
Heart Failure Prediction in Python!
An end-to-end Machine Learning Task

Cardiovascular diseases (CVDs) are the number 1 cause of death globally, taking an estimated 17.9 million lives each year, which accounts for 31% of all deaths worldwide. Heart failure is a common event caused by CVDs and this dataset contains 12 features that can be used to predict mortality by heart failure.
Most cardiovascular diseases can be prevented by addressing behavioral risk factors such as tobacco use, unhealthy diet and obesity, physical inactivity, and harmful use of alcohol using population-wide strategies.
People with cardiovascular disease or who are at high cardiovascular risk (due to the presence of one or more risk factors such as hypertension, diabetes, hyperlipidemia, or already established disease) need early detection and management wherein a machine learning model can be of great help.
In this article, we are going to predict what different factors are responsible for Heart Failure.
Let’s start by importing the libraries that we will need for this project.
I prefer to use google collaboratory whenever I work with machine learning datasets as it provides GPU support and a lot of preloaded libraries. For loading the datasets in google collab we will use the following code.
Now we will read the uploaded CSV file(the dataset) using the pandas library.
The Dataset:

Now we will perform exploratory data analysis.
From above we infer that our dataset contains 299 instances and 13 features. Furthermore, there are no missing values.
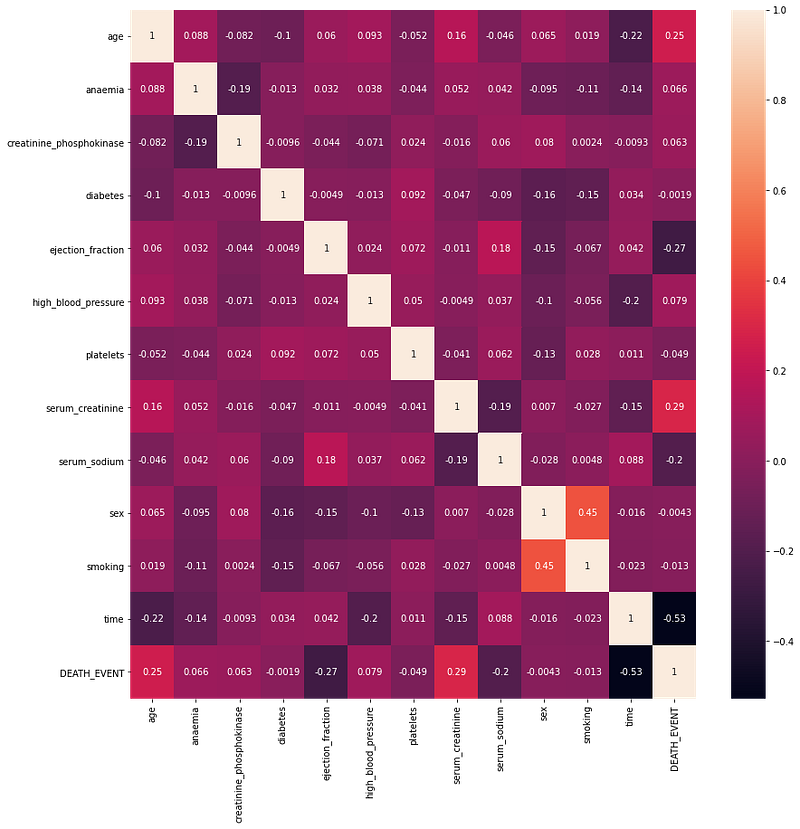
Let’s now plot a heatmap to better understand the correlation between the features.
For checking the distribution of the dataset we will plot the density chart of each feature.
For checking the outliers in the dataset we will plot the box plot of each feature.
After this, we will explore each feature in the dataset separately.
For the Age feature, we will build a new feature by putting the age groups into and exploring.
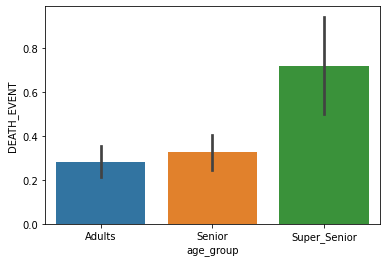
Percentage of Super Senior people lose their life: 72.22222222222221. People whose age is more than 80 yrs are more prone to heart failure.
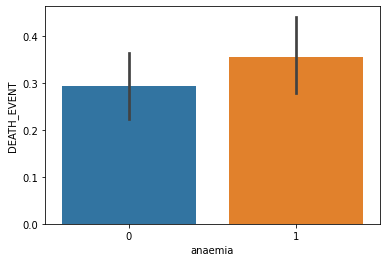
Anemia: Decrease of red blood cells or hemoglobin
Creatinine Phosphokinase: Level of the CPK enzyme in the blood
As we know the Total CPK normal values: 10 to 120 micrograms per liter (mcg/L).
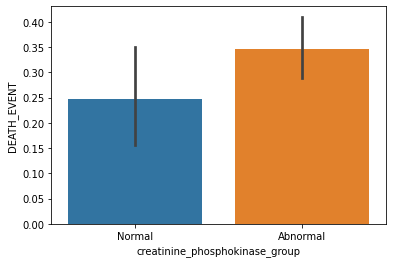
People who have an abnormal level of the CPK enzyme in the blood are more prone to heart failure.
Diabetes
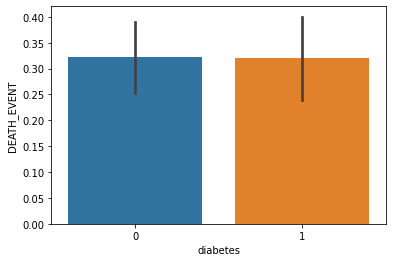
Having diabetes doesn’t matter in case of heart failure.
Moreover from the heatmap, we get that the correlation between Death event and diabetes is very less i.e -0.001943.
Ejection Fraction: Percentage of blood leaving the heart at each contraction
bins = [0, 41, 50, 70, np.nan]
labels = ['too low', 'borderline', 'Normal', 'high']
data['ejection_fraction_category'] = pd.cut(data['ejection_fraction'], bins=bins, labels=labels)
data['ejection_fraction_category'].value_counts()
sns.barplot(x='ejection_fraction_category', y='DEATH_EVENT', data=data)
plt.show()The result of the value count will be
too low 219
borderline 41
Normal 38
high 1
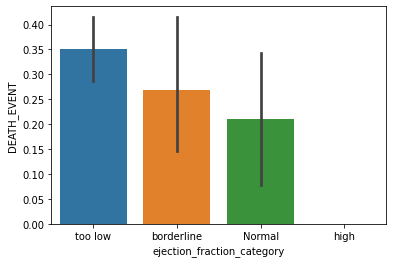
If a person’s ejection_fraction is in the too low category then they have more chances of Heart Failure.
High Blood Pressure
sns.barplot(x='high_blood_pressure', y='DEATH_EVENT', data=data)
plt.show()
print('Percentage of people resulted in Heart Failure having high blood pressure : ', data['DEATH_EVENT'][data['high_blood_pressure']==1].value_counts(normalize=True)[1]*100)Percentage of people who resulted in Heart Failure having high blood pressure: 37.142857142857146
The person having high blood pressure is more to heart failure.
Platelets : Platelets in the blood (kiloplatelets/mL)
bins =[0, 150000, 250000, np.nan]
labels =['low', 'normal', 'high']
data['platelets_category'] = pd.cut(data['platelets'], bins=bins, labels=labels)
sns.barplot(x='platelets_category', y='DEATH_EVENT', data=data)
plt.show()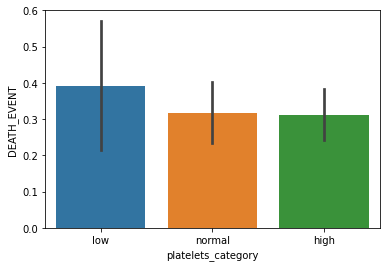
In this way, one can check the relation of all the independent features with the dependent feature.
After performing the Data Visualization we will now separate the dataset into input and output features.
Remember we have saved a copy of our dataset and for building the model we will use that which is the original dataset.
Now we will split the dataset into train and the test sets using the train_test_split.
Now we will perform scaling and feature selection on the training dataset.
Note: We will not perform these operations on the whole dataset as it will lead to bias.
We will apply the Standard Scalar to our training dataset. This can be done as follows :
Also, we will perform the feature selection.
We will use the Recursive Feature Elimination Technique(RFE) to do so.
The Output:

As we can see we have selected the 6 best features from our dataset which we will use for model building.
After that, we will now spot-check different algorithms to find the best algorithms for the given dataset.
The accuracy of the different algorithms comes out to be
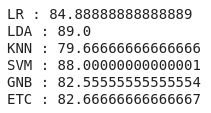
We will also plot this using the box for better understanding.
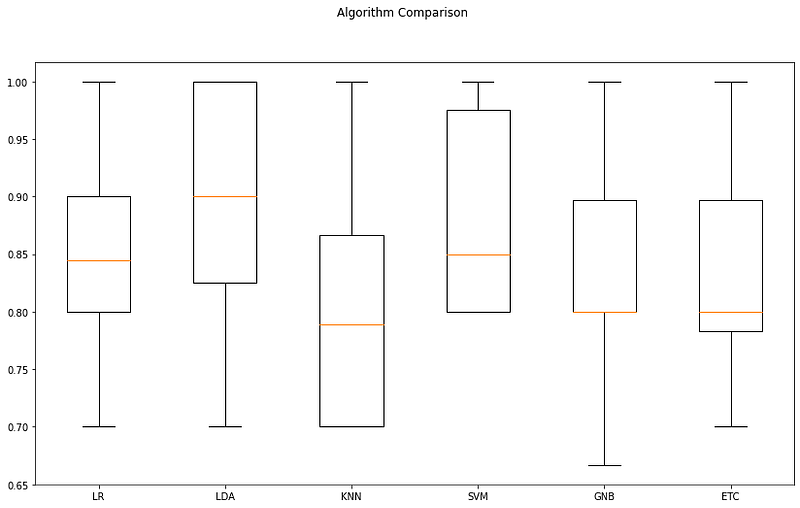
Thus, we will select is the Linear Discriminant Analysis which has the maximum accuracy of 89%.
Finally, we will now build a pipeline and train our model.
steps = [('scaler', StandardScaler()),
('RFE', RFE(LogisticRegression(), 6)),
('lda', LinearDiscriminantAnalysis())]
pipeline = Pipeline(steps)
pipeline.fit(x_train, y_train)
predictions = pipeline.predict(x_test)
print('The accurcay score of the test dataset : ', accuracy_score(y_test, predictions))
print('\nThe confusion matrix : \n', confusion_matrix(y_test, predictions))
print('\nFinally the classification report : \n', classification_report(y_test, predictions))
print('Score : ', pipeline.score(x_test, y_test))The output:
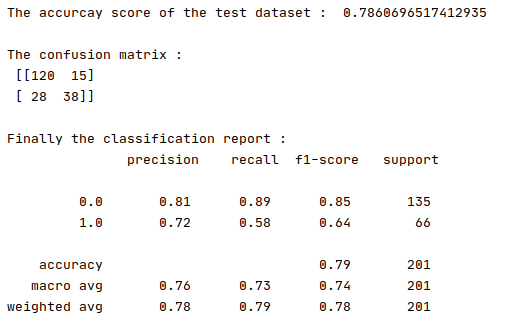
The accuracy score of the test dataset comes out to be 78.6% which is pretty good as we are checking the accuracy score of the unseen data.
Now finally we will save our model using pickle.
# saving the model
pickle.dump(pipeline, open('model.pkl', 'wb'))Link to my previous articles:





