
Here’s How AI is Discovering New Emotions
Semantic Space Theory, an Exciting yet Perilous New Path

After conquering language, Generative AI has set its eyes on conquering a new innately human field, emotion.
In this case, however, it’s not just for the sake of creating a more ‘human’ AI to create a product, but also to debunk the current theories and frameworks that have shaped our understanding of emotions for decades.
Based on decades-long research, we are finally poised to make this happen through semantic space theory (SST).
Thus, this is not yet another GenAI family of products, but a challenge to the status quo, as its principles are also being applied to other exciting fields to discover, among other things, new smells.
This insight and others have mostly been previously shared in my weekly newsletter, TheTechOasis.
If you want to be up-to-date with the frenetic world of AI while also feeling inspired to take action or, at the very least, to be well-prepared for the future ahead of us, this is for you.
🏝Subscribe below🏝
Inductive Obsession
Over the past decades, two grand theories have shaped the understanding of emotion: the “basic six” and dimensional models.
An extreme simplification?
Traditionally, emotions have been classified through several methods, but mostly two.
- Basic Emotions Theory:
Spearheaded by Paul Ekman, the concept of basic emotions is rooted in the idea that certain emotions are fundamental, identifying six basic emotions that were universally recognized across cultures: happiness, sadness, fear, disgust, anger, and surprise.
2. Dimensional Models:
On the other hand, dimensional models classify emotions on continuous scales or dimensions rather than as discrete categories.
A common dimensional model involves two primary dimensions: valence (pleasant-unpleasant) and arousal (activation-deactivation). In layman’s terms, valence signals the positivity or not of the emotion, and arousal the intensity of it.
For example, happiness would be high on valence (pleasant) and vary in arousal, while sadness would be low on valence (unpleasant) and also vary in arousal.
Other popular theories include Plutchik’s Wheel of Emotions, the claim that we have up to 34.000 emotions, and some have proven the critical importance of outlining cultural differences.
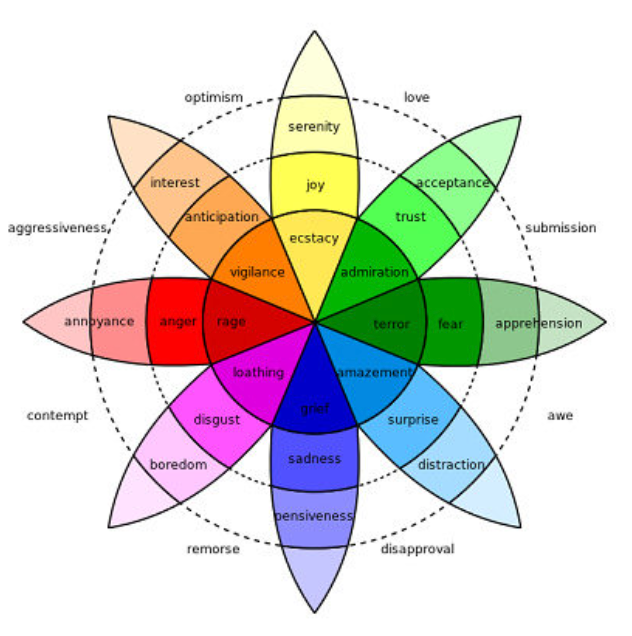
But for quite some time several researchers have put these theories into question.
Going Extremely Empirical
Probably the most notable of these was a UC Berkeley 2017 study, by Dacher Keltner et al, that situated the number at 27 emotions.
Another popular research paper, published in Nature back in 2020 by Alan Cowen et al, found that 16 facial expressions occur in similar contexts worldwide, which helped bridge the gap between cultures.
But what do these two research papers have in common?
Well, unlike the previous theories which were mixed between deductive (departing from several assumptions like stating that all human emotion can be traced into six emotions) and inductive (measuring those assumptions against data), a new type of theory, named semantic space theory (SST), takes a different stance.
Leveraging the power of scale that AI offers, they take on a purely inductive approach. In other words, no assumptions, let the data speak for itself.
Standing on the shoulders of giants like David Hume or Charles Darwin, who argued that the emotion taxonomy was formed by far more than the standard six (16 and 20 types respectively) some companies are on a mission to let the data talk and have started demonstrating some of these theories that had remain unproven for more than a century.
However, to this day, the other more popular theories, especially the ‘basic six’ and the valence/arousal dimensional method, have remained extremely sticky and very much accepted.
But AI might change this.
A Semantic Space of Emotions
Disclaimer: Dacher Keltner and Alan Cowen, the researchers behind semantic space theory, are the Chief Scientific advisor and CEO of Hume, a for profit company with Generative AI products in place.
Let me be cleaer I am not affiliated with or invested in Hume (don’t expect any affiliate links or recommendations in this article).
Also, please be aware that other companies, like Meta or ElevenLabs, might offer similar and competitive products you should benchmark too when deciding what’s best for you.
Despite the extreme disruption we are witnessing daily in the AI industry, it’s nice to see how most innovations can be traced down to the same principles.
Teaching meaning to machines
One of those is semantic similarity, which I would argue is the most important principle in AI today, as this idea not only underpins the research behind SST, but also most frontier models like ChatGPT, Gemini, Stable Diffusion, or Sora. All, without distinction, are based on this idea.
The key difference in this case is that, while ChatGPT isn’t teaching us anything about language, SST is teaching humans new emotions.
But why?
This whole idea of semantic similarity stems from one key problem: how do we teach machines about our world?
If we trace this idea back to its beginnings we arrive at word2vec, a seminal research paper published by Google back in 2014.
I am not exaggerating one single bit if I state that, without this paper, nothing we are seeing today would have taken place unless someone arrived at a similar breakthrough.
Word2Vec’s contributions can be best understood with the “king - man + woman = queen”, where we were capable of transforming words into vectors of numbers that carried the semantic meaning of the underlying words, to the point you could perform arithmetics with them.
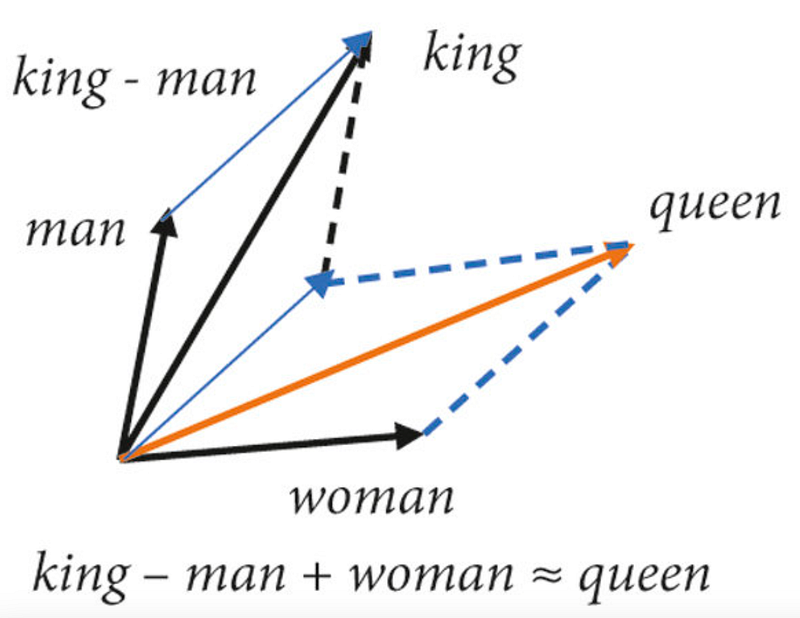
But why on Earth do we want to do this?
Well, for two reasons:
- Necessity: Machines only work with numbers, thus we need to find a way to turn our world into numerical form.
- Turning semantics into mathematics: By performing this transformation, we can turn the process of teaching the semantic similarity of things into a mathematical calculation.
If you think about it, it’s not that different from how humans view the world. For instance, we know that ‘dogs’ and ‘cats’ are similar animals based on their common attributes: four-legged, mammals, domestic, etc.
Thus, to teach an AI model to view the world similarly, we just need to make sure that their vectors, known as embeddings, are similar too.
That takes us to the idea of semantic spaces, a concept you might have seen referred to as latent spaces.
These spaces have one single principle: similar things have similar vectors and, thus, be close by in that space, and dissimilar concepts are pushed apart.
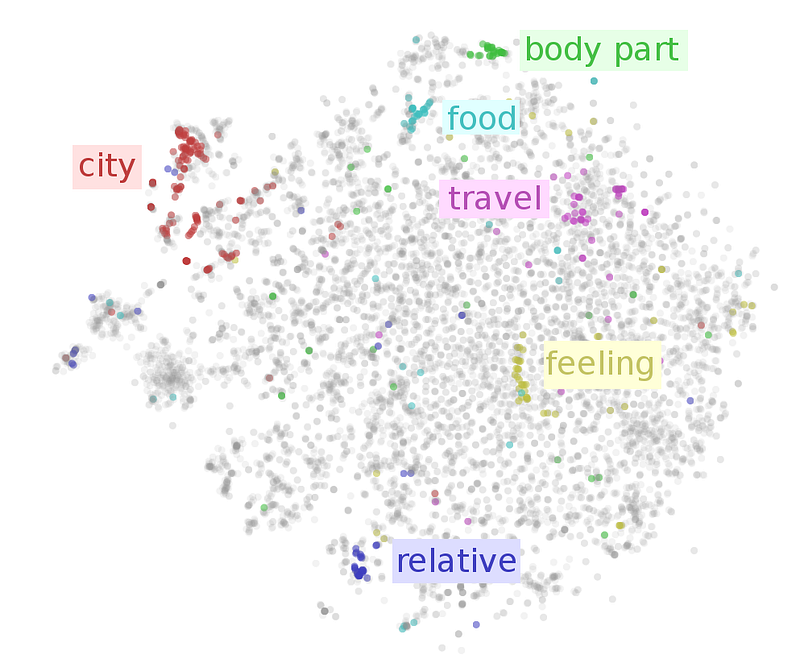
And although it still may not be completely apparent to you, this idea is ubiquitous in AI today for one single reason:
Attention.
Attention is all you need
Based on another seminal research paper, and popularized by the paper that created the Transformer, the attention mechanism has become the golden standard for sequence processing, be that a sequence of words to create text, or a sequence of pixels to create an image.
I won’t get into the details, but the idea is that every unit of semantic information, named tokens (words for text, or groups of pixels for an image, for instance) uses attention to update its meaning with the surrounding context.
For example, in the sentence “I walked down to the river bank”, to avoid confusing ‘bank’ with the financial institution, the ‘bank’ token will pay ‘attention’ to ‘river’ to realize it’s a ‘river bank’.
Thus, although LLMs don’t entirely materialize this semantic space per se, ChatGPT unequivocally works by computing the similarity between concepts in order to process language.
And as mentioned earlier, the same principle stands for images, as the attention mechanism is uncannily similar in that case too.
But how does all this lead us to the main topic of the article, semantic space theory?
Emotion is all you need
The idea is pretty straightforward: Some researchers are trying to classify and discriminate emotions in a high-dimensional semantic space.
In other words, just like ChatGPT might build a semantic space of the English language (a place where ‘dog’ and ‘cat’ are clustered together and far apart from ‘chair’) we can apply this same principle to emotions.
As you can see below, we can cluster speech prosody into different categories like ‘Embarrassment’, or ‘Confusion’.

But the company Hume goes well beyond, applying this principle to other concepts like vocal or facial expressions, or dynamic facial reactions.
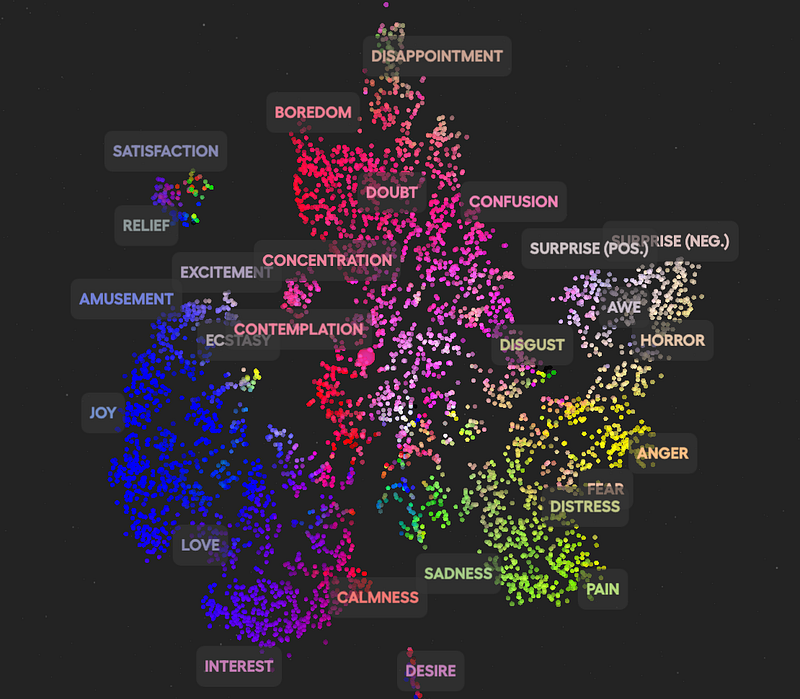
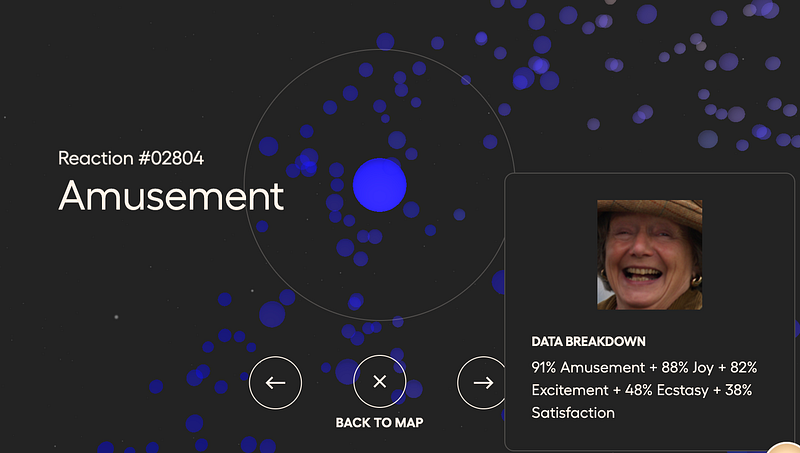
You can try these semantic spaces for yourself here, and explore how they are being used for several generative cases here for voice, and here for text.
What’s more, we can apply these to other modalities. For example, the company Osmo is building a semantic space of smell, allowing us to predict the smell of things and, even, create new ones.
But as I mentioned at the beginning, this concept doesn’t only help us teach machines to discriminate user emotions better, it’s actually the opposite, AI is helping us confirm that, indeed, emotions are much more varied than we initially thought.
AI as a discovery tool
Using semantic spaces, we are using a data-driven approach to proving new theories of emotion that go well beyond our current understanding.
Yet, we are very early in our discovery path, as we should expect these spaces to grow in dimension (increasing the vector sizes) to gain more granularity.
In particular, something I want you to take from reading this article is that my deep dive into Hume’s Semantic Space Theory is just a means to an end, the end being conveying this idea that semantic spaces are a crucial piece in the AI puzzle today and can be applied to many other modalities besides emotion, with examples like the aforementioned Osmo.
On a more tangible level, by leveraging more granular and accurate semantic spaces, we should expect Generative AI products to become much more ‘human’ — not literally — over the next months and years.
But to me, the main takeaway from this piece is how important will AI become, more than a generator, a tool to discover.
- Discovering illnesses through voice: Studies suggest that evaluating voices with AI can help uncover diseases like Parkinson’s, or coronary artery diseases
- Lie detection, by uncovering the intricate patterns in speech prosody, like rhythm or tone, to uncover when someone lies (this is being tested at Hume).
- More empathic AI companions, AI systems that capture our emotions based on our voice or even our texts while not losing billions in the process like Inflection did.
And many more. But as with any AI breakthrough, we must also bear in mind the ethical considerations of such systems.
Let’s not forget the risks
‘More emphatic’ AI systems could be used to:
- deceive others by generating more accurate deepfakes,
- manipulate customers through more tailored and engaging ads,
- perform psychological warfare by optimizing their outputs to induce negative emotions in the user,
- or could even be used for biometric applications or social scoring systems (both of which have been banned by the European Union’s AI Act) but are fairly common in countries like China.
Despite this, the surge of such systems is inevitable, which opens the great question of these days for AI: How are we going to balance the good and bad outcomes?
Nobody knows. And here’s the thing, as long as frontier AI remains ‘for profit’, nobody cares.
On a final note, if you have enjoyed this article, I share similar thoughts in a more comprehensive and simplified manner for free on my LinkedIn.
If preferable, you can connect with me through X.
Looking forward to connecting with you.




