
Hive Architecture in Depth
Apache Hive is an ETL and Data warehousing tool built on top of Hadoop for data summarization, analysis and querying of large data systems in open source Hadoop platform. The tables in Hive are similar to tables in a relational database, and data units can be organized from larger to more granular units with the help of Partitioning and Bucketing.
As part of this blog, I will be explaining as to how the architecture works on executing a hive query. Details such as the execution of queries, format, location and schema of hive table inside the Metastore etc.

There are 4 main components as part of Hive Architecture.
- Hadoop core components(Hdfs, MapReduce)
- Metastore
- Driver
- Hive Clients
Let’s start off with each of the components individually.
- Hadoop core components:
i) HDFS: When we load the data into a Hive Table it internally stores the data in HDFS path i.e by default in hive warehouse directory.
The hive default warehouse location can be found at
We can create a hive table and load the data into it as shown in below images.

ii) MapReduce: When we Run the below query, it will run a Map Reduce job by converting or compiling the query into a java class file, building a jar and execute this jar file.

2. Metastore: is a namespace for tables. This is a crucial part for the hive as all the metadata information related to the hive such as details related to the table, columns, partitions, location is present as part of it. Usually, the Metastore is available as part of the Relational databases eg: MySql
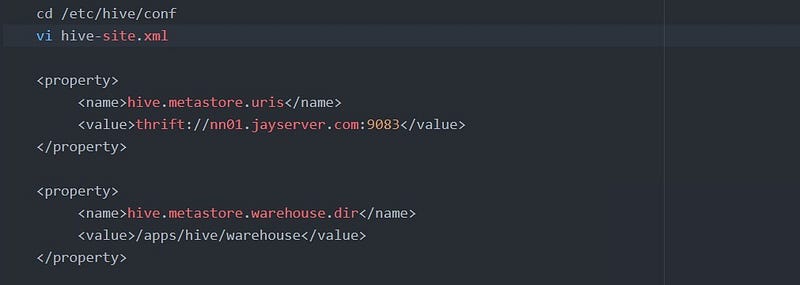
You can check the DataBase configuration via hive-site.xml
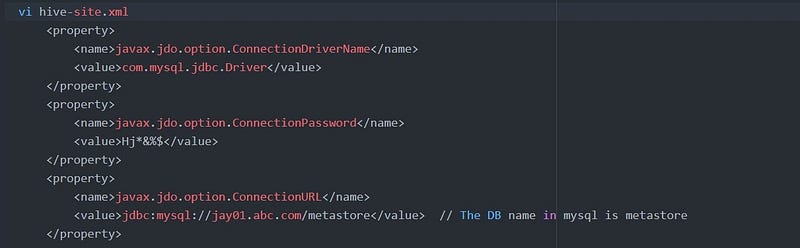
The Metastore details can be found as shown below.

Metastore has an overall 51 tables describing various properties related to the table but out of these 51 the below 3 tables are the ones which provide majority of the information, that in-turn helps hive infer the schema properties to execute the hive commands on a table.

i) TBLS — Store all table information (Table name, Owner, Type of Table(Managed|External)

ii) DBS — Database information (Location of database, Database name, Owner)

iii) COLUMNS_V2 — column name and the datatype

Note: In real-time the access to metastore is restricted to the Admin and specific users.
3. Driver: The component that parses the query, does semantic analysis on the different query blocks and query expressions and eventually generates an execution plan with the help of the table and partition metadata looked up from the metastore. The execution plan created by the compiler is a DAG of stages.
A bunch of jar files that are part of hive package help in converting these HiveQL queries into equivalent MapReduce jobs(java) and execute them on MapReduce.
To check if the hive can talk to the appropriate cluster. i.e for hive to interact, query or execute with the existing cluster. You can check details under core-site.xml.

You can verify the same from hive as well.

4. Hive Clients: It is the interface through which we can submit the hive queries. eg: hive CLI, beeline are some of the terminal interfaces, we can also use the Web-interface like Hue, Ambari to perform the same.
On connecting to Hive via CLI or Web-Interface it establishes a connection to Metastore as well.

The commands and queries related to this post are added as part of my GIT repository.
If you enjoyed reading it, you can click the heart ❤️ below and let others know about it. If you have got anything to add please feel free to leave a response 💬💭.




