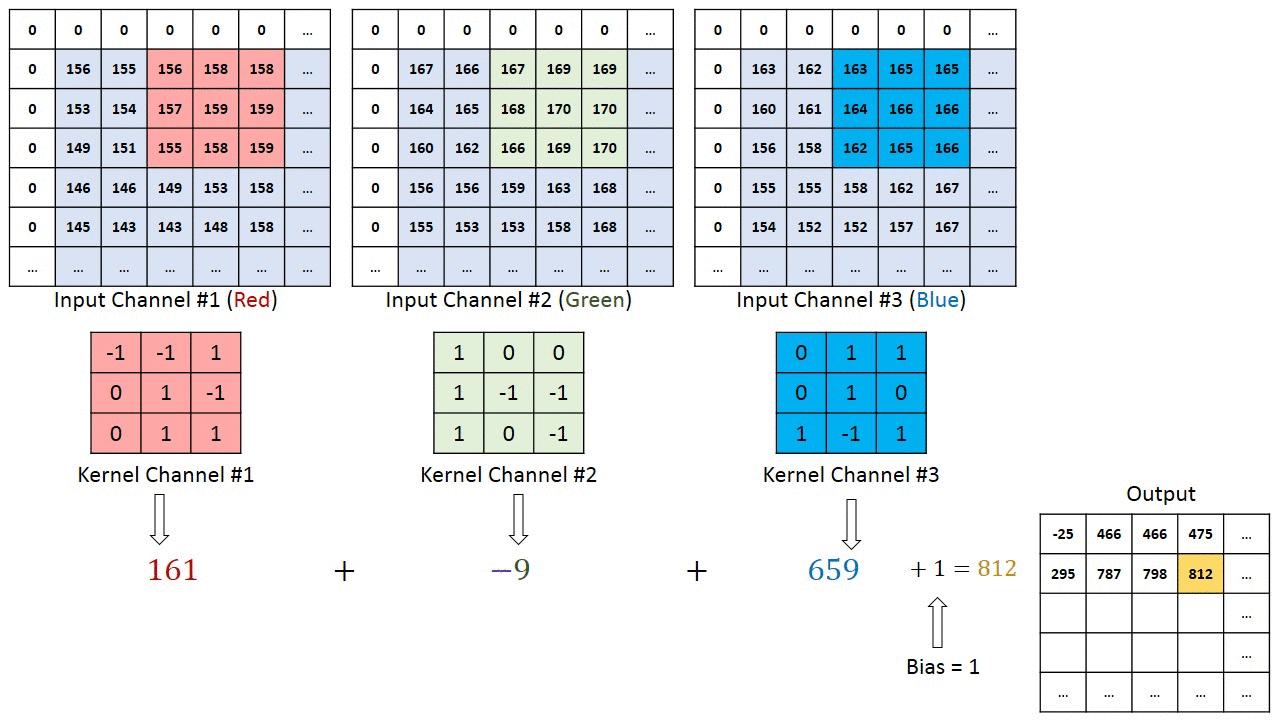
Each convolutional layer is also composed of layers, but those layers are not fully connected. Let’s assume a 28x28 RGB image used as input to the first convolutional layer with four 3x3 filters F1, F2, F3, F4. Each filter is a cube-shape of size 3x3x3 that is applied throughout the image to produce one number each time.
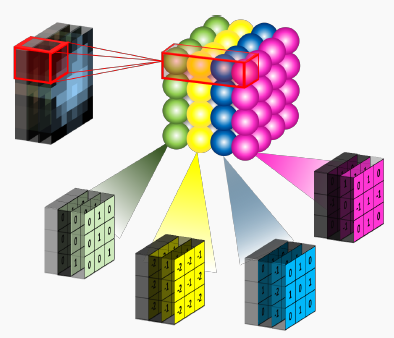
The number of steps by which the filter moves across the image is called stride, usually 1. The resulting features map has a depth equal to the number of filters. Its width and height depend on the image size, filter size, and padding.
In our example, in the case of full padding, we will have a feature map dimension 28x28x4. In the case of no padding, we will have dimension 26x26x4. Therefore the number of channels does not impact the features map size.
Pooling
Convolution causes repetition of information coming from neighboring areas of the image, leading to high dimensionality. Pooling takes an area of the output of a convolution layer and returns an aggregated value: usually max, but average, min or any function can be used.
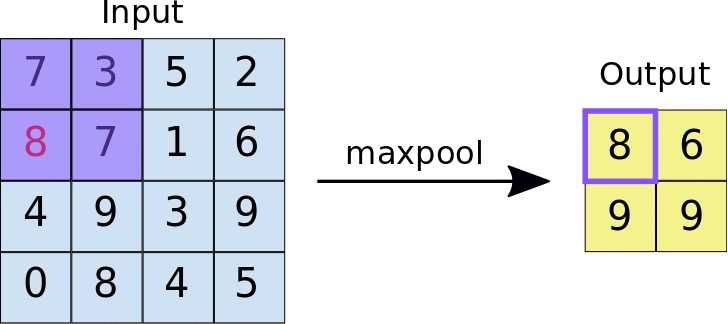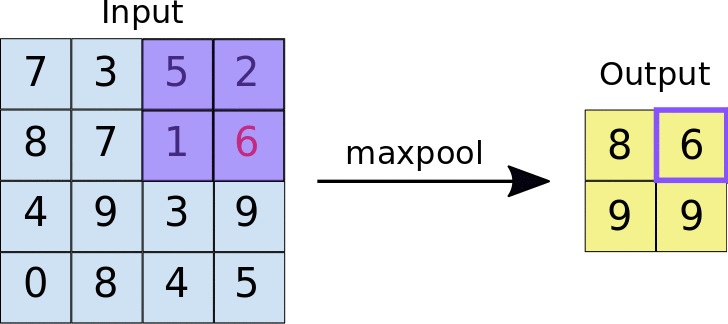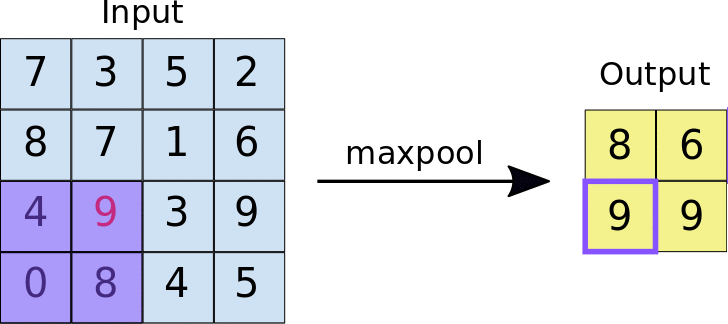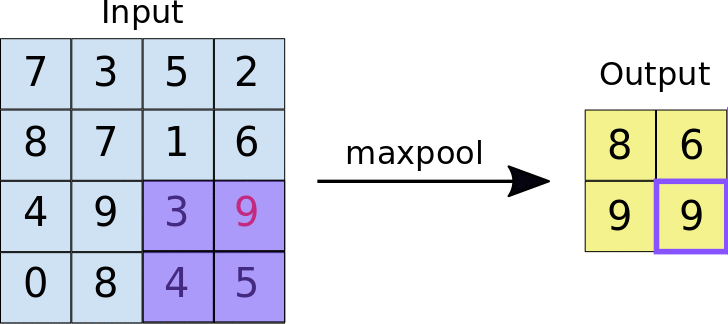
CNNs work the best when considering multiple scales. Therefore, we usually duplicate the convolutional and max pooling layers several times.
Getting Deeper
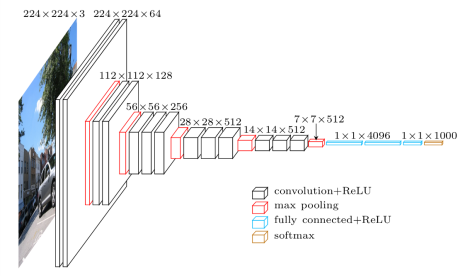
The way to stack convolutional layers together is more an art than a science. The VGG network below was proposed in 2014 for classifying 14 million images into to 1000 classes with 92.7% test accuracy. It was trained for 2 weeks to estimate its 14,714,688 weights. There are more of such supermassive networks: GoogLeNet, ResNet, DenseNet, MobileNet, Xception, ResNeXt, just to name a few.
A recommended and highly effective approach to deep learning is to leverage one of those pre-trained networks. A pre-trained network is simply a saved network previously trained on a large dataset, and can effectively act as a generic model of the real world.
Feature extraction is one way of using the representations learned by pre-trained network by taking the convolutional base of a pre-trained network, running the new data through it, and training a new simple classifier on top of the output using a new small dataset, as illustrated below.
An alternative technique consists of freezing the base of the pre-trained network, appending a simple classifier, and training the whole. Another alternative, called fine-tuning, consists of unfreezing specific layers in the base before training.
Conclusion
Providing sensing capabilities to computers has a significant impact on societies. Nowadays camera systems capture real-time images of the world to enable groundbreaking applications such as autonomous driving. In this article, we explained few mechanisms underlying machine learning for computer vision.
Sony has just announced the world’s first image sensor with integrated AI, allowing it to perform computer vision tasks without any additional hardware.
It is only a matter of time before computers will see in specific contexts better than we humans do.