
Heat Map Data Visualization Using Python Plotly: A Hands-on Example
Combining multiple data sets for Plotly heat map creation

We can easily develop an interactive choropleth map (heat map) using Plotly, a useful and powerful Python data visualization library.
Curious to know which U.S. states are leading the charge in electric vehicle (EV) infrastructure?
From Python environment prep, to data sourcing, to map visualization, this step-by-step tutorial will guide you through the entire process.
Step 1: Preparing the Environment
Before we begin, make sure you have Plotly and Pandas installed in your Python environment. If you haven’t, the following command will set you up:
pip install pandas plotly
Next, import the necessary libraries (put this in your code):
import pandas as pd
import plotly.express as pxStep 2: Rustling Up the Data
For this exercise, we want to find the amount of “Electric Vehicle” (EV) charging stations there are per capita in each US state.
To do this, we first need a dataset with all of the EV locations in each state. The key is that we are able to count the total number of EV stations by state.
Next, we need a clean file of state population in order to implement the per-capita ranking.
So if we do the math together, we need two datasets for this task:
- Dataset 1 — List of EV charging stations across the U.S. by statea
- Dataset 2 — Current United States population by state.
To start with, we can find the data on Electric Vehicle sites in the USA here: https://afdc.energy.gov/data_download
On the site, you can select the parameters (alternative fuel stations, fuel type electric) and download the data set.
For the sake of this tutorial, as we are only going to state level, I am interested in ALL of the locations in a state (just the TOTAL count per state).
After cleaning, simplifying, and exporting to CSV, here are the first 10 rows of the file EV_stations_2023.csv:
Street Address,City,State,ZIP
11797 Truesdale St,Sun Valley,CA,91352
1394 S Sepulveda Blvd,Los Angeles,CA,90024
1201 S Figueroa St,Los Angeles,CA,90015
111 N Hope St,Los Angeles,CA,90012
6801 E 2nd St,Long Beach,CA,90803
161 N Island Ave,Wilmington,CA,90744
13201 Sepulveda Blvd,Sylmar,CA,91342
1630 N Main St,Los Angeles,CA,90012
2311 S Fairfax Ave,Los Angeles,CA,90016It is the “State” field that we are most interested in. We just want to count every row that has EV locations in a particular state. So essentially, we should have totals for all 50 states in our data frame.
For our next step, we want to provide a deeper story than just total EV stations (larger states, with more people, probably have more EV stations). We should provide our calculation based on something like number of cars, or population — let’s go with population for this tutorial (per capita).
Researching online, I found a site that has population estimates, here: https://www.census.gov/data/tables/time-series/demo/popest/2020s-state-total.html
After downloading, cleaning, simplifying and exporting the dataset, here arethe first 10 rows of the file US_state_pop_2022.csv:
NAME,2-LETTER,2022_POP
Alabama,AL,5074296
Alaska,AK,733583
Arizona,AZ,7359197
Arkansas,AR,3045637
California,CA,39029342
Colorado,CO,5839926
Connecticut,CT,3626205
Delaware,DE,1018396
District of Columbia,DC,671803
Florida,FL,22244823
Georgia,GA,10912876Now that we have our data sets, we can get started with our Python Code!
Step 3: Processing the Data
We need to load and process both files before loading our map.
Here’s the Python code for how we load them:
ev_df = pd.read_csv('EV_stations_2023.csv')
pop_df = pd.read_csv('US_state_pop_2022.csv')Each row in EV_stations_2023.csv corresponds to a charging station, with the 'State' column indicating its location. The US_state_pop_2022.csv file holds state populations, with '2-LETTER' representing the state and '2022_POP’ indicating the population.
First, we tally the number of EV stations in each state:
state_counts = ev_df['State'].value_counts().reset_index()
state_counts.columns = ['2-LETTER', 'Num_Stations']
print(state_counts.head())We can do a print() statement just to validate our code in our Python console (or comment out/remove it) Next, we merge this with our population data:
state_data = pd.merge(state_counts, pop_df, on='2-LETTER')Now, we calculate the number of EV stations per 100,000 residents for each state:
state_data['Stations_per_100k'] = state_data['Num_Stations'] / state_data['2022_pop'] * 100000We have our ‘Stations_per_100k’ metric, which adjusts the raw station counts relative to the population size.
Super clean, super simple, super quick.
Step 4: Creating the Map
With our data prepared, we can now generate a choropleth (heat) map. Now you might be asking “what’s the difference between a heat map and a choropleth map?”. A choropleth map is basically a heat map, but using geographical boundaries. So you can say it’s a type of heat map.
But back to our code… here’s the code for generating our map:
fig = px.choropleth(state_data,
locations='2-LETTER',
color='Stations_per_100k',
locationmode='USA-states',
title='US EV Charging Stations per 100,000 Residents',
scope='usa',
color_continuous_scale="Viridis")
fig.show()We’re coloring each state based on the number of EV stations per 100,000 residents. The ‘Viridis’ color scale provides a visually pleasing and intuitive representation of our data.
But to make it more relevant for our dataset, we can do some fine-tuning.
Step 5: Fine-Tuning the Map
Adjusting the Color Scale
Let’s tweak the colors to resemble a traffic light for easier interpretation:
fig = px.choropleth(state_data,
locations='2-LETTER',
color='Stations_per_100k',
locationmode='USA-states',
title='US EV Charging Stations per 100,000 Residents',
scope='usa',
color_continuous_scale=["red", "yellow", "green"])
fig.show()You can see in the above code that we’re using the property color_continuous_scale to set our choropleth map color scheme.
Enhancing the Color Bar
For a final touch, let’s make the color bar (the “legend”) more interesting:
fig.update_layout(coloraxis_colorbar=dict(
title="EV Stations per 100k",
x=1,
xanchor="right",
yanchor="middle",
y=0.5,
ticks="outside",
tickvals=state_data['Stations_per_100k'].quantile([.25, .5, .75]).tolist(),
ticktext=["Few Stations", "Medium Stations", "Many Stations"],
lenmode="pixels", len=500,
))
fig.show()This script enhances the color bar. The parametertickvals uses the 25th, 50th, and 75th percentiles of the station counts per 100k to mark the color bar, and ticktext provides custom labels for these markers.
The color bar is vertically centered and placed on the right (x=1, xanchor="right", yanchor="middle", y=0.5), with tick marks on the outside (ticks="outside").
The legend length is set to 500 pixels (lenmode="pixels", len=500).
And voila:
It doesn’t take a lot of code to put together meaningful data visualizations using Plotly. We can see the states that provide the most EV stations per capita — California, Colorado, Vermont, Massacheusetts, Maine.
Now I showed this map to my wife and she mentioned that it makes more sense to reverse the color order — she said in heat maps that red means “go”, it’s where “the action is” (in her words). So we can easily do this by changing the one line in our code, in the choropleth () function:
color_continuous_scale=["red", "yellow", "green"]And the resulting map looks like so:
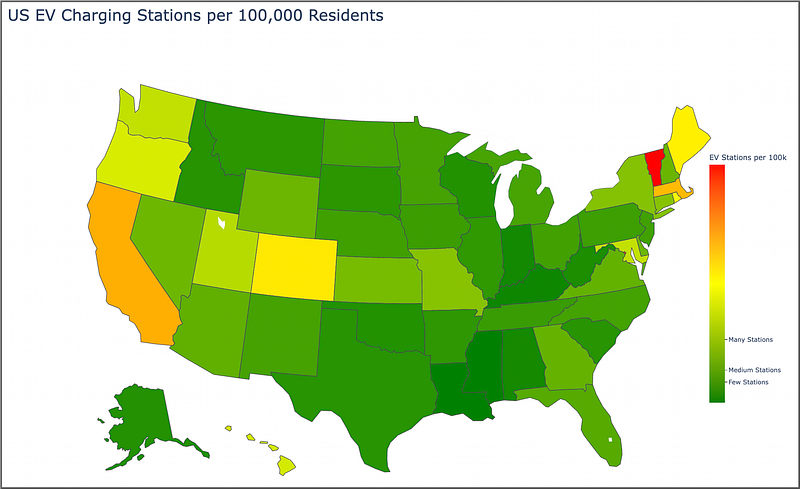
I then showed both maps to my daughter, and she said that the “green one is better than the red one, dad”.
I’m not going to argue with either of them.
So choose the color scheme that works best for you.
In Summary…
And presto! With Python and Plotly, we’ve transformed two separate CSV files into an interactive choropleth map showing the number of EV charging stations per 100,000 residents across the U.S.
Taking advantage of Plotly interactivity, you can hover over each state for more information. As you can probably deduce, green is better in regards to the number of available EV stations based on population size.
This is all just a starting point as there are many visualization tweaks and changes you can make.
Hope this was fun and informative!
Best of luck in your coding!
Before you go… If you want to start writing on Medium yourself and earn money passively you only need a membership for $5 a month. If you sign up with my link, you support me with a part of your membership fee without additional costs.
If you’re interested, here’s a link to more articles I’ve written. There’s articles on Python, Generative AI, Expat living, Marathon training, Travel, and more!
More content at PlainEnglish.io.
Sign up for our free weekly newsletter. Follow us on Twitter, LinkedIn, YouTube, and Discord.