
GPT-4: How OpenAI Built an AI Model 10x Larger Than GPT-3

In March 2023, OpenAI unveiled their latest breakthrough in natural language processing: the GPT-4 model.
Now, let’s find out how.

By now, all of us have not only heard about it, but we’ve used it frequently.
GPT-4 represents a monumental achievement, with OpenAI succeeding in developing an AI system over 10x larger than its predecessor GPT-3.
Most of the details were hidden or only whispers at Silicon Valley parties before George Hotz started discussing those secrets on podcasts.

So how exactly did OpenAI manage to create something 10x larger than their previous achievement with GPT-3?
What techniques and resources did they leverage to train and deploy this gigantic model?
I’ve summarized all of the known details and matched it up with our internal research at Klu.
I’ll dive into the key innovations and milestones behind GPT-4, demystifying how OpenAI engineered such an enormous leap in scale and capability.
Let’s dig in…
GPT-4 Model
Clocking in at a staggering 1.8 trillion parameters, GPT-4 required truly pushing the boundaries of existing deep learning capabilities. This model did not come easy — it represents years of focused research, infrastructure development, and computational power.
More technical details organized as a model card published on the Klu Generative AI insights blog.
One of OpenAI’s main goals with GPT-4 was to create a model over 10x larger than GPT-3, the previous state-of-the-art LLM.
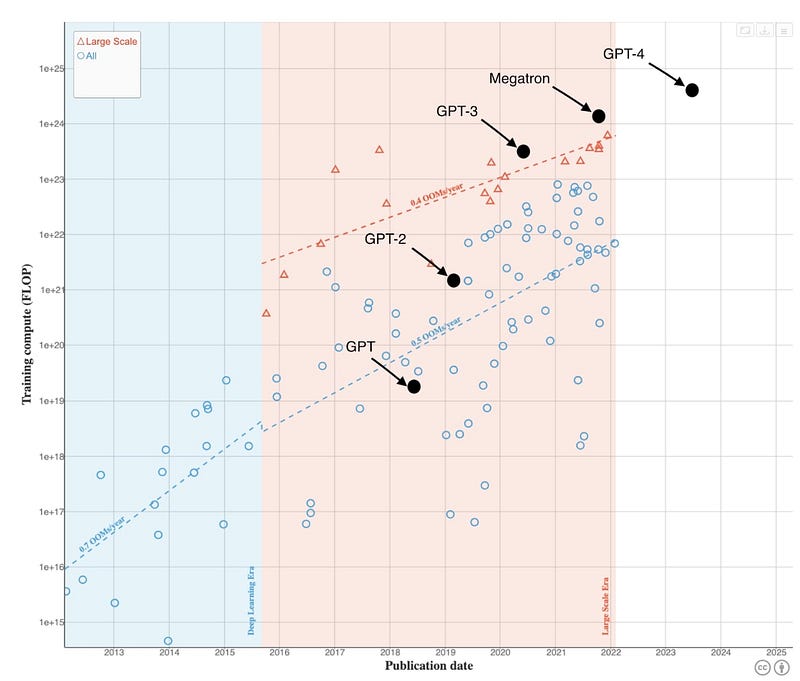
They succeeded in this by developing a model with around 1.8 trillion parameters — more than an order of magnitude greater than GPT-3’s 175 billion parameters.
To handle inference at this scale, GPT-4 utilizes a mixture-of-experts (MoE) architecture with 16 separate expert models. This allows the overall gigantic model to be split into specialized parts that are only activated as needed per query.
Training Process
Training a model as large as GPT-4 required pushing the limits of existing infrastructure.
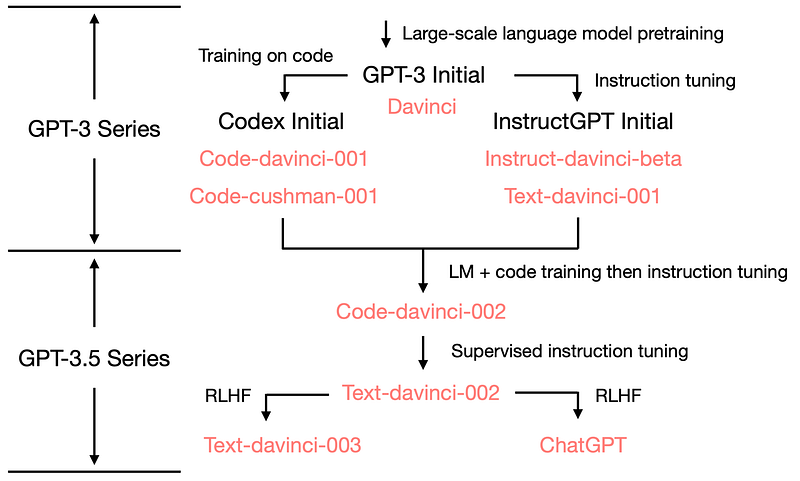
You can read more about the evolution from GPT-2 to 4 here.
Some key facts about how this enormous model was trained:
- Used 25,000 Nvidia A100 GPUs simultaneously
- Trained continuously for 90–100 days
- Total compute required was 2.15e25 floating point operations
- Processed a training dataset of 13 trillion tokens
- Implemented advanced parallelism techniques to distribute the model across GPUs
This represents one of the largest computations ever performed for an AI system.
Inference Capabilities
Deploying GPT-4 for practical inference at scale was a monumental effort. Even with the MoE architecture, running a 1.8 trillion parameter model efficiently is highly challenging.

If renting from AWS, one GPT-4 cluster is roughly $512k monthly cloud spend across 16 P4DE instances.
For inference, GPT-4:
- Runs on clusters of 128 A100 GPUs
- Leverages multiple forms of parallelism to distribute processing
- Carefully optimizes for throughput, latency and utilization
- Can process up to 32,000 tokens of context— a significant increase over GPT-3
Model Performance
While detailed metrics are still emerging, initial results show GPT-4 achieving state-of-the-art performance across a variety of NLP tasks.
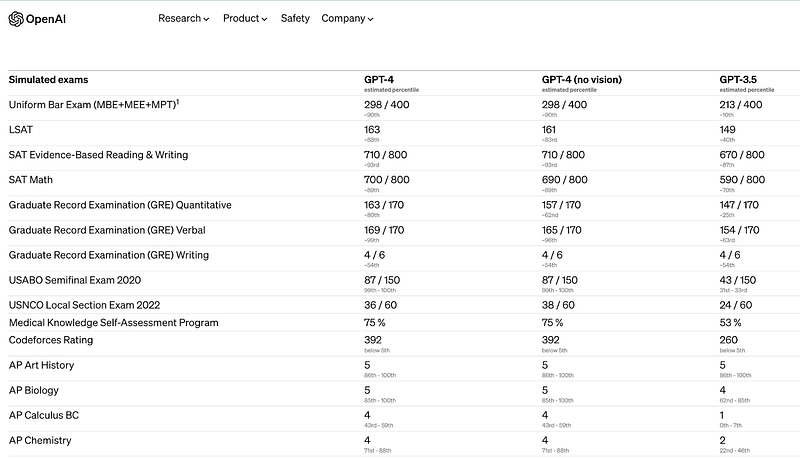
- 10x-100x more capable than GPT-3 on common benchmarks
- Strong improvements in areas like translation, question answering, and text classification
- Multilingual capabilities spanning 26 languages tested so far
- Still gaps in areas like reasoning and factual accuracy
Limitations and Concerns
Despite its impressive capabilities, GPT-4 has some key limitations and areas of concern:
- Potential for biased and harmful outputs— requires caution and monitoring
- Lack of grounded reasoning — can make logical errors or generate falsehoods
- Non-determinism in outputs due to technical factors
- Risks around misuse of the model’s capabilities
Careful oversight is required when utilizing models like GPT-4 to avoid unintended consequences.
Future Directions
While GPT-4 demonstrates huge progress in LLMs, there are still frontiers to push forward in areas like:
- Multimodal modeling— combining text, images, audio, video — the rumors propose that the current Nvidia H100 shortage is the reason for delays in the GPT-4 vision model rollout
- Architectures for extreme scale — beyond mixtures of experts
- Task-focused optimizations — adapting models for real-world goals – likely best done via GPT-4 fine-tuning
- Expanding training data diversity and size massively
The future capabilities enabled by models like GPT-4 remain incredibly exciting. With each iteration, we move closer to artificial general intelligence, even if current LLMs still lack general reasoning.
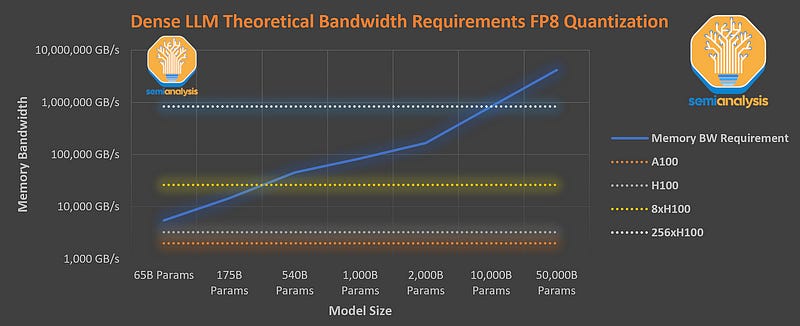
The details emerging show OpenAI is rapidly mastering the techniques needed to make huge leaps with each model generation.
GPT-4 proves they can build LLMs over 10x more capable than the previous state-of-the-art. The future will likely bring models orders of magnitude more advanced as compute scales continue doubling year over year.
Getting started with AI? Book an AI Strategy session with Stephen…





