
Hadoop vs. Spark — What to choose and when to choose
Processing and analyzing large datasets is a common challenge for businesses in today’s data-driven world. Hadoop and Spark are two of the most popular open-source big data processing frameworks, which are used for managing and analyzing data at scale.

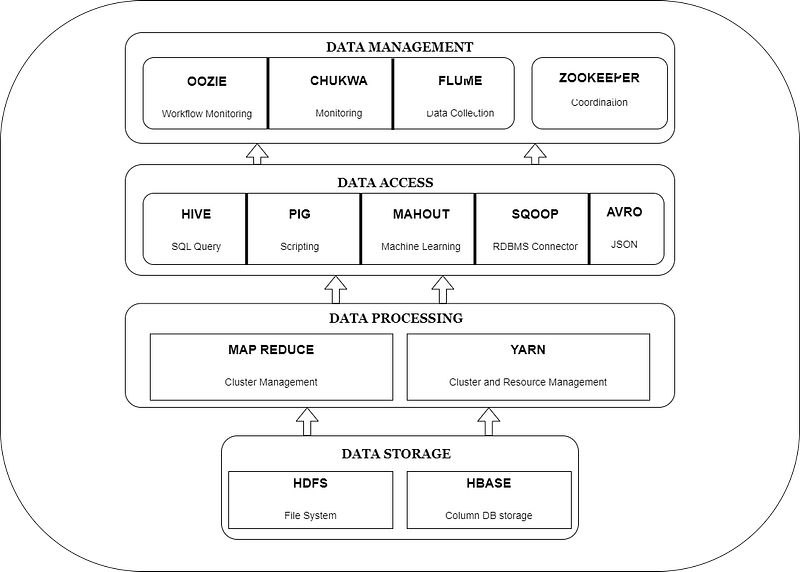
Apache Hadoop
Hadoop is a batch processing system, that is designed to store and process large amounts of data across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering computation and storage.
What are we referring to when we are saying programming models? What are those exactly? (a programming model is basically a recipe — in cooking — you have a list of ingredients and instructions on how to mix and bake them to get a cake, similarly, a programming model gives a computer a set of instructions on how to process large amounts of data — like sorting & counting — by breaking it into smaller parts and working on them all at the same time — introducing thus the concept of parallelism)
Well, Hadoop has at its core two programming models:
1. MapReduce — a programming model that simplifies the processing of large datasets by dividing the work into smaller tasks that can be performed in parallel across a distributed computer cluster. It consists of two phases:
- the map phase — which processes and filters the data.
- the reduce phase — which aggregates & summarizes the data.
2. HDFS(Hadoop Distributed File System) API — a programming model that provides an interface for accessing and manipulating large files stored across multiple nodes in the Hadoop cluster. It’s a scalable and fault-tolerant way to store and retrieve large amounts of data.
It is important to know that on-premises Hadoop clusters have a number of limitations (compared to Hadoop clusters on cloud):
- Not elastic (it does not automatically adjust its computing resources — such as CPU, memory & storage — to meet the demands of the workload) → this is appropriate when the workload is predictable and consistent, and the resources are optimized in order to meet the demands of that workload.
- Hard to scale fast (adding new hardware to an on-premises Hadoop cluster requires proper configuration and allocation of resources such as CPU, memory, and storage. This process can be complicated and time-consuming, especially if the cluster is not designed for easy scaling).
- No separation between storage & compute resources (in this configuration, the servers in the cluster serve both as data storage nodes and processing nodes. When a Hadoop job is submitted, it is executed on the same set of nodes that are storing the data that is required for the job. This can result in high data transfer overhead and resource contention).
Apache Spark
Spark is an open-source, in-memory data processing engine, which handles big data workloads. It is designed to be used on a wide range of data processing tasks, including batch processing, real-time processing, machine learning, graph processing, and interactive SQL queries.
One of the key advantages of Spark is the ability to perform in-memory processing, which is way faster than the traditional disk-based processing.
Now you will be asking yourself, what’s really the difference? Well, in-memory processing means that the data is loaded into memory(RAM) and processed there, WITHOUT having to read from and write to a disk → a useful idea when an application needs to process large amounts of data quickly — real-time processing, machine learning, etc.
Disk-based processing, involves reading from & writing to a disk, which basically implies two more processes that take time, and thus…it’s slower than in-memory processing → it’s useful when we are dealing with a huge amount of data that does not fit into memory, as it allows the data to be stored on disk and processed in chunks.
Also, Spark uses a Resilient Distributed Dataset (RDD) concept to manage data across a cluster of machines, allowing for efficient parallel processing and fault tolerance.
— Resilient = refers to the fault-tolerance mechanism that Spark uses to recover from failures — each RDD is divided into partitions, which are distributed across different machines(nodes) in the cluster; if one fails, the data that’s found in the failed machine, can be reconstructed from the data in other partitions — and thus, it ensures that the processing can continue, even if some machines are failing.
— RDDs can be cached in memory, so that the frequently accessed data is easily retrieved.
Hadoop vs. Spark
There are some key differences between Hadoop and Spark, such as:
- SPEED — Spark is generally faster than Hadoop, because it can process data in memory (RAM).
- DATA PROCESSING — Hadoop is better suited for batch processing of large volumes of data, while Spark is more versed for iterative and interactive data processing.
- ECOSYSTEM — Hadoop is a more mature ecosystem and is well-suited for a range of data processing tasks, while Spark has a more focused ecosystem that is particularly strong in machine learning and real-time processing.

On-premises Hadoop/Spark vs. on cloud
The choice between on-premises and on cloud depends on a number of factors, such as: company budget, infrastructure, and use case.
On-premises Hadoop and Spark can be a good choice for organizations that have the necessary IT infrastructure and expertise to support these technologies. However, on-premises solutions can require a significant up-front investment in hardware, software, and IT personnel, and may not be as flexible or scalable as cloud-based solutions.
Cloud-based Hadoop and Spark solutions, on the other hand, can offer organizations greater flexibility and scalability, as well as faster deployment times and potentially lower up-front costs. However, cloud-based solutions may not provide as much control over data and applications as on-premises solutions, and may require ongoing costs for data storage and processing.
Google Cloud offers the product Dataproc, which allows an user to create Spark/Hadoop clusters. You can manage the data, by using Google Cloud Storage.
While AWS offers EMR(Elastic MapReduce) for Hadoop/Spark clusters and you can manage the data through S3(Simple Storage Service).
Real-world examples of Hadoop and Spark implementations
Hadoop:
— Social Media Analysis: Hadoop enables businesses to easily access new data sources and tap into different types of data (structured & unstructured) to generate insights from that data. See how Twitter uses the Hadoop filesystem.
— Search Optimization: Hadoop enables businesses to improve the search experience, by identifying and optimizing relevant advertisements, and performing click stream analysis. For more details, see how eBay uses Hadoop to improve their search experience.
Spark:
— Content Personalization: Netflix uses Spark to analyze viewer data and provide personalized recommendations to its users. Spark helps Netflix process and analyze large amounts of data in real-time, allowing it to provide more accurate and relevant recommendations to its users.
— Content Delivery: Netflix uses Spark to optimize its content delivery network (CDN), and thus they analyze user viewing patterns and optimize its CDN to deliver content more quickly and efficiently. You can read more about how Netflix uses Spark in here.
Wrap-up
In conclusion, both Spark and Hadoop have their own unique strengths and use cases. By understanding these differences, you can make informed decisions about which technology to use for your data processing needs. Whether you are dealing with massive amounts of data or looking to build real-time processing pipeline, there is a solution out there for you!
Thanks a lot for reading!
In this article we covered a bit the differences between Apache Spark and Apache Hadoop, and soon enough I will be adding a couple of projects that we can work together on, sooo…stay tuned!
Any feedback or questions are highly welcomed and appreciated!





