
Gradient Boosted Trees for Regression Explained
With video explanation | Data Series | Episode 11.5

Building Gradient Boosted Trees for Regression
To understand how gradient boosted trees for regression works, let us go through step-by-step how to build gradient boosted trees on the following fake test score data to predict a student’s test score.
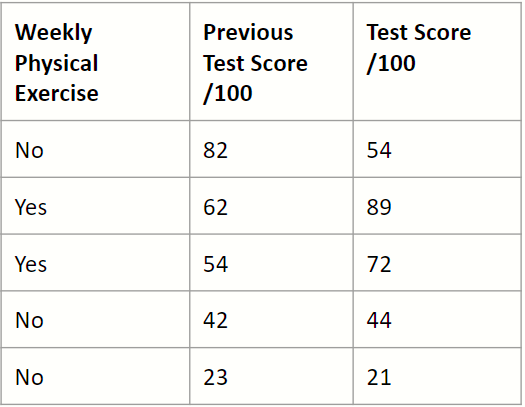
1. Calculate the mean of our target variable, test score.
This forms our initial prediction:

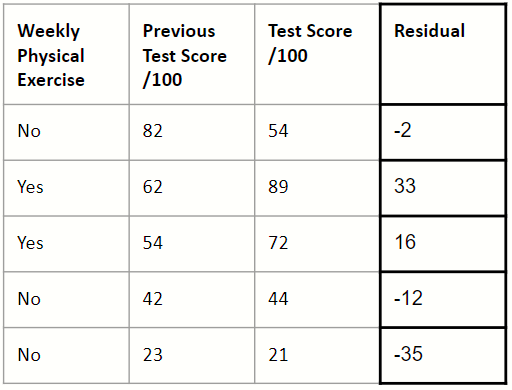
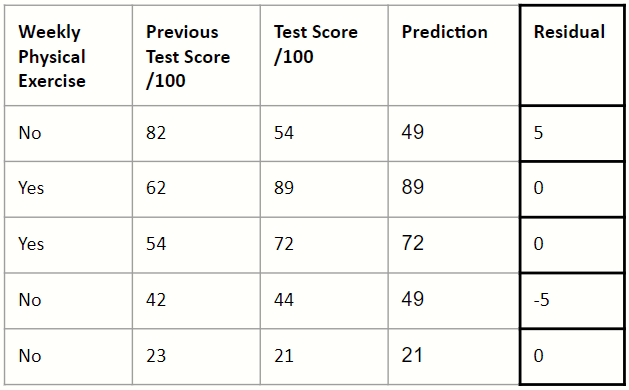
2. Calculate the residuals
The residuals are given by the following formula:

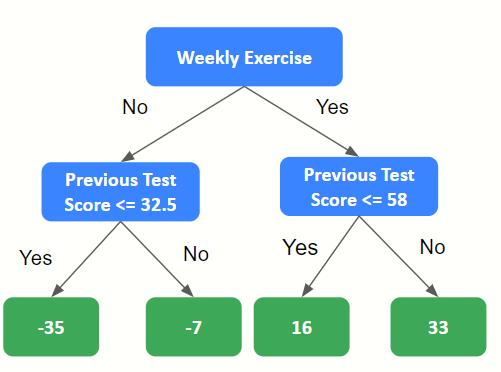
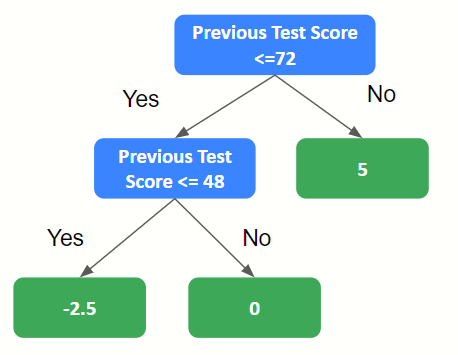
3. Build a decision tree to predict the residuals
Here we use Weekly Physical Exercise and Previous Test Score/100 to predict Residual.
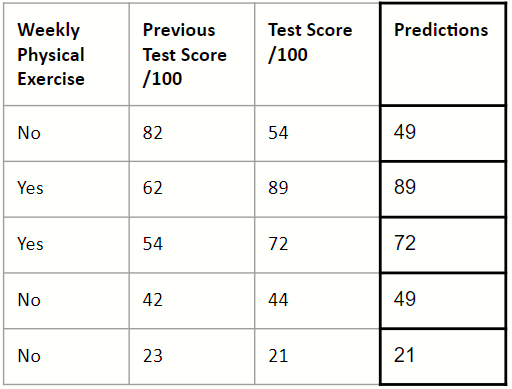
4. Combine the outputs to form a new set of predictions
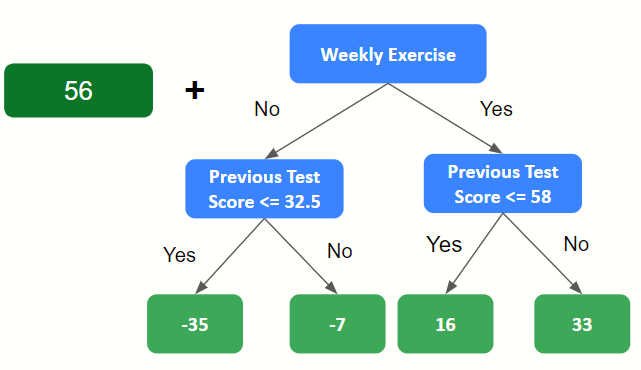
Adding our average test score to the outputs of the decision tree produces the following predictions:
5. Calculate a new set of residuals

6. Build a decision tree on the new set of residuals
7. Combine outputs to form a new set of predictions
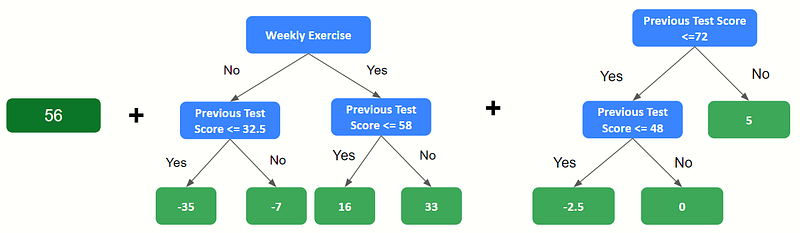
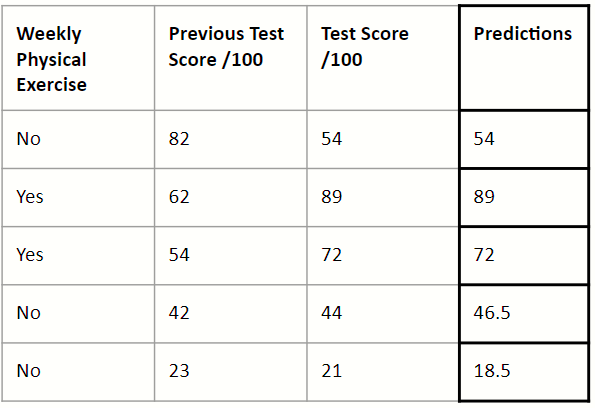
8. Keep generating a new sets of residuals, building decision trees and forming predictions until user defined parameters are satisfied.
User defined parameters may be for example the number of trees specified.
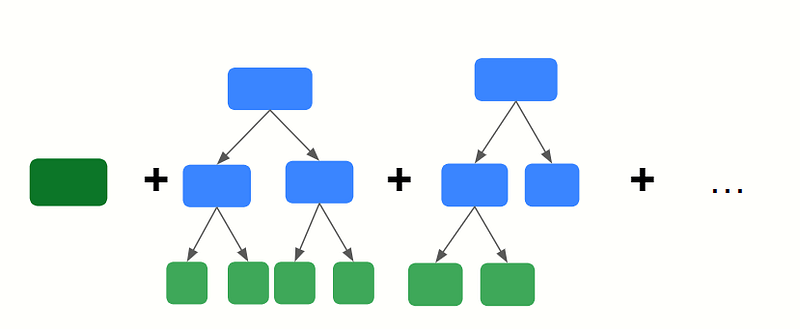
In Summary
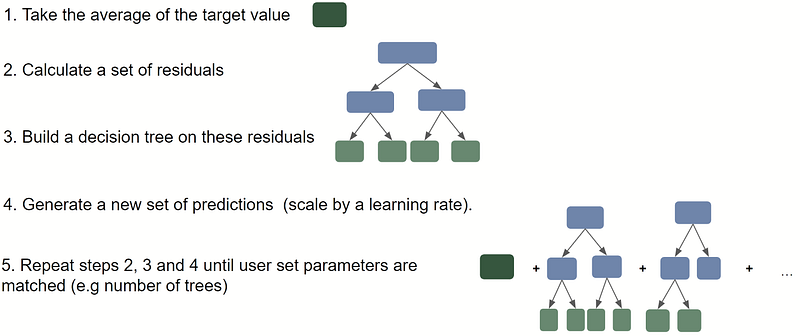
Dealing with Overfitting
Notice how in the above example we managed to get exact predictions very quickly.
Gradient boosted trees without adjustment can often overfit our data. That is, it fits the training data too well.
This is bad, since the model can struggle with predicting new observations.
The Learning Rate
To deal with this we introduce what is called the learning rate γ.
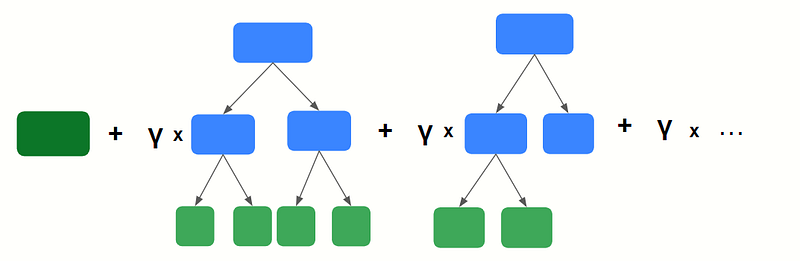
Setting γ = 0.15 would scale our decision tree outputs by this value.
Let us take a look at what would happen when we introduce the learning rate after the first decision tree is built:
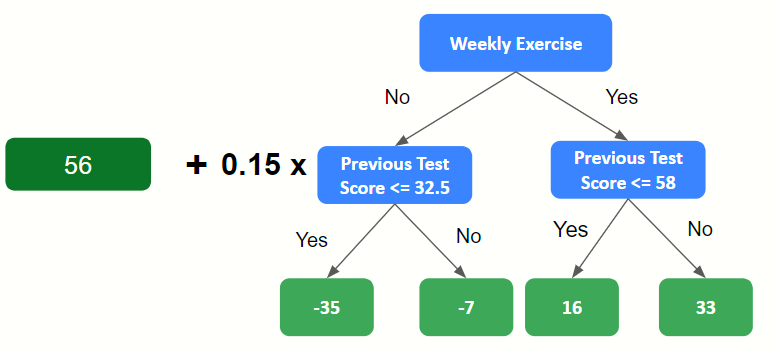
Taking a look at the first two entries:
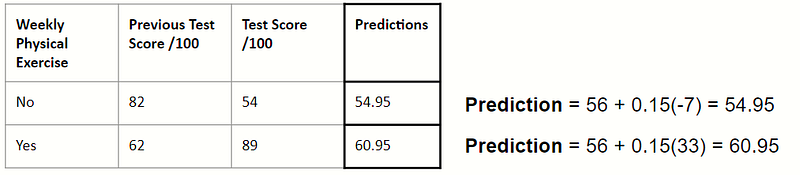
Although not as accurate as before, we have managed move towards our target value with a smaller step.
This decreases the variance of the algorithm and helps prevent overfitting.
Advantages and Disadvantages of Gradient Boosted Trees
Advantages
- Gradient boosted trees are able to capture complex relationships in data often leading to high algorithm performance.
- The algorithm has parameters that be tuned for better performance such as setting the learning rate, number and depth of the trees.
- Can be interpreted to give the importance of different features in predicting a target variable.
Disadvantage
- Can overfit the training data without proper adjustment.




