
Hands-On LangChain for LLMs App: Answering Questions From Documents
In the previous articles of this series, we discussed how to load documents, split them, and then find documents related to a specific question. Now, let’s take the next step: using those documents and the original question to get an answer from a language model.
This article will walk you through the process, explaining different ways to do question answering with the documents you’ve found. After sorting out storage and getting the right data, we’re now at the point where we use a language model to find the answers we need.

Table of Contents:
- Overall Workflow for Retrieval Augmented Generation (RAG)
- Getting Started & Setting Environment Variables
- Prompt Development for RetrievalQA
- RetrievalQA with Map Reduce & Refined Chain
- RetrievalQA Limitations
Most insights I share in Medium have previously been shared in my weekly newsletter, To Data & Beyond.
If you want to be up-to-date with the frenetic world of AI while also feeling inspired to take action or, at the very least, to be well-prepared for the future ahead of us, this is for you.
🏝Subscribe below🏝 to become an AI leader among your peers and receive content not present in any other platform, including Medium:
1. Overall Workflow for Retrieval Augmented Generation (RAG)
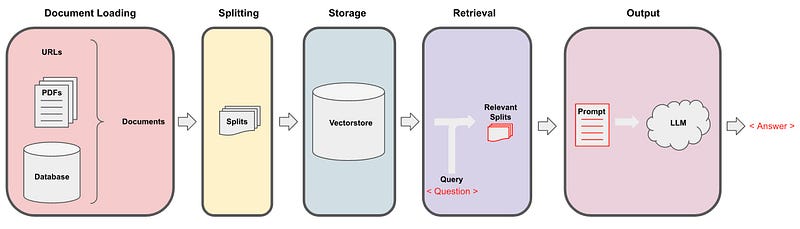
The general flow for this goes, the question comes in, we look up the relevant documents, we then pass those splits along with a system prompt and the human question to the language model and get the answer. By default, we just pass all the chunks into the same context window, into the same call of the language model. However, there are a few different methods we can use that have pros and cons to that. Most of the pros come from the fact that sometimes there can be a lot of documents and you just simply can’t pass them all into the same context window. MapReduce, Refine, and MapRerank are three methods to get around this issue of short context windows, and we’ll cover a few of them in the lesson today
2. Getting Started & Setting Environment Variables
Let's start first with loading our environment variables and the important packages that we will be using in this article:
import os
import openai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']We will then load in our vector database that was persisted in previous articles. We will then check that it is correct.
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = 'docs/chroma/'
embedding = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
print(vectordb._collection.count())209
We can see that it has the same 209 documents from before. Let's also do a quick check of similarity search to make sure it’s working. We will ask the following question: what are the major topics for this class?
question = "What are major topics for this class?"
docs = vectordb.similarity_search(question,k=3)
len(docs)3
Now, we initialize the language model that we’re going to use to answer the question. We’re going to use the chat open AI model, GPT 3.5, and we’re going to set the temperature equal to zero. This is a good option when we want factual answers to come out because it’s going to have low variability and usually just give us the highest fidelity, most reliable answers.
from langchain.chat_models import ChatOpenAI
llm_name = 'gpt-3.5-turbo'
llm = ChatOpenAI(model_name=llm_name, temperature=0)Finally, we are then going to import the retrieval QA chain. This is doing question-answering backed by a retrieval step. We can create it by passing in a language model, and then the vector database as a retriever. We can then call it with the query being equal to the question that we want to ask. And then when we look at the result, we get an answer.
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever()
)
result = qa_chain({"query": question})
result["result"]‘The major topics for this class are machine learning and its various extensions.’
We can see from the answer that the major topic for this class is machine learning. Additionally, the class may cover statistics and algebra as refreshers in the discussion sections.
3. Prompt Development for RetrievalQA
Let’s try to understand a little bit better what’s going on underneath the hood and expose a few of the different knobs that you can turn. One of the main important parts here is the prompt that we’re using.
This is the prompt that takes in the documents and the question and passes it to a language model. Let's start with defining a prompt template. It has some instructions about how to use the following pieces of context, and then it has a placeholder for a context variable. This is where the documents will go, and a placeholder for the questions variable.
from langchain.prompts import PromptTemplate
# Build prompt
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum. Keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)We can now create a new retrieval QA chain. We’re going to use the same language model as before and the same vector databases as before, but we’re going to pass in a few new arguments. We’ve got the return source document argument set to true. This will let us easily inspect the documents that we retrieve. Then we’re also going to pass in a prompt equal to the QA chain prompt that we defined above.
# Run chain
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)Let’s try out a new question “Is probability a class topic?” and then we will print the answer we got.
question = "Is probability a class topic?"
result = qa_chain({"query": question})
result["result"]
‘Yes, probability is a topic that will be covered in the class. Thanks for asking!’
We can see that probability is covered in the class. It was very nice when it responded to us as well. For a little bit better intuition as to where it’s getting this data from, we can take a look at some of the source documents that were returned. If you look through them, you should see that all the information that was answered is in one of these source documents.
result["source_documents"][0]Document(page_content=”of this class will not be very program ming intensive, although we will do some \nprogramming, mostly in either MATLAB or Octa ve. I’ll say a bit more about that later. \nI also assume familiarity with basic proba bility and statistics. So most undergraduate \nstatistics class, like Stat 116 taught here at Stanford, will be more than enough. I’m gonna \nassume all of you know what ra ndom variables are, that all of you know what expectation \nis, what a variance or a random variable is. And in case of some of you, it’s been a while \nsince you’ve seen some of this material. At some of the discussion sections, we’ll actually \ngo over some of the prerequisites, sort of as a refresher course under prerequisite class. \nI’ll say a bit more about that later as well. \nLastly, I also assume familiarity with basi c linear algebra. And again, most undergraduate \nlinear algebra courses are more than enough. So if you’ve taken courses like Math 51, \n103, Math 113 or CS205 at Stanford, that would be more than enough. Basically, I’m \ngonna assume that all of you know what matrix es and vectors are, that you know how to \nmultiply matrices and vectors and multiply matrix and matrices, that you know what a matrix inverse is. If you know what an eigenvect or of a matrix is, that’d be even better. \nBut if you don’t quite know or if you’re not qu ite sure, that’s fine, too. We’ll go over it in \nthe review sections.”, metadata={‘source’: ‘docs/cs229_lectures/MachineLearning-Lecture01.pdf’, ‘page’: 4})
4. RetrievalQA with Map Reduce & Refined Chain
So far, we’ve been using the default technique which simply stuffs all the documents into the final prompt. This is good because it only involves one call to the language model.
However, this does have the limitation that if there are too many documents, they may not all be able to fit inside the context window. A different type of technique that we can use to do question answering over documents is the map-reduce technique.
In this technique, each of the individual documents is first sent to the language model by itself to get an original answer. And then those answers are composed into a final answer with a final call to the language model. This involves many more calls to the language model, but it does have the advantage that it can operate over arbitrarily many documents. We can define it using the code below:
qa_chain_mr = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
chain_type="map_reduce"
)Let's run to the previous question and use the map reduce chain:
result = qa_chain_mr({"query": question})
result["result"]‘Based on the provided information, it is not clear whether probability is a specific topic covered in the class.’
There are two limitations to this method. First, it’s a lot slower because it how it works as it has to do multiple calls to the LLM. Second, the result is worse. There is no clear answer to this question based on the given portion of the document. This may occur because it’s answering based on each document individually. And so, if there is information that’s spread across two documents, it doesn’t have it all in the same context.
We can overcome this by using the refined chain as it allows you to combine information, albeit sequentially, and it encourages more carrying over of information than the MapReduce chain.
qa_chain_mr = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
chain_type="refine"
)
result = qa_chain_mr({"query": question})
result["result"]‘The prerequisites for the class are needed to ensure that students have a solid foundation in computer science and basic computer skills. This is important because machine learning has emerged as a powerful tool in various fields, including artificial intelligence and autonomous systems. The class aims to provide students with a broad set of principles and tools that will be useful for many applications. For example, machine learning algorithms are used in tasks like handwriting recognition and autonomous flight, which are difficult to program manually. By having the necessary prerequisites, students will be equipped with the knowledge and skills to effectively apply machine learning algorithms and tackle real-world problems in diverse domains.’
5. RetrievalQA Limitations
One of the great things about chatbots and why they’re becoming so popular is that you can ask follow-up questions. You can ask for clarification about previous answers. So, let’s do that here. Let’s create a QA chain with default settings.
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever()
)We will ask it the previous question about probability and then let’s ask it a follow-up question.
question = "Is probability a class topic?"
result = qa_chain({"query": question})
result["result"]‘Yes, probability is a topic that will be covered in this class. The instructor assumes familiarity with basic probability and statistics, so it is expected that students have prior knowledge in this area.’
It mentions that probability should be a prerequisite, so let’s ask, why are those prerequisites needed?
question = "why are those prerequesites needed?"
result = qa_chain({"query": question})
result["result"]‘The prerequisites for the class are needed because the instructor assumes that all students have a basic knowledge of computer science and basic computer skills and principles. This is important because the class will cover advanced topics in machine learning that build upon these foundational concepts. Understanding topics like big-O notation and basic computer skills will be necessary for comprehending and applying the machine learning algorithms taught in the class.’
The prerequisites for the class are assumed to be basic knowledge of computer science and basic computer skills and principles. That doesn’t relate at all to the answer before where we were asking about probability. The chain that we’re using doesn’t have any concept of state. It doesn’t remember what previous questions or previous answers were. For that, we’ll need to introduce memory, and that’s what we’ll cover in the next article.
If you like the article and would like to support me, make sure to:
- 👏 Clap for the story (50 claps) to help this article be featured
- Subscribe to To Data & Beyond Newsletter
- Follow me on Medium
- 📰 View more content on my medium profile
- 🔔 Follow Me: LinkedIn |Youtube | GitHub | Twitter
Subscribe to my newsletter To Data & Beyond to get full and early access to my articles:
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
- Mentoring sessions: https://lnkd.in/dXeg3KPW
- Long-term mentoring: https://lnkd.in/dtdUYBrM




