
Google’s Gemini 1.5 Finds Needles in Haystacks
Gemini Pro 1.5 has arrived. 10M token context window (1M in production for now), comparable evals (so far) to Ultra 1.0, and considerably more compute efficient — shorter response times.
It uses the Mixture-of-Experts architecture. to improve efficiency.
This model will be available in Google AI Studio and supports use cases like:
- Upload multiple large files (<= 1 million tokens) and ask questions
- - Query an entire code repository <= 300K LOC
- - Add a full-length video <= 10 hours long
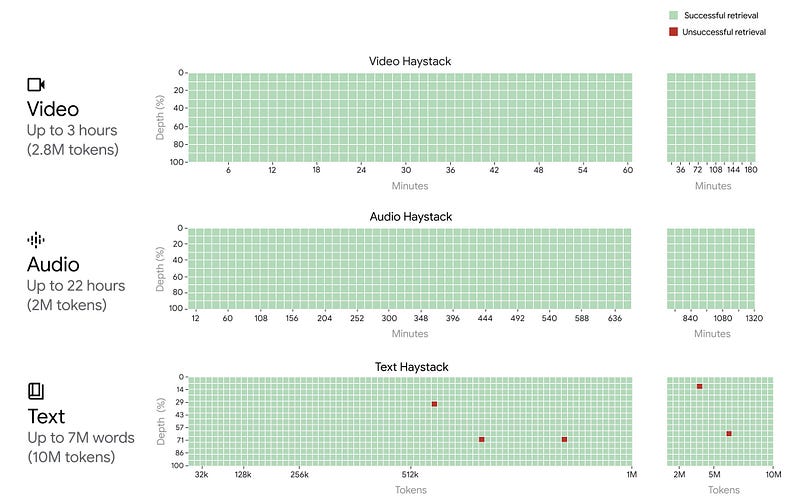
From the Gemini 1.5 Paper.
The model achieves near-perfect “needle” recall (>99.7%). This is big.
LLMs often misremember and hallucinate even with a sophisticated #RAG chain.
The more they have to remember [the larger the prompt chain’s context for example], the more they forget.
Hiding a chunk of text like. “the pass code is 135790" in a an average size prompt [1000 tokens] and after asking the model for the pass code you’ll get the right answer.
But that same line buried in a 10,000-word prompt will confuse the model and it very likely will make stuff up.
Solving this is critical to long term adoption of genAI, specifically an #LLM.
If it can’t remember a small but important detail of a long financial report or the PSA level on a blood test the next gen LLMs will continue to occupy low value niches.
Gemini 1.5 finds the pass code, 99.7% of the time in a prompt of 10 million tokens — equivalent to. remembering after being fed 70 books worth of information.
This could be a. game changer — waiting to hear from Google on inference costs and a pricing model.
#Gemini #Google
“





