
GPT-Neo vs. GPT-3: Are Commercialized NLP Models Really That Much Better?
By Zilun Peng and Akshay Budhkar
Hi there! This is the first blog post in a series on GPT-3. If you’re interested in this and other applied research work, you can follow us on twitter here and here.
GPT-3 is the latest language model from OpenAI. It garnered a lot of attention last year when people realized its generalizable few-shot learning capabilities, as seen in articles like OpenAI’s new language generator GPT-3 is shockingly good — and completely mindless and What Is GPT-3 And Why Is It Revolutionizing Artificial Intelligence?. GPT-3’s generative text-in text-out setup allows people to use this model for virtually any English natural language processing (NLP) task. [Brown et al. 2020] showed that GPT-3 performed strongly on many NLP tasks. Researchers have achieved excellent results applying GPT-3 to tasks like generating SQL code, writing like an attorney and answering math questions. We believe GPT-3 will usher in a new paradigm in AI adoption by opening the field to non-technical folks and creating a new class of few-shot learning products.
Unfortunately, OpenAI hasn’t yet open-sourced GPT-3 (as of April 2021). API access to GPT-3 from OpenAI is available on an application-only basis, and it can take months to get approved. The open-source community has engaged in attempts to reproduce the model weights and results. eleuther.ai recently open-sourced GPT-Neo, a language model with a very similar architecture to GPT-3. They have achieved excellent results on metrics like perplexity scores, as seen here. Following this release, the folks over at Hugging Face pushed this endeavor further by adding GPT-Neo into their transformers toolkit, making it available to anyone to run this model!

There are four publicly available models in the GPT-3 family: ada, babbage, curie, davinci. OpenAI has not publicly stated the exact sizes. They describe ada as the fastest (and the cheapest) and davinci as the most capable (and the most expensive). In their paper [Brown et al. 2020] introduced eight versions of GPT-3. The top four largest ones range from 2.7 billion to 175 billion parameters. Based on this, we speculate that ada has 2.7 billion parameters; babbage has 6.7 billion parameters; curie has 13 billion parameters and davinci has 175 billion parameters. GPT-Neo’s models are named after the number of parameters: GPT-Neo 1.3B and GPT-Neo 2.7B.
At Georgian, we’re excited about what GPT-Neo can do and how it performs against GPT-3. We tested GPT-Neo against GPT-3 on two tasks: title generation and sentiment classification, to compare them both qualitatively and quantitatively. Our results show that GPT-Neo (in many cases with fewer parameters) is not far behind GPT-3. GPT-Neo can generate mind-blowing titles, just like GPT-3, and accurately classify sentiment with only a few labeled examples. These results show that GPT-Neo is an effective few-shot learner that people can use to design new AI systems right away!
Task 1: Title Generation
Vasili Shynkarenka wrote a fascinating blog post explaining how he used GPT-3 to generate eye-catching titles for five of his blog posts. He described the title generation task and provided a few samples to GPT-3 to leverage its few-shot learning capabilities. After some trial and error — and some clever transformations — he gave GPT-3 a description, and it was able to generate attention-worthy titles for his posts.
We were intrigued by the creativity of GPT-3 and wanted to test GPT-Neo with the same task. There are three parts to the input. Vasili started by describing the task to GPT-3:
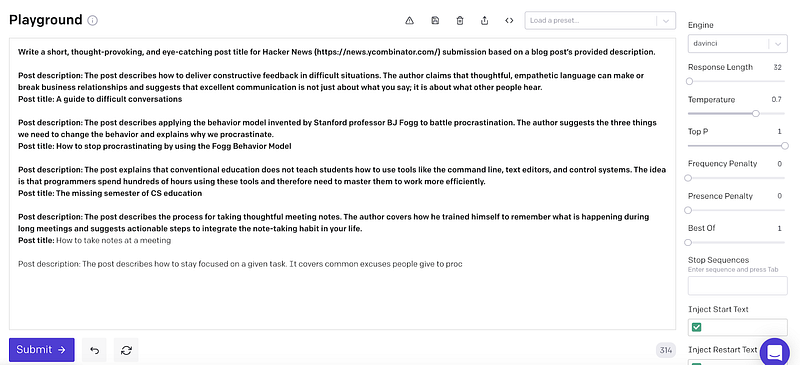
Write a short, thought-provoking, and eye-catching post title for Hacker News (https://news.ycombinator.com/) submission based on a blog post’s provided description.
Vasili then provided three demonstrations, i.e., three pairs of successful post summaries and their titles. These samples prompt GPT-3 to learn how to transform any of these posts into catchy headlines.
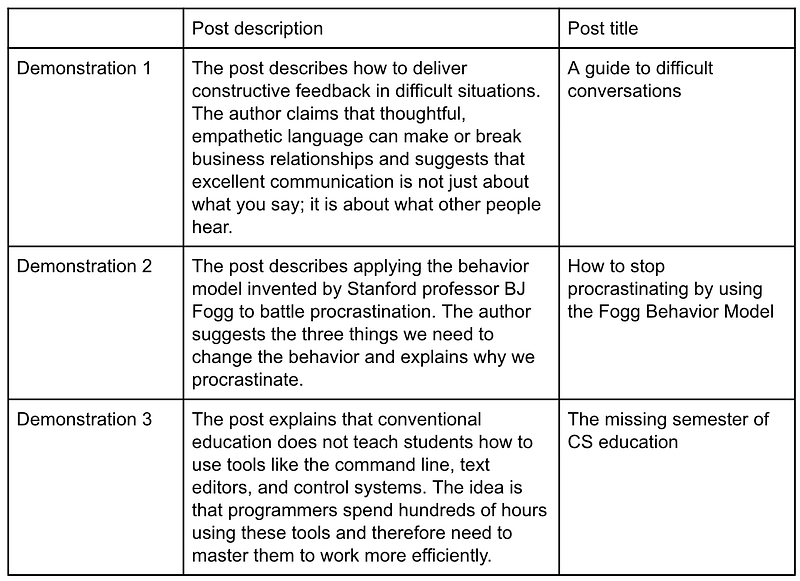
Finally, for this example, Vasili then described the post that he wanted GPT-3 to generate a title:
The post describes the process for taking thoughtful meeting notes. The author covers how he trained himself to remember what is happening during long meetings and suggests actionable steps to integrate the note-taking habit in your life.
What Is the Prompt?
To form a complete prompt as an input to GPT-3, we need to combine everything we mentioned in the previous section — the task description, demonstrations and a post description to get results on.
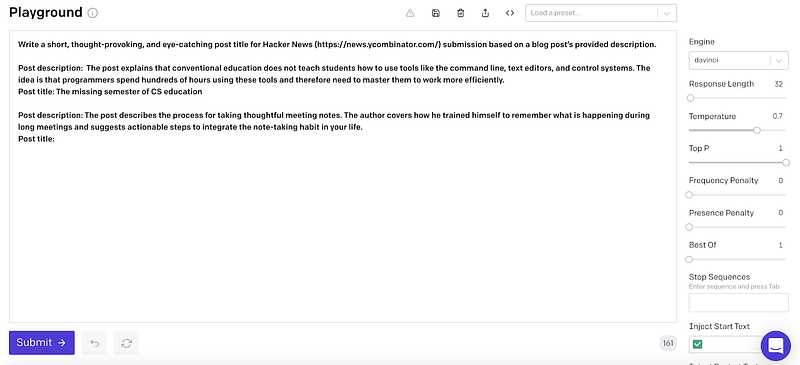
The figure below shows the prompt for GPT-3 with all three demonstrations. Since GPT-Neo does not have a user interface yet (as of April 2021), we fed the same prompt into the model as a string.

There is a “post title:” at the end, where we expect the GPT-3 model to generate the title. This prompt is the same as Vasili’s prompt.
We were also interested to see how GPT-3 and GPT-Neo perform with fewer samples. In the prompt below, we only used the third demonstration.
Comparing GPT-Neo with GPT-3 Qualitatively
We used GPT-3 ada and GPT-3 davinci to compare with GPT-Neo. Let’s look at some results using GPT-Neo vs. GPT-3.
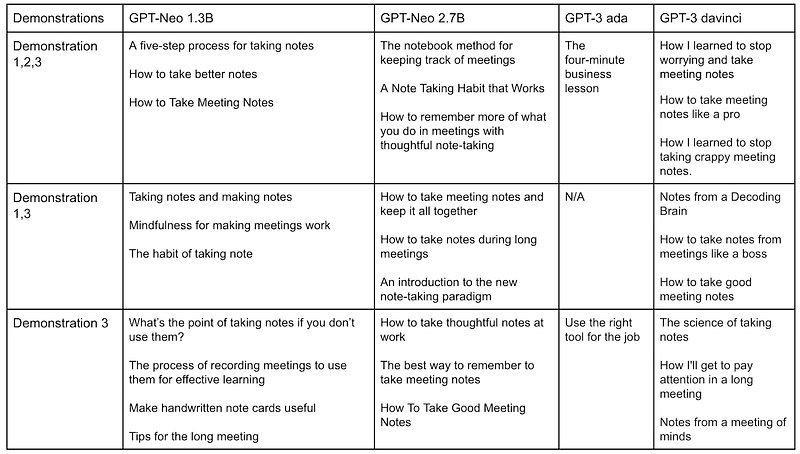
Observation 1: GPT-3 ada did not generate proper titles.
Out of many attempts, GPT-3 ada only generated two titles that could potentially be the title, depending on the actual blog post. Other models generated titles related to note-taking, but GPT-3 ada didn’t. This suggests that GPT-3 ada did not pay much attention to the provided target description.
GPT-3 ada also generated titles like “The four-minute business lesson” and “Use the right tool for the job.” These might be good titles, but not based on the description provided.
Observation 2: GPT-Neo 1.3B is not far behind GPT-Neo 2.7B.
We expected the larger GPT-Neo model would significantly outperform the smaller one, as this is true for GPT-3. In our results, though, both GPT-Neo 1.3B and 2.7B generated decent titles, and it’s hard to say if one model beats the other.
Observation 3: GPT-3 davinci and GPT-Neo 2.7B did not follow the pattern.
GPT-3 davinci and GPT-Neo 2.7B did the job by generating proper titles like “How to …” or “How I …”. Note that only the second demonstration post title starts with “How to,” yet both models still generated “How to …” without the second demonstration. Therefore, we see GPT-3 davinci and GPT-Neo 2.7B did not simply follow the demonstration patterns.
Observation 4: GPT-Neo and GPT-3 davinci are very creative sometimes.
GPT-Neo 1.3B, 2.7B, and GPT-3 davinci generated some mind-blowing titles:
- “Mindfulness for making meetings work” by GPT-Neo 1.3B
- “A Note Taking Habit that Works” by GPT-Neo 2.7B
- “How I’ll get to pay attention in a long meeting” by GPT-3 davinci
These are all creative, eye-catching titles! We would consider using these titles if this was our blog post.
When GPT-Neo and GPT-3 Fail…
GPT-Neo and GPT-3 can be hit or miss. We didn’t get beautiful titles every time. Let’s look at some not-so-successful generations.
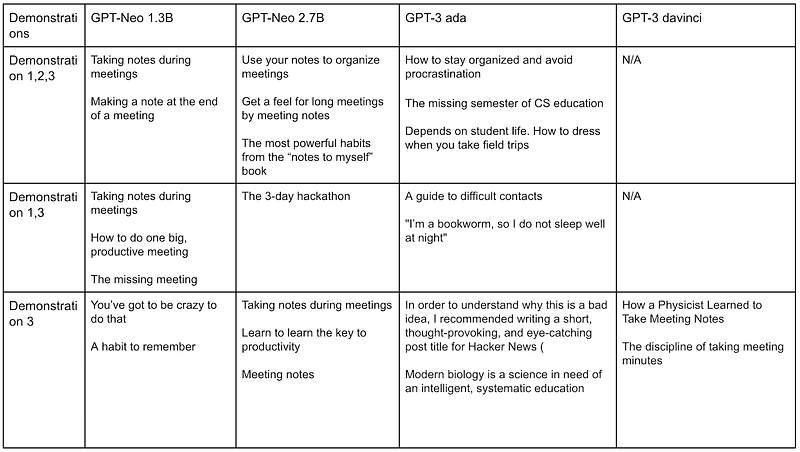
Observation 1: GPT-3 davinci started to generate inadequate titles in the one-shot setting.
When giving two or three demonstrations, GPT-3 davinci generates good titles. With only one demonstration, GPT-3 davinci started to generate some titles that do not relate to the description. It’s worth mentioning that GPT-3 davinci did still produce some good headlines in this setting — we’re showing some of the not-so-successful titles here.
Observation 2: Random generations.
GPT-Neo 1.3B, 2.7B and GPT-3 ada all generated some completely random titles, like “The 3-day hackathon”. These random titles do not relate to the demonstrations or the target post description.
Observation 3: GPT-3 ada memorized in certain runs.
When giving all three demonstrations, GPT-3 ada generated “The missing semester of CS education,” which is the same as the second post title in the samples. When only given the third demonstration, GPT-3 ada generated “… writing a short, thought-provoking, and eye-catching post title for Hacker News” — which comes from the task description.
Observation 4: GPT-Neo models generated “note-taking” related titles, but those are not good titles.
GPT-Neo 1.3B generated “Taking notes during meetings” and GPT-Neo 2.7B generated “Use your notes to organize meetings.” These titles do relate to note-taking, but they’re not good titles based on the description given. It seems that GPT-Neo used the keyword in the provided description, but failed to parse the high-level idea in the description and generate a proper title in these runs. Interestingly, GPT-3 models did not produce this behavior.
Some General Observations
In this section, we discuss some observations when we used the two models to generate titles.
Both GPT-Neo and GPT-3 kept generating after generating the title
We manually selected the title from the model’s output when collecting results in the tables above, taking the text after “post title:” until there was a new line. In some runs, the model only generated the title, but sometimes it generated more. You can see an example below where GPT-Neo kept generating text after the title.

And here’s an example where GPT-3 kept generating text after the title.
GPT-Neo generated a complete description-title pair after finishing the job
GPT-Neo generated a complete description-title pair after generating the “note-taking” title in some runs. The two figures below are some examples. The newly produced description title makes sense. GPT-Neo understood the pattern in the demonstrations and did some extra work 😂.


Conclusion
We compared GPT-Neo with GPT-3 on a language generation task. We would say that GPT-Neo outperformed GPT-3 ada in this task. Although GPT-3 davinci failed less often than GPT-Neo, GPT-Neo generated some promising titles. We understand that our evaluation is very subjective. People generally use the perplexity score as an intrinsic metric to evaluate NLG tasks. If you are interested in knowing the perplexity score of GPT-Neo on some benchmarks, check out EleutherAI’s GPT-Neo repository.
Task 2: GPT-Neo vs. GPT-3 Sentiment Classification
In this section, we evaluate GPT-Neo and GPT-3 quantitatively on a sentiment classification task, using the Stanford Sentiment Treebank (SST) dataset.
The Stanford sentiment treebank dataset [Socher et al. 2013] contains movie reviews and the review sentiment. This dataset has two versions: SST-2 and SST-5. In SST-2, the labels are either positive or negative. In SST-5, there are five possible sentiments: negative, somewhat negative, neutral, positive, or somewhat positive. We will use SST-2 to test GPT-Neo and GPT-3. Let’s take a look at some positive reviews from SST-2.

The first two reviews are clearly positive. The third one is a little tricky. We would generally consider it a neutral review, and it’s classified as positive in this dataset.
Let’s take a look at some negative reviews from SST-2.

Here we can see that the first and second reviews are unquestionably negative. There are some examples in SST-2 that look like incomplete sentences (like the third review), and there are some brief samples with no real sentiment (like the fourth review).
Performance of GPT-Neo and GPT-3 on Sentiment Classification
We asked GPT-Neo and GPT-3 to classify the sentiment from reviews in the test set of SST-2, consisting of 1821 reviews.
What Is the Prompt?
Here is the prompt in the zero-shot setting:
Review: no movement, no yuks, not much of anything
Sentiment:
In the zero-shot setting, we provide one review and ask the model to output a sentiment.
Here is the prompt in the one-shot setting:
Review: reign of fire is hardly the most original fantasy film ever made — beyond road warrior, it owes enormous debts to aliens and every previous dragon drama — but that barely makes it any less entertaining
Sentiment: Positive
Review: no movement, no yuks, not much of anything
Sentiment:
In the one-shot setting, we provide one sample (one set of review and sentiment), then append the target review, (the review we want the model to classify). As you can imagine, in few-shot settings, we provide multiple demonstrations.
You might wonder how we selected demonstrations for the prompt. We randomly chose samples from the training set of SST-2. The example above is a challenging one because the example is a positive review, and the sentiment of the target review should be negative. This one-shot setup means that the model can’t simply repeat the pattern in demonstration and has to figure out the right sentiment, given a review.
As we saw above, there are a few sparse reviews in the dataset, which also cause difficulties if they are used. Since the randomness in demonstrations influences the task’s complexity, we run each model with five different seeds, except for GPT-3 davinci, since it’s pretty expensive 😝.
How Did We Run Experiments and Measure the Accuracy?
Since the task is about classifying a movie review’s sentiment, higher accuracy indicates better performance. To measure the accuracy, we take every sample from the test set of SST-2 and form the prompt using the approach we described in the section above. We then feed the prompt into the model and examine the output. The model is correct if the first generated word is the right sentiment of the testing review. The model is incorrect if it spits out the wrong sentiment or any other word. We get the accuracy by dividing the number of correct predictions by the total number of reviews in the test set.
Experiment Results
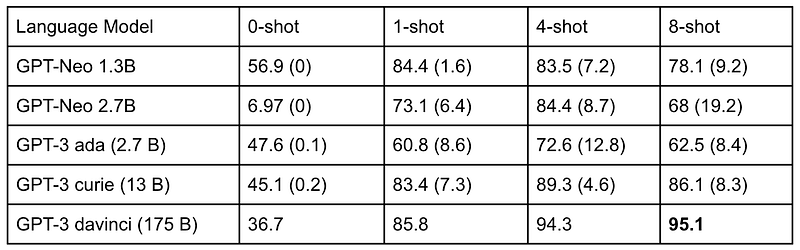
Observation 1: The zero-shot setting is challenging for both GPT-Neo and GPT-3.
In the zero-shot setting, we did not put any demonstrations in the prompt and asked the model to output a sentiment given only the test review. Our results show that all models, except GPT-Neo 1.3B, perform worse than predicting randomly. GPT-Neo 2.7B’s performance is particularly poor. This setting is very challenging because we didn’t describe the prompt’s task, so the model only saw a review and didn’t know what we wanted it to do. There weren’t any samples either, so the model can’t learn to pattern-match.
Observation 2: Seed influences a model’s accuracies.
As discussed above, we randomly selected reviews from the training set and put them into the demonstration. Therefore, we ran each model with five different seeds and reported the average accuracy and the standard deviation in brackets. The standard deviation could be pretty significant, suggesting that the randomness in demonstrations does influence the model’s performance. Let’s look at a concrete example. In the 8-shot setting, GPT-Neo 2.7B has 91% accuracy when the seed is 0. Its accuracy becomes 50.4% when the seed is 1.
Observation 3: Both GPT-Neo and GPT-3 perform better when there are more demonstrations.
We observed that all models perform better when we increase the number of reviews in the demonstration from 0 to 4. Only GPT-3 davinci’s performance still improves when there are eight reviews in the prompt, showing that having more samples does not necessarily help the model predict better.
Observation 4: GPT-Neo 1.3B outperforms GPT-3 ada.
We expected GPT-3 ada to outperform GPT-Neo 1.3B, as GPT-3 ada is twice the size of GPT-Neo 1.3B. Our results show that GPT-Neo 1.3B consistently outperforms GPT-3 ada in all the zero-shot and few-shot settings.
Observation 5: GPT-Neo 1.3B outperforms GPT-Neo 2.7B in nearly all settings.
GPT-Neo 2.7B is twice the size of GPT-Neo 1.3B, but GPT-Neo 1.3B outperforms GPT-Neo 2.7B in nearly all settings, except for the 4-shot case. We think that this might indicate that GPT-Neo 1.3B is better trained than GPT-Neo 2.7B.
Observation 6: GPT-3 davinci has the best performance in few-shot settings.
GPT-3 davinci is the largest model in the GPT-3 family, so it’s not surprising that it outperforms other models in few-shot settings. Interestingly, GPT-3 davinci does not have the best performance in the zero-shot situation, but given that there is no prompt provided to describe the task, we should not hold this against it.
Costs of GPT-Neo and GPT-3
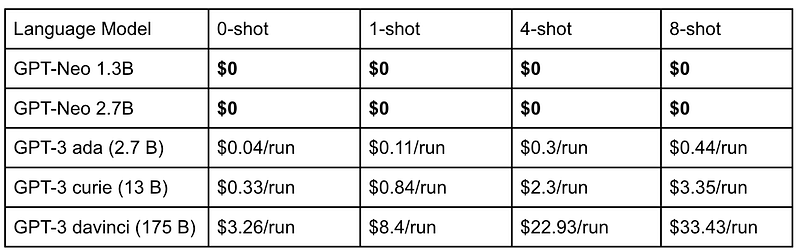
We list the costs of using GPT-Neo and GPT-3 models in the table above. The runs here refer to one complete cycle through the entire test set; when using five seeds, you can multiply the cost by five.
Observation 1: GPT-Neo is free!
Since GPT-Neo is an open source model, using the model does not cost anything. Obviously, there will be costs if you use GPT-Neo on some cloud platforms. The table above only shows the costs of using the models.
Observation 2: GPT-3 davinci is so expensive!
GPT-3 davinci is the most expensive model in the GPT-3 family. Using GPT-3 davinci to predict sentiments of 1821 reviews in an 8-shot setting costs 33.43 dollars!
Running GPT-Neo on a GPU
You might want to run GPT-Neo models on a GPU for a faster inference speed. In our experiments, GPT-Neo 1.3B and 2.7B work on the NVIDIA Tesla V100 GPU in 0-shot, 1-shot and 4-shot settings (using the p3.2xlarge AWS EC2 instance). The 8-shot setup requires much more memory, and we used a larger AWS CPU-only EC2 instance (c5.18xlarge, containing 72 vCPUs and 144 GiB of memory) for that task.
What are the best results on SST-2?
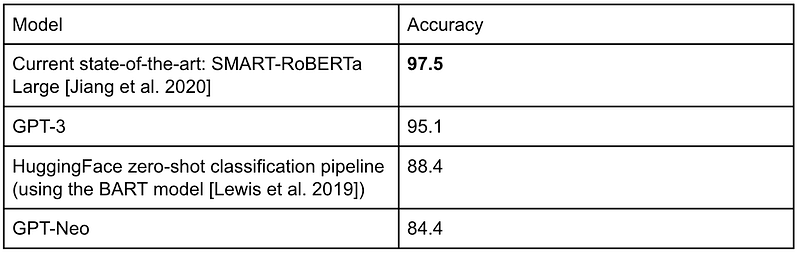
How does GPT-Neo and GPT-3 compare to other models on SST-2? Paperswithcode shows that the reigning champion 👑 on SST-2 (as of April 2021) is SMART-RoBERTa Large [Jiang et al. 2020]. We tested SST-2 using Huggingface’s zero-shot classification pipeline. The underlying model of the pipeline is BART [Lewis et al. 2019]. The pipeline uses zero-shot learning, so a 88.4% accuracy is pretty good 🤗. We showed the best results of GPT-3 and GPT-Neo from the previous section, and they also have comparable performance.
General Conclusion
We compared GPT-Neo with GPT-3 on title generation and sentiment classification tasks. Our results suggest that GPT-Neo outperformed GPT-3 ada, the similarly sized GPT-3 model. GPT-Neo generated some excellent titles and is not very far behind GPT-3 davinci. You should certainly consider using it as a replacement for your language generation tasks. On sentiment classification, GPT-3 davinci outperformed GPT-Neo, but GPT-3 davinci is quite expensive. Lastly, but most importantly, GPT-Neo is open-sourced, so it’s possible to domain-adapt GPT-Neo and fine-tune it for your needs! 🙌
[Bonus] Task: Generate a Title for This Blog Post!
As you would expect, we generated the title for this blog using Vasili’s method described in the first task. Below are some alternate titles produced by GPT-Neo and GPT-3 (half each from these models). Can you guess which ones are generated by GPT-Neo and which ones are generated by GPT-3 😂?
- NLP: GPT-Neo vs. GPT-3 — results & insights
- How does GPT-neo compare to GPT-3?
- GPT-neo: Is it worth it to pay for GPT-3?
- GPT-3 vs. GPT-neo
- NEO vs GPT-3: does free-as-in-beer beat paid-as-in-candy?
- The GPT-3 vs. GPT-neo Model Showdown
- The Open Source GPT-3: Open Source and the Future of NLU?
- GPT-3 versus open-sourced GPT-3
- GPT-neo vs GPT-3: are commercialized NLP models really that much better?
- Is Open Source Too Cheap? (GPT-3 vs. GPT-neo)
- The GPT-neo model is as good as GPT-3 and will save you from the headache.
- Which GPT model to use for NLP?
- The open-sourced GPT-neo model
About Georgian R&D
Georgian is a fintech that invests in high-growth software companies.
At Georgian, the R&D team works on building our platform that identifies and accelerates the best growth-stage software companies.
As part of this work, the Georgian R&D team conducts research to help understand and de-risk emerging technologies that can be adoped by our companies to help solve business challenges. Where it makes sense, we build open-source toolkits to make these technologies available to our companies.
Take a look at our open opportunities if you’re interested in a career at Georgian.
References
[Socher et al. 2013] Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C. D., Ng, A., and Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In EMNLP, 2013. Link to paper: https://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf. Link to dataset: https://nlp.stanford.edu/sentiment/
[Brown et al. 2020] Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert-Voss and Gretchen Krueger and Tom Henighan and Rewon Child and Aditya Ramesh and Daniel M. Ziegler and Jeffrey Wu and Clemens Winter and Christopher Hesse and Mark Chen and Eric Sigler and Mateusz Litwin and Scott Gray and Benjamin Chess and Jack Clark and Christopher Berner and Sam McCandlish and Alec Radford and Ilya Sutskever and Dario Amodei. Language Models are Few-Shot Learners. https://arxiv.org/abs/2005.14165
[Lewis et al. 2019] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. https://arxiv.org/abs/1910.13461
[Jiang et al. 2020] Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, Tuo Zhao. ACL 2020. https://arxiv.org/pdf/1911.03437v4.pdf




