

Highlights of RecSys 2019
Recommendation Systems, Deep Learning, User-Centric, Reproducibility and Multi-Task
Authors: Romain Beaumont, Amine Benhalloum, Florian Courtial, Ugo Tanielian, Marina Vinyes, Pranjul Yadav
Recsys 2019 took place in Copenhagen and with 909 attendees from around the world, it is the biggest edition so far. RecSys covers a wide variety of topics about recommender systems from their social impact to the algorithms that power them. Criteo AI Lab contributed two papers to the main conference and is also one of the co-organizers the REVEAL workshop.
This year we could see that the field is maturing, not only from an algorithmic and methods perspective but more importantly by addressing and acknowledging some of its issues. The presence of social scientists among the speakers and attendees is a gentle reminder that we are influencing people’s lives, how they interact with information, how they consume, and how they’re entertained and as a famous philosopher once said: “With great power, comes great responsibility”. We are accountable for this not only to our users but to our peers as well and we owe it to them to be more rigorous. The next few sections will cover these issues a bit more in detail.
Oh, and there were some pretty cool algorithms and applications as well ^^.
Social impact
This year there was a particular emphasis on integrity and social impact of recommender systems. Keynote speaker Mireille Hildebrandt, talked about how GDPR can change incentives of controllers, i.e. whoever determines the purpose and the means of processing like advertisers or publishers, from just optimizing for profit to also take into account transparency and better methodology (check out the slides). The second keynote, Eszter Hargittai, talked about people’s online behaviour, how it differs among platforms and how can it lead to biases in the algorithms. Finally, the panel tackled the problem of how to build social responsible recommender systems
Reproducibility and progress
It is of no surprise that reproducibility is an important topic troubling the field right now. But the issue goes beyond just making the code available to anyone and highlights a fundamental problem in how experiments are conducted and progress is measured: Baselines are not often properly tuned, the sets of datasets and tasks are not necessarily carefully chosen, and improvement measures are not always tested for significance. Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches, posed an important question indeed, as it compared several recent “complex” methods (aka neural CF variants) to not only reproduce the reported results but to beat well-tuned simpler baselines. Did they succeed? Well, let us just say that the “worrying” word in the title is there for a reason.
This work was awarded as the best paper, sending a message that the field as a whole should try harder.
Multi-objective / Multi-Task optimization
Usage of recommendation systems often involve multiple objectives, in order to solve this, it is possible to express the problem in a multi-task setting.
Optimization
More and more recommendation systems seek to optimize for more than one goal. For instance, you would like to optimize for the viewthrough of a video but also likes and comments on the video. In order to so, the system will have several loss functions, one per objective. At some point you must merge these losses into one, to do so you assign a weight for each one. For instance, the viewthrough of a video could be twice as important compared to the probability of interacting on the video. Manually setting these weights can be sub-optimal or cumbersome when dealing with lots of objectives. A best paper nominee, A Pareto-Efficient Algorithm for Multiple Objective Optimization in E-Commerce Recommendation, introduces a way to compute these weights automatically in order to attain a state where a change in one of the weights can only be done at the cost of one of the objectives (Pareto efficient state, where no single objective could be improved without sacrificing others). To get Pareto efficient optimums to methods are common:
- evolutionary heuristics which can not guarantee Pareto efficiency
- scalarization methods that merge all objectives in a single one that is the weighted sum of losses. Usually, scalarization weights are determined by hand
- In this paper, authors consider the scalarization approach and proposed a two-step algorithm to also learn the scalarization weights with theoretical guarantees. The step for updating the weights amounts to solve a quadratic problem with constraints.
Architecture
Google presented two papers showing a multi-objective architecture for retrieving and ranking videos. One of them is: Recommending what video to watch next: a multitask ranking system. It proposes to handle complex interactions with a complex framework to learn how to recommend videos :
- multiple objectives: engagement, satisfaction
- multiple kinds of embeddings: images and texts
- uses a multi-gate mixture of expert model to achieve these objectives
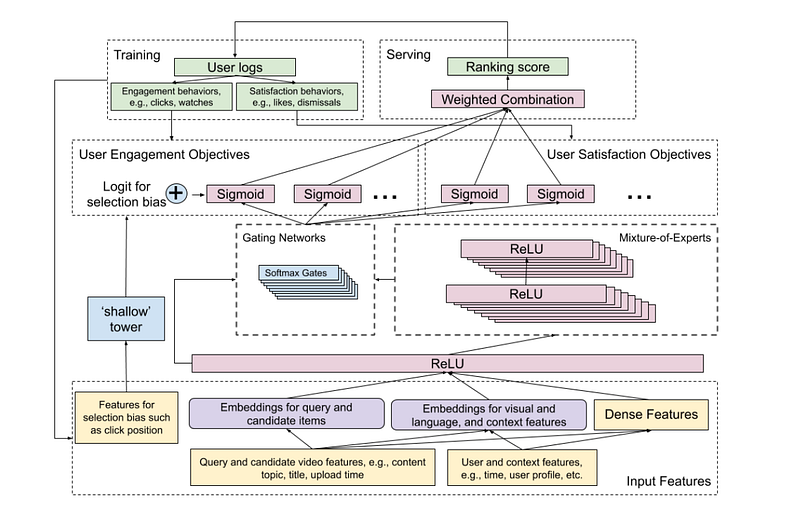
Two tutorials were also centred around this topic, there wasn’t enough room for all the attendees, showing the increasing interest.
Learning from implicit feedback
Recommenders systems are often built on implicit feedback signals (like clicks, views…) that do not directly measure user satisfaction. Many papers presented methods to better leverage implicit feedback.
Relaxed Softmax for PU Learning proposes a novel way to approach negative sampling, which is an omnipresent step in positive unlabeled learning (learning from implicit feedback is closely related to this task), most of the methods assume negatives sampled from a fixed distribution (popularity based, uniform, …). This paper (which is a Criteo paper yay!) proposes a new negative sampling scheme based on a boltzmann distribution, and where the negative samples are chosen closer to the decision boundary of the algorithm used to be more informative.
Leveraging Post-click Feedback for Content Recommendations tackles the problem of post-click information. They focus on real-world music and video datasets, with post-click information (i.e., if the song is listened or skipped) and show improvements in AUC on pointwise and pairwise models (18.3% and 2.5% respectively). Authors propose a generic probabilistic framework to fuse three disjoint sets of observations: click-completed, click then skip or no click. Confidence levels of each type of feedback is modelled through the variances of Gaussian distributions. Then they perform maximum likelihood estimation.
In display advertising, feature distribution might be non-stationary and the model predicting clicks needs to be regularly updated. One challenge is that recent user feedback is not available straight away. In Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction, they address the problem of delayed feedback.
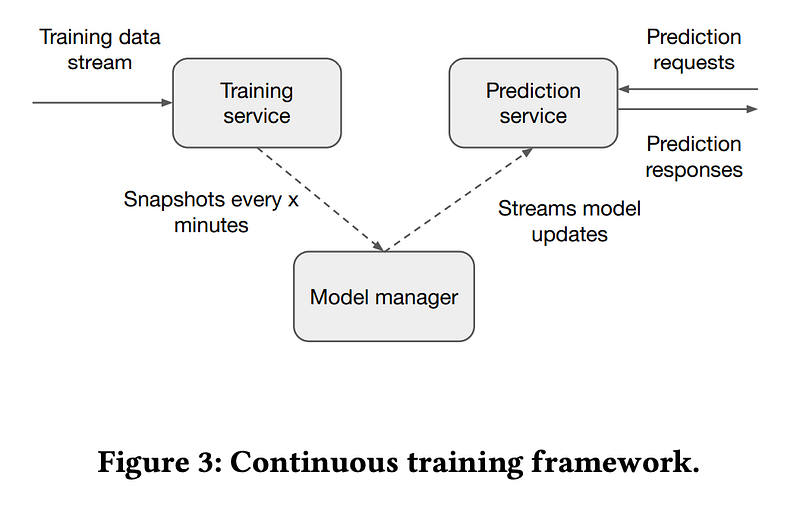
In related work, the used losses are delayed feedback loss (that assumes a separate model for the feedback delay) and PU loss (that treats all negative samples in biased data as unlabelled). Authors propose two loss functions that lead to the best offline performance and translate to online gains on a wide & deep model:
- FN weighted based on importance sampling. Samples are first labelled as negatives and then duplicated with a positive label as soon as a user engagement takes place.
- a calibrated version of the loss FN calibration
Even when the feedback seems explicit, like a purchase, for instance, the item may have been purchased even without the recommendation. An uplift (also called incrementality) is defined as an increase in user actions caused by recommendations. Uplift-based Evaluation and Optimization of Recommenders propose a new offline evaluation protocol and an optimisation method for uplift-based recommendation.
Instead of only considering each item independently and each action independently, From Preference into Decision Making: Modeling User Interactions in Recommender Systems address the issue of multiple items influencing each other on a page, with multiple action and type of actions. For this, they introduce a page level RNN.
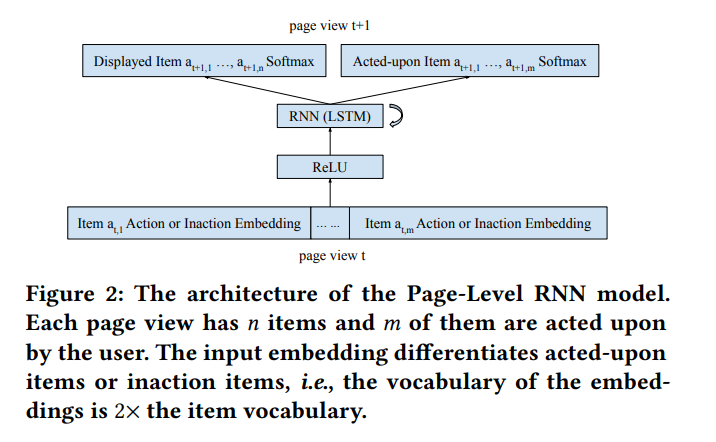
Side information: content-based recommendation
Content-based methods are particularly useful to solve the cold start problem: some items have few views, some partners are new.
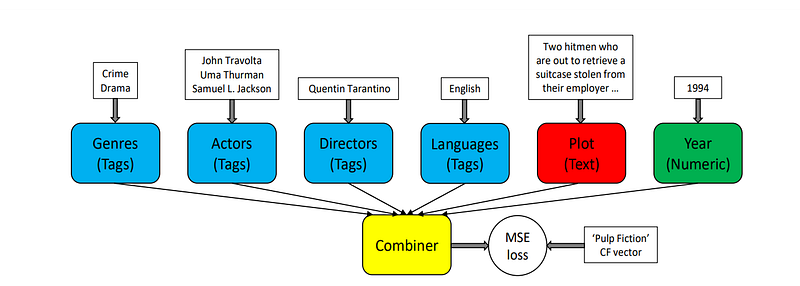
CB2CF: A Neural Multiview Content-to-Collaborative Filtering Model for Completely Cold Item Recommendations addresses this issue by generating CF embedding with only content in the form of :
- categorical features
- continuous features
- word embeddings
They then map these to CF embeddings using a simple CNN. Their results show that CB2CF is not as good as CF but better than CB alone and solves the cold start problem.
HybridSVD: When Collaborative Information is Not Enough proposes a method to jointly use collaborative information and content-based similarities to build products and user embeddings, by extending the traditional SVD based approach (which we built a very efficient and scalable implementation of, as the author pointed out during his presentation). The key idea is to replace the scalar product entries in the Gram matrix of the interactiontable, by a bilinear form parametrized by an auxiliary matrix of user or item similarities built from content. We also particularly appreciated the very clear and detailed process to reproduce the results found on github).
Scaling deep learning for recommendation
To build large scale recommender systems, efficient designs need to be proposed to lower the infrastructure costs.
To achieve this, Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations proposes to build item and user embeddings using a neural network architecture. To be able to retrieve many products, they use an efficient KNN implementation and a ranking model. The most novel parts are the negative sampling method which uses a mixture of popular and unpopular negatives. And the streaming frequency estimation makes it possible to efficiently compute the item and user features.
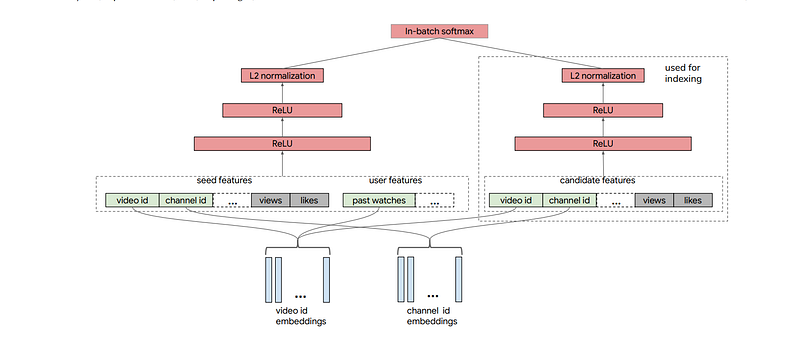
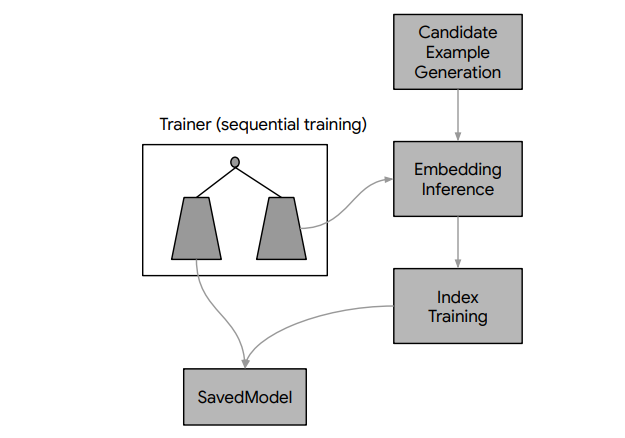
In a deep learning large scale recommendation systems, the number of item embeddings is very large and difficult to manipulate.
In particular, it causes difficulties to efficiently perform KNN on the whole catalog while keeping a low latency and low memory usage. To solve this problem PQ-VAE: Efficient Recommendation Using Quantized Embeddings proposes to quantize the items using exponential moving average k-means. They integrate this encoding directly inside the NN architecture by learning on the untransformed embeddings directly.
This makes it possible to reduce the size of the item embeddings by 1–2 order of magnitude.
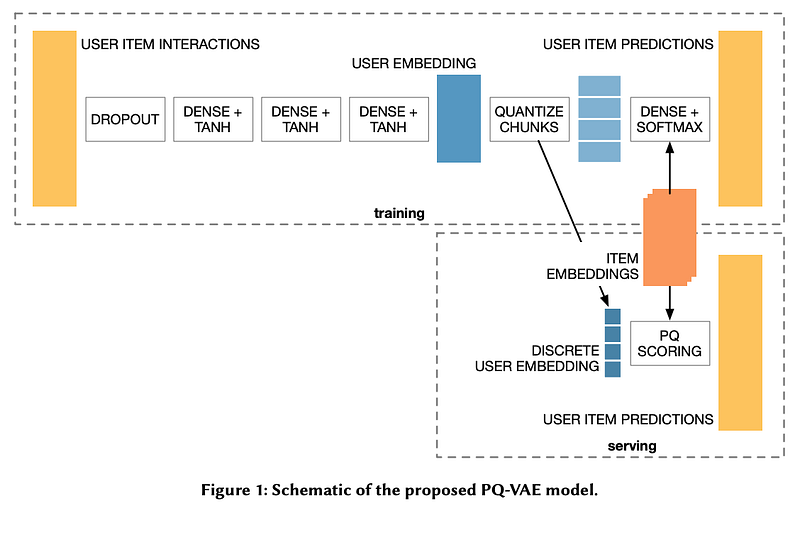
Domain-specific approaches
Although many recommendation methods are generic enough to be used for many domains, it is often useful to consider specific approaches to fine-tune the performance for a specific domain.
Domain Adaptation in Display Advertising: An Application for Partner Cold-Start (a Criteo paper) proposes to solve the issue of domain adaptation when history of user interaction with the one partner (target domain) is not available but we do have history of user’s interaction with other partners (source domain). The main challenge to achieve this is that data distributions are different between the source and target domain. To solve this issue, they propose to incorporate partner similarities (product category level information). They also propose a supervised domain adaptation approach termed as SDA-Ranking by leveraging a ranking loss for the domain adaptation task. This is showed to be effective in a real-world data-set obtained from Criteo.
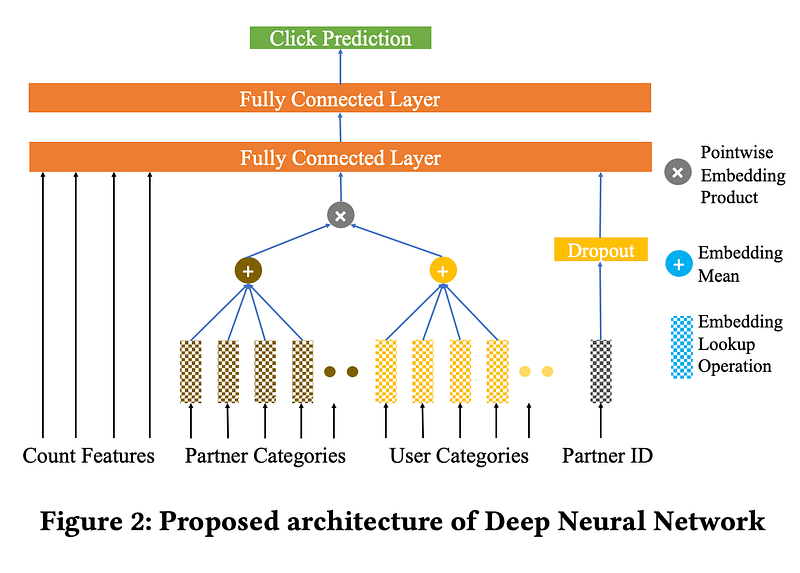
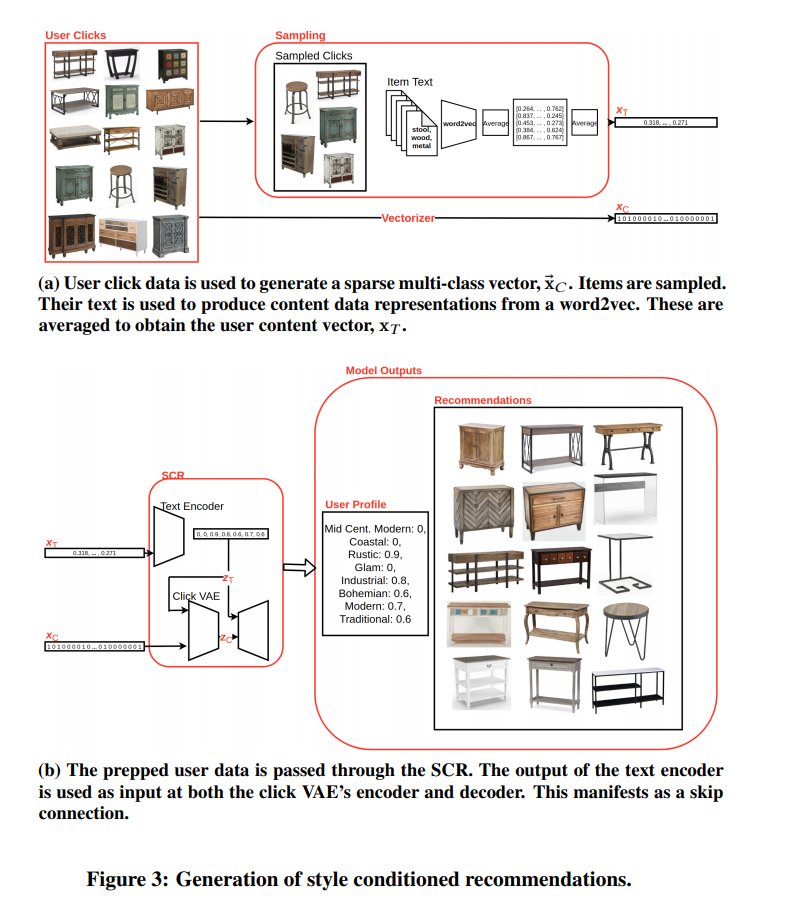
Style Conditioned Recommendations tackles the filter bubble issue by proposing style-conditioned recommendations. It uses a VAE model to integrate the styles into the recommendations. For this, it leverages both text and image embeddings and builds an interpretable encoding of a user profile. The main result is an increase of the presence of products with the style required.
Another interesting idea is presented in Users in the Loop: A Psychologically-Informed Approach to Similar Item Retrieval on how to measure item similarities in fashion. They propose to use a psychologically-informed similarity function called Tversky similarity based on psychology that is asymmetric (similar characteristics count more than distinctive ones). Thew show through studies that models based on Tversky similarity outperform the common Jaccard psychologically-naive similarity function in predicting users’ similarity judgments in the context of fashion.
REVEAL Workshop
The REVEAL workshop had an overwhelming success this year, with talks from industrials and academics on topics ranging from Reinforcement Learning, Bandit approaches, to more high-level topics like what it means to evaluate user engagement and the effect of recommender systems.
We also made a surprise announcement for our RecoGym Challenge, starting October 1st. So if you think you have what it takes to implement the winning algorithm for the Recommendation Simulation Environment and get the prize money, participate! It will be fun we promise.
RecSys was a lot of fun this year, and the conference is growing and maturing. We would like to thank the main conference and workshop organizers for the great work!
(Copenhagen was plenty of fun too by the way).
See you next year!
Authors: Romain Beaumont, Amine Benhalloum, Florian Courtial, Ugo Tanielian, Marina Vinyes, Pranjul Yadav