
How a Cache Stampede Caused One of Facebook’s Biggest Outages
Learn engineering lessons from a decade ago to prevent mistakes today

On September 23, 2010, Facebook had one of its most severe outages to date. The site was down for four hours. The situation was so drastic that the engineers had to take Facebook offline in order to recover.
While Facebook wasn’t as gigantic as it is now, it still had over a billion users and its outage didn’t go unnoticed. People took to Twitter to either complain or jest about the situation.
So, what actually caused Facebook to go down? According to the public postmortem that followed the incident:
Today we made a change to the persistent copy of a configuration value that was interpreted as invalid. This meant that every single client saw the invalid value and attempted to fix it. Because the fix involves making a query to a cluster of databases, that cluster was quickly overwhelmed by hundreds of thousands of queries a second.
A bad configuration change led to a swarm of requests being funneled to their databases. This stampede of requests is aptly known as a cache stampede. It is a common issue that plagues the tech industry. It has lead to outages at many companies, such as the Internet Archive in 2016. And many large scale applications fight it on a daily basis, such as Instagram and DoorDash.
What is a Cache Stampede?
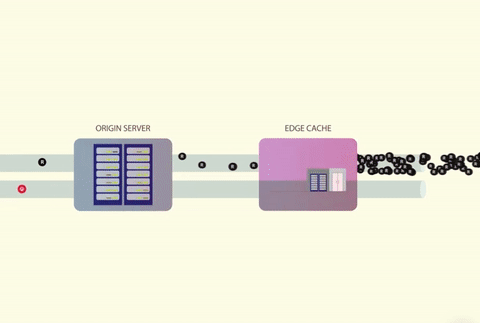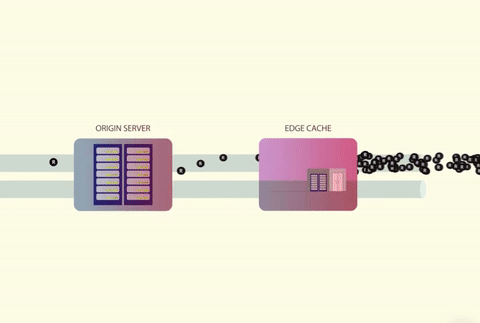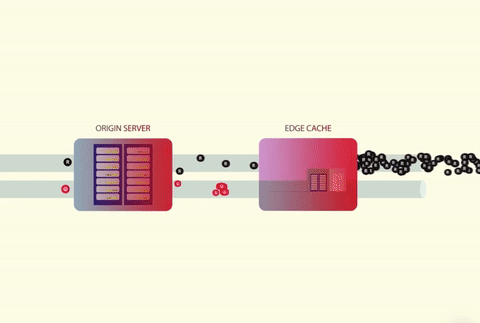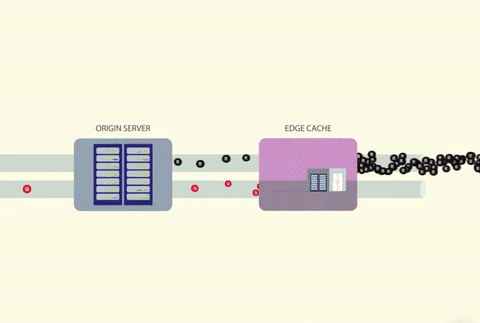
A cache stampede occurs when several threads attempt to access a cache in parallel. If the cached value doesn’t exist, the threads will then attempt to fetch the data from the origin at the same time. The origin is commonly a database but it can also be a web server, third-party API, or anything else that returns data.
One of the main reasons why a cache stampede can be so devastating is because it can lead to a vicious failure loop:
- A substantial number of concurrent threads get a cache miss, leading to them all calling the database.
- The database crashes due to an enormous CPU spike and leads to timeout errors.
- Receiving the timeout, all the threads retry their requests — causing another stampede.
- On and on the cycle continues.
You don’t need to be the scale of Facebook to suffer from it. It’s scale-agnostic, haunting both startups and tech giants alike.
How Can You Prevent a Cache Stampede?
That’s an excellent question. That’s the question I asked myself after learning about the Facebook outage. Unsurprisingly, a lot of research has been put into preventing cache stampede since 2010. I read through all of it.
In this article, we’re going to explore the different strategies for preventing and mitigating cache stampedes. After all, you don’t want to wait for your own outage to learn what safety measures exist.
Add More Caches
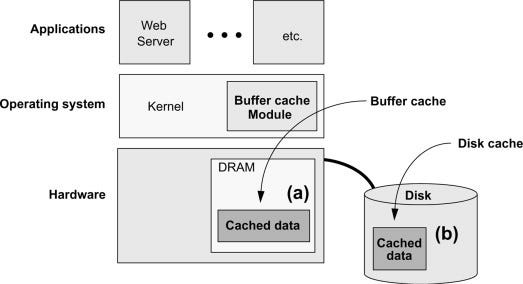
A simple solution is to just add more caches. While it may seem counterintuitive, this is similar to how operating systems work.
Operating systems make use of a cache hierarchy where each component caches its own data for faster access.
You can adopt a similar pattern in your applications by incorporating in-memory caches, which can be called Layer 1 (L1) caches. Any remote caches would be considered Layer 2 (L2).
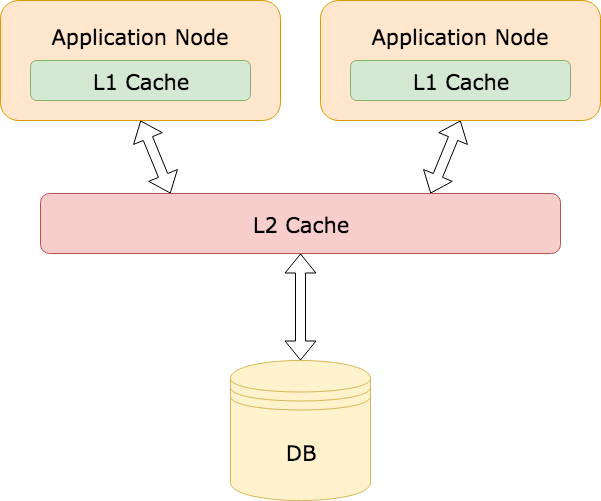
This is particularly useful for preventing stampedes on frequently accessed data. Even if a key on the Layer 2 cache key expires, several of the Layer 1 caches may still have the value stored. This will limit the number of threads that need to recompute the cached value.
However, there are some notable tradeoffs to this approach. Caching data in-memory on your application servers can lead to out of memory issues if you aren’t careful. Especially if you’re caching large amounts of data.
Additionally, this caching strategy is still vulnerable to what I call the follower stampede.
An example of a follower stampede is when a celebrity uploads a new photo or video to their social media account. When all of their followers are notified of the new content, they rush to view it. Since the content is so new, it hasn’t been cached yet, leading to the dreaded cache stampede.
So, what can we do about follower stampedes?
Locks and Promises
At its core, a cache stampede is a race condition — multiple threads grappling over a shared resource. In this context, the shared resource is the cache.
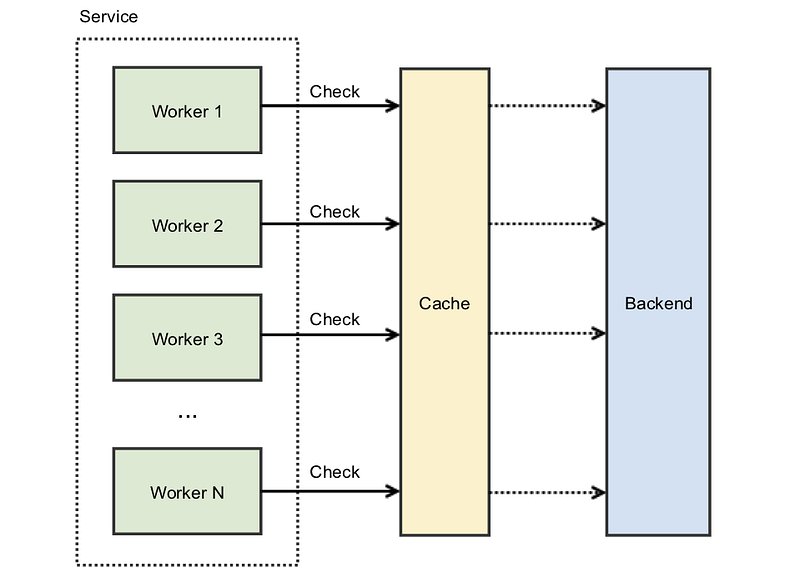
As is common in highly concurrent systems, one way to prevent a race condition on a shared resource is to use locks. While locks are normally used for threads on the same machine, there are ways to use distributed locks for remote caches.
By placing a lock on a cache key, only one caller will be able to access the cache at a time. If the key is missing or expired, the caller can then generate and cache the data, all while holding onto the lock. Any other processes that attempt to read from the same key will have to wait until the lock is free.
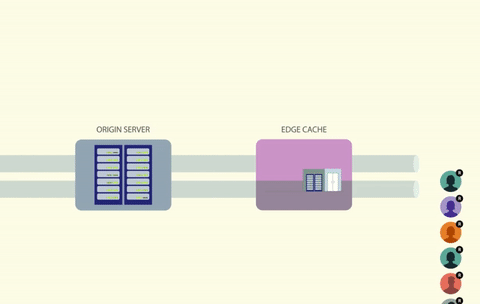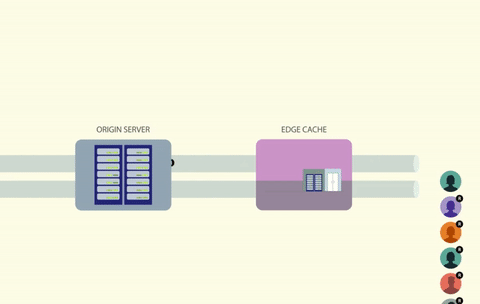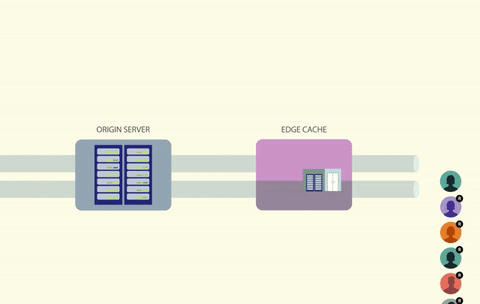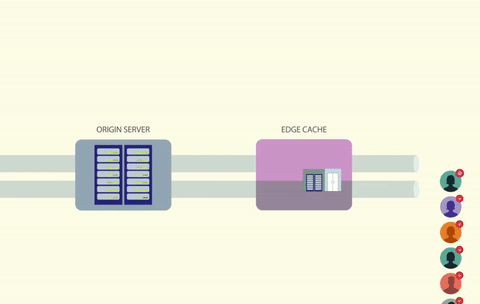
Using a lock solves the race condition problem, but it creates another one. How do you handle all of the threads that are waiting for the lock to free up?
Do you use a spinlock pattern and have the threads continuously poll for the lock? This will create a busy waiting scenario.
Do you have the threads sleep for an arbitrary amount of time before checking if the lock is free? Now you have the thundering herd problem on your hands.
Do you introduce backoff and jitter to prevent a thundering herd? That could work, but there’s a more pervasive issue at hand. The thread with the lock has to recompute the value and update the cache key before releasing the lock.
This process could take a while. Especially if the value is expensive to compute or there are network issues. This could still lead to an outage itself if the cache exhausts its available connection pool and user requests get dropped.
Fortunately, there’s a simpler solution that some top engineering organizations are using: promises.
How promises prevent spinlocks
To quote Thundering Herds & Promises from Instagram’s engineering blog:
At Instagram, when turning up a new cluster we would run into a [cache stampede] problem as the cluster’s cache was empty. We then used promises to help solve this: instead of caching the actual value, we cached a Promise that will eventually provide the value. When we use our cache atomically and get a miss, instead of going immediately to the backend we create a Promise and insert it into the cache. This new Promise then starts the work against the backend. The benefit this provides is other concurrent requests will not miss as they’ll find the existing Promise — and all these simultaneous workers will wait on the single backend request.
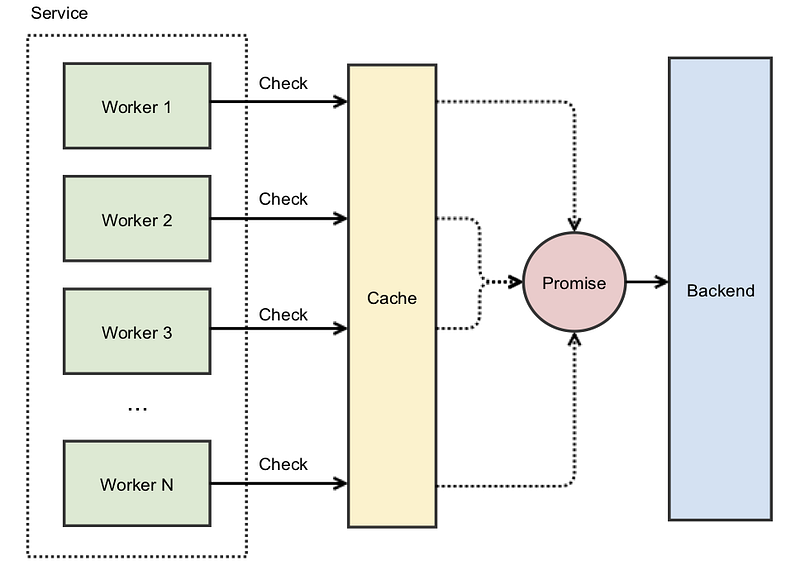
By caching promises instead of the actual values, no spin locking is needed. The first thread to get a cache miss will create and cache an asynchronous promise using an atomic operation (such as Java’s computeIfAbsent). All sequential fetch requests will immediately return the promise.
You would still need to use a lock to prevent multiple threads from accessing the cache key. But assuming that creating a promise is a near-instantaneous operation, the length of time threads stay in a spinlock is negligible.
This is exactly how DoorDash avoids cache stampedes.
But what if it takes a relatively long time to recompute the cached value? Even if the threads are able to fetch the cached promise immediately, they will still need to wait for the asynchronous process to finish before returning a value.
While this scenario might not necessarily count as an outage, it will impact tail latency and the overall user experience. If keeping tail latency low is important for your application, then there is another strategy to consider.
Early Recomputation
The idea behind early recomputation (also known as early expiration) is simple. Before the official expiration of a cache key occurs, the value is recomputed and the expiration is extended. This ensures that the cache is always up-to-date and that cache misses never occur.
The simplest implementation of early recomputation is a background process or cron job. For example, let’s say there’s a cache key whose time-to-live (TTL) expires in an hour and it takes two minutes to compute the value. A cron job could run five minutes before the end of the hour, and extend the TTL another hour after updating.
While this idea is simple in theory, there’s a glaring drawback. Unless you know exactly which cache keys will be used, you will need to recompute every key in the cache. This can be a very laborious and costly process. It also requires maintaining another moving part with no easy recourse if it fails.
For these reasons, I wasn’t able to find any example of this sort of early recomputation in a production setting. But there’s a kind that is used.
Probabilistic early recomputation
In 2015, a group of researchers published a whitepaper called Optimal Probabilistic Cache Stampede Prevention. In it, they describe an algorithm for optimally predicting when to recompute a cache value before its expiration.
There’s a lot of math theory in the research paper, but the algorithm boils down to this:
currentTime - ( timeToCompute * beta * log(rand()) ) > expirycurrentTimeis the current timestamp.timeToComputeis the time it takes to recompute the cached value.betais a non-negative value greater than 0. It defaults to 1 but is configurable.rand()is a function that returns a random number between 0 and 1.expiryis the future timestamp of when the cached value is set to expire.
The idea is that every time a thread fetches from the cache, it runs this algorithm. If it returns true, then that thread will volunteer to recompute the value. The odds of this algorithm returning true dramatically increase the closer you are to the expiration time.
While this strategy isn’t the easiest to understand, it’s fairly straightforward to implement and doesn’t require any additional moving parts. It also doesn’t require recomputing every value in the cache.
The Internet Archive began using this method after an outage during one of the 2016 presidential debates. This presentation from RedisConf17 goes more into the story and gives an excellent overview of how probabilistic early recomputation works. I highly recommend giving it a watch:
However, early recomputation assumes there’s a value to recompute — it won’t prevent a follower stampede on its own. For that, you would need to combine it with locks and promises.
How to Stop a Stampede That’s Ongoing
One of the reasons why Facebook’s cache stampede was so devastating was that even when the engineers found a solution, they couldn’t deploy it because the stampede was still ongoing.
From the postmortem:
To make matters worse, every time a client got an error attempting to query one of the databases it interpreted it as an invalid value, and deleted the corresponding cache key. This meant that even after the original problem had been fixed, the stream of queries continued. As long as the databases failed to service some of the requests, they were causing even more requests to themselves. We had entered a feedback loop that didn’t allow the databases to recover.
The reality is that there’s no guarantee that prevention will always work. You also need mitigation. Defensive programming dictates that a plan should be in place in case a stampede bypasses your barriers.
Luckily, there’s a known pattern for dealing with this.
Circuit breaking
The idea of a circuit breaker in programming isn’t new. It gained popularity after Michael Nygard published Release It! in 2007. As Martin Fowler writes in his article CircuitBreaker:
The basic idea behind the circuit breaker is very simple. You wrap a protected function call in a circuit breaker object, which monitors for failures. Once the failures reach a certain threshold, the circuit breaker trips, and all further calls to the circuit breaker return with an error, without the protected call being made at all.
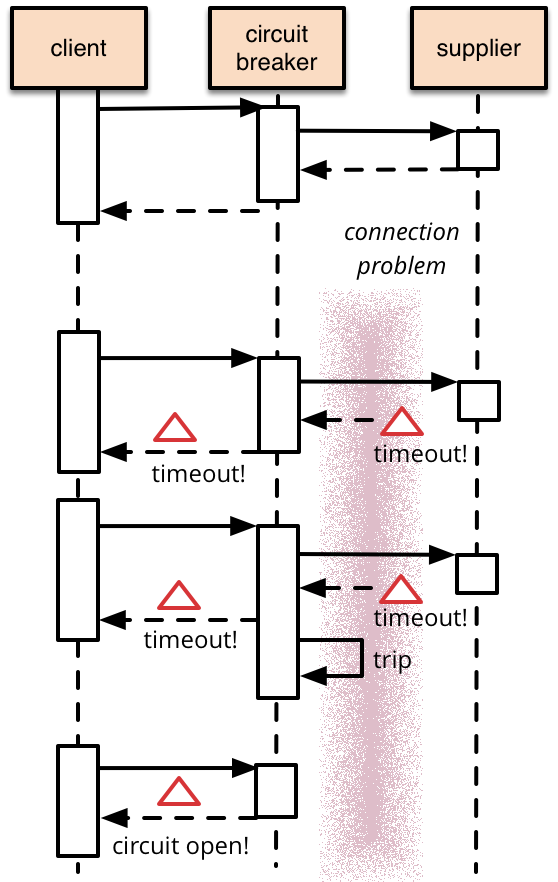
Circuit breakers are reactive, meaning they won’t prevent an outage. But they will prevent cascading failures. It provides a kill switch for when things get out of hand. Had Facebook utilized circuit breakers, they could have avoided having to take the entire site offline.
Granted, circuit breakers weren’t as popular in 2010. Nowadays, there are several libraries that come with circuit breaking baked in, such as Resilience4j, Istio, and Envoy. Several organizations use these services in production, such as Netflix and Lyft.
What Lessons Did Facebook Learn?
I’ve talked a lot in this article about different strategies for addressing cache stampedes and how other tech companies are using them. But what about Facebook itself?
What lessons did they take away from their outage and what safeguards did they put in place to prevent it from happening again?
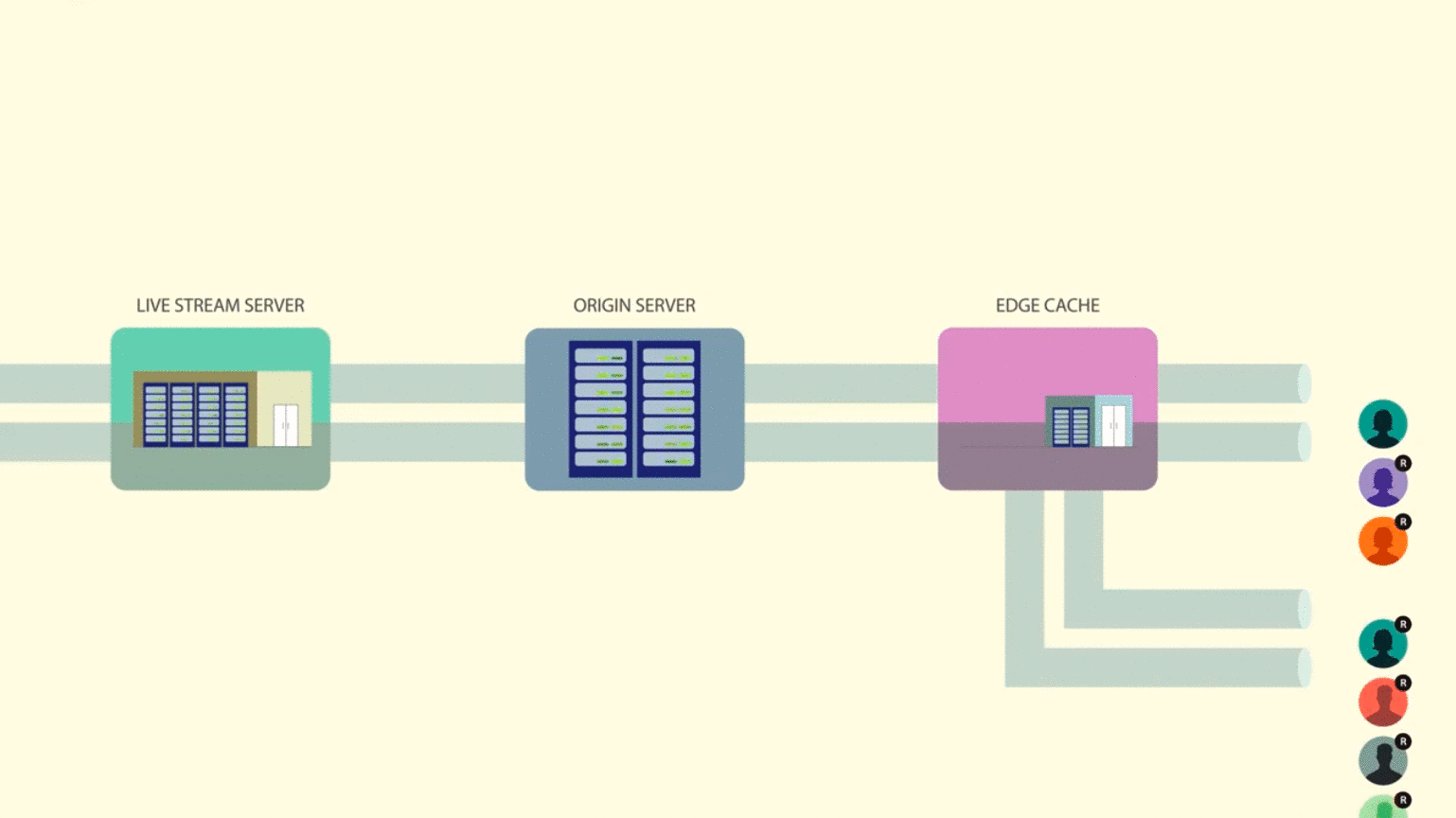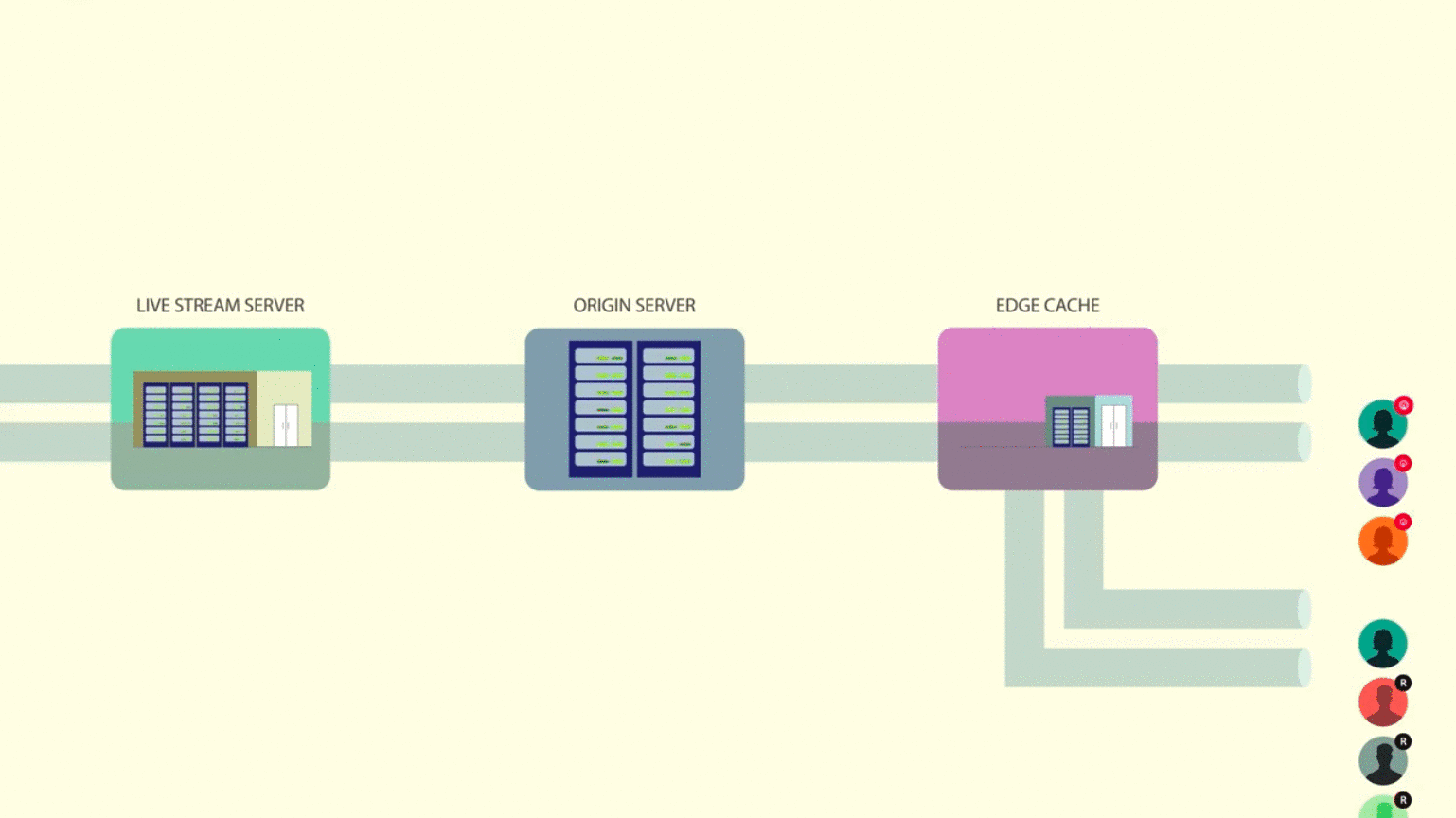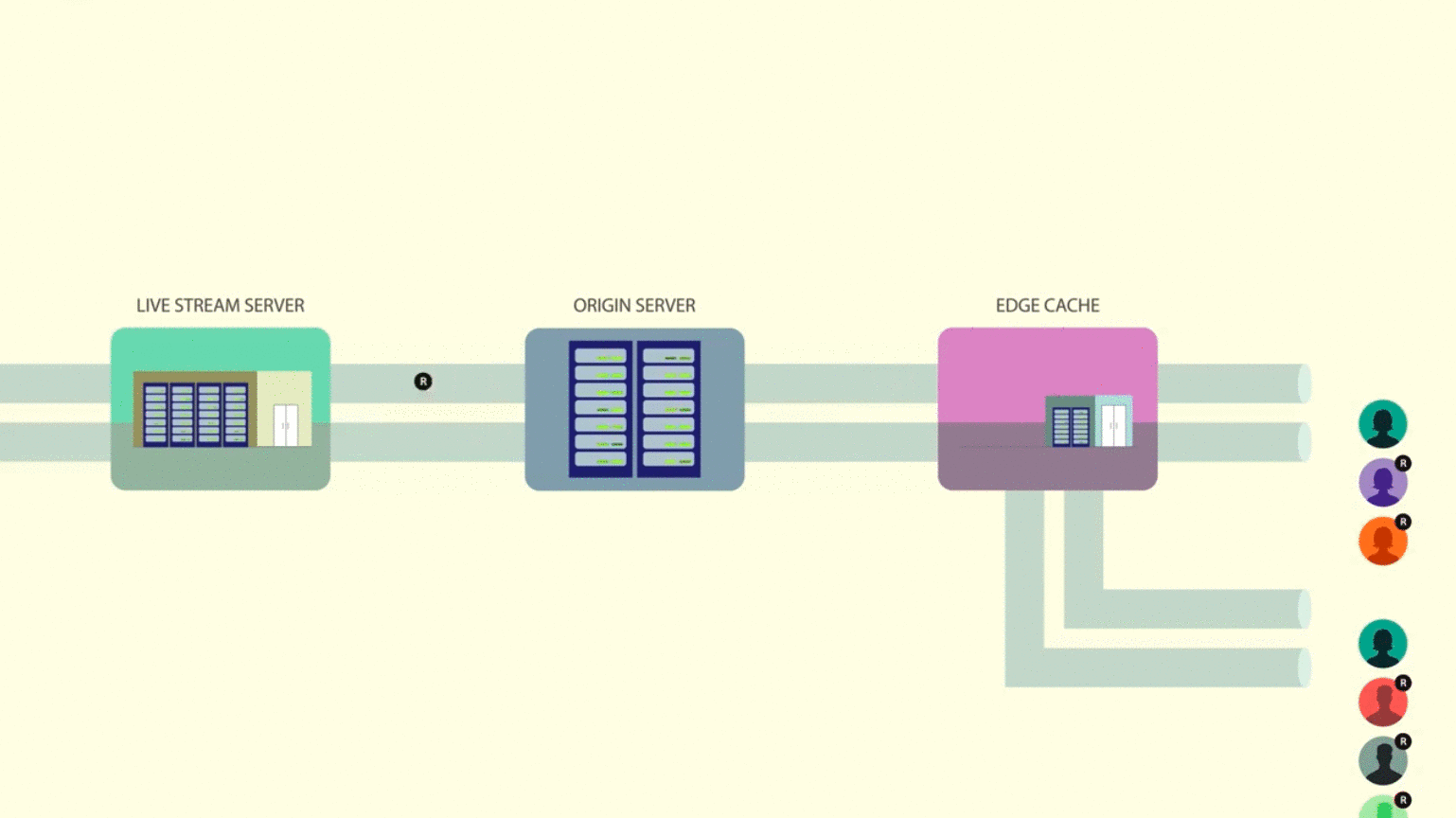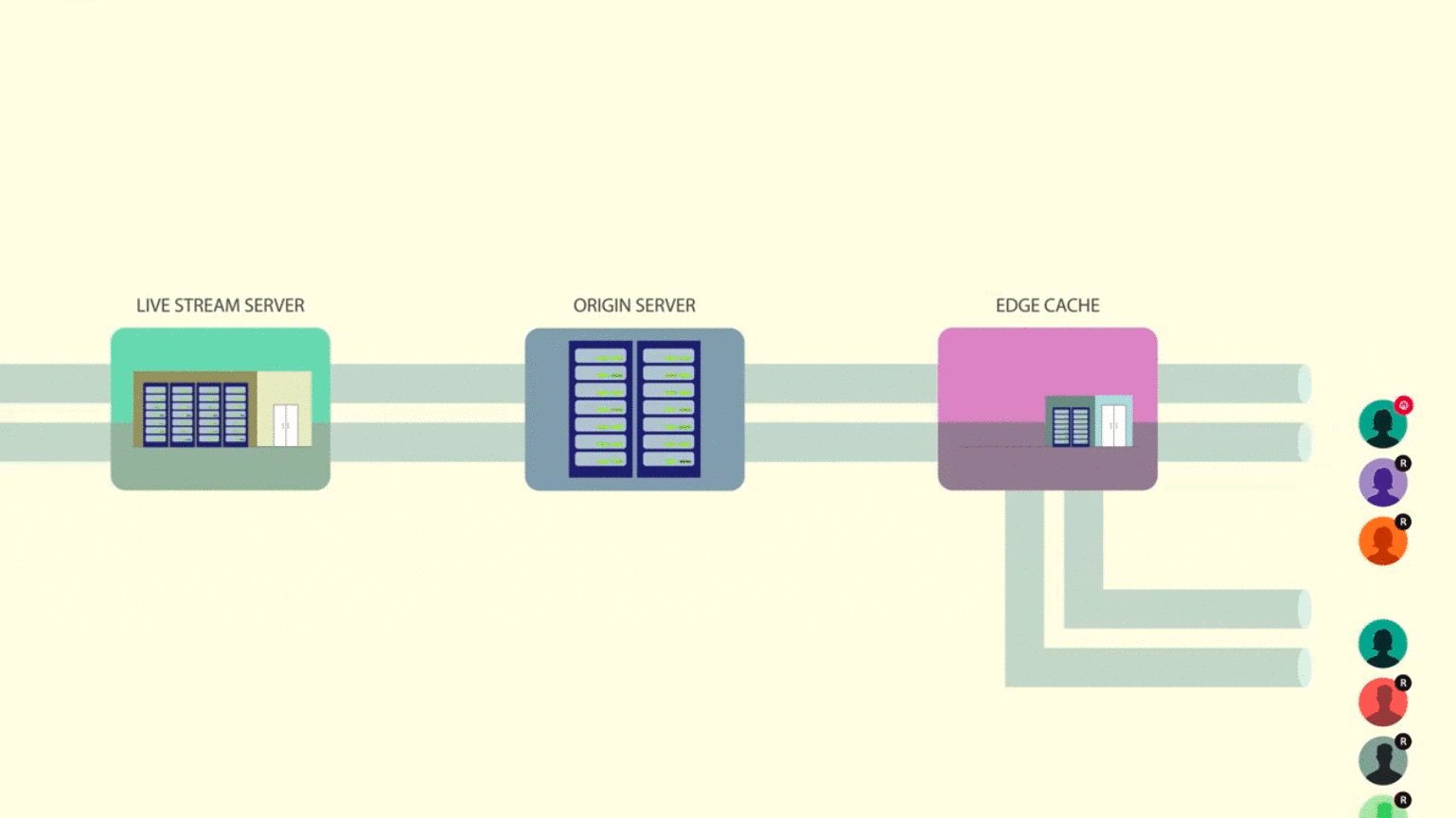
Their engineering post, Under the hood: Broadcasting live video to millions, discusses the improvements they’ve made to their architecture. It discusses things we’ve gone over, such as cache hierarchies, but it also includes some novel approaches, such as HTTP request coalescing. The article is worth a read, but if you’re short on time, this video gives a thorough overview.
Suffice it to say that Facebook has learned from their past mistakes.
Parting Thoughts
While I believe that understanding how cache stampedes can wreak havoc on a system, I don’t believe every tech team must add these measures immediately. How you choose to handle cache stampedes will depend on your use case, architecture, and traffic load.
But being aware of cache stampedes and knowledgeable of the possible solutions will benefit you in the future if and when you find yourself battling a thundering herd of your own.
Subscribe to my profile if you want to get notified whenever I upload a new story.





