Google’s DreamFusion is a Text-to-3D Model that will Challenge Your Imagination
A clever use of diffusion models to generage 3D objects.
I recently started an AI-focused educational newsletter, that already has over 150,000 subscribers. TheSequence is a no-BS (meaning no hype, no news etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:
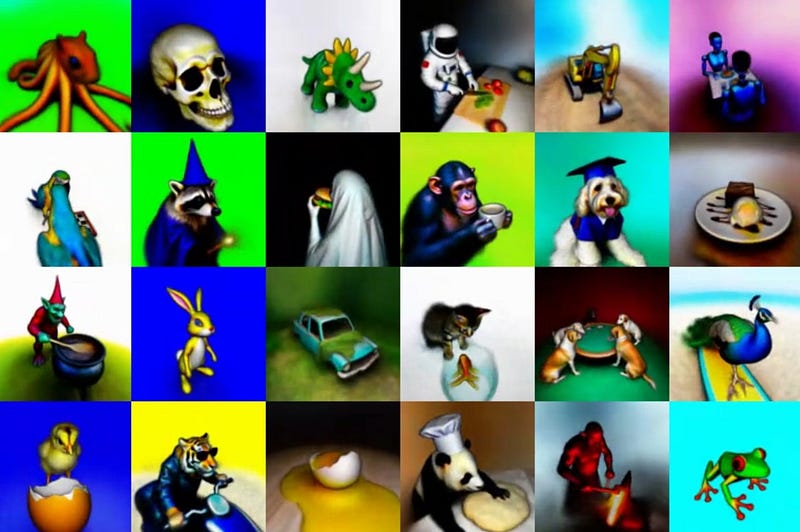
Generative AI has been enjoying an impressive renaissance fundamentally triggered by the emergence of diffusion architectures. DALL-E 2, Midjourney, Stable Diffusion, Imagen are some of the diffusion-based models that are reaching impressive milestones in areas such as text-to-image or text-to-video. Text-to-3D is often mentioned as one of the next frontier for diffusion techniques but the path is not so trivial. Recently, Google unveiled DreamFusion, a diffusion based neural network that is able to generate realistic 3D representations from text inputs.
Diffusion architectures allow these models to be pretrained on monumentally large volumes of unlabeled text and image collections. Extrapolating that approach to 3D is far from an easy endeavor as there aren’t many large datasets of 3D data. Also, the whole diffusion model is based on denoising and reconstructing images but can you imagine the complexity of doing something like that for a 3D object?
Enter DreamFusion
With DreamFusion, Google circumvents some of the known limitations of diffusion models when applied to 3D data by using a pretrained 2D text-to-image model to perform 3D synthesis. More specifically, DreamFusion uses Google’s own Imagen as its text-to-image foundation. The architecture also includes a technique called Score Distillation Sampling (SDS) that can generate samples in a 3D parameter space by optimizing a loss function. Another component that DreamFusion relies heavily on is the neural radiance field(NeRF) which is a super complex technique that can generate 3D scenes from partial 2D images.
Putting all these components together, the DreamFusion algorithm works in the following steps:
1) A random NeRF field is initialized and trained for each caption.

2) The NeRF computes the density of the shade scene and the light directions. Shading is important as it reveals important details about the geometry of a 3D object.
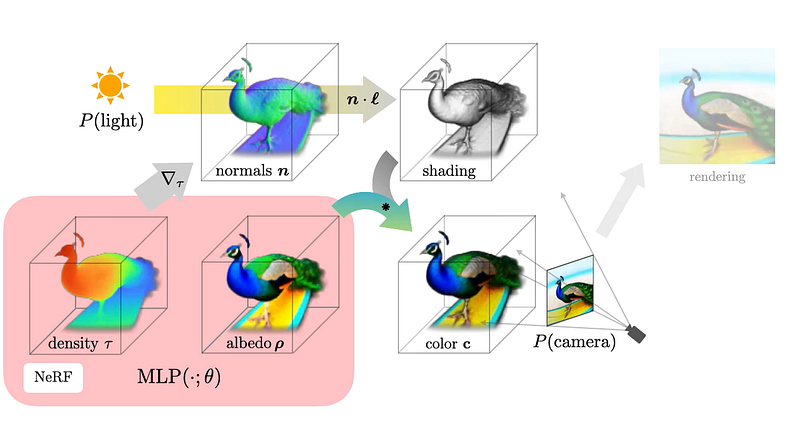
3) Uses Imagen to predict a denoised image and construct a better image.
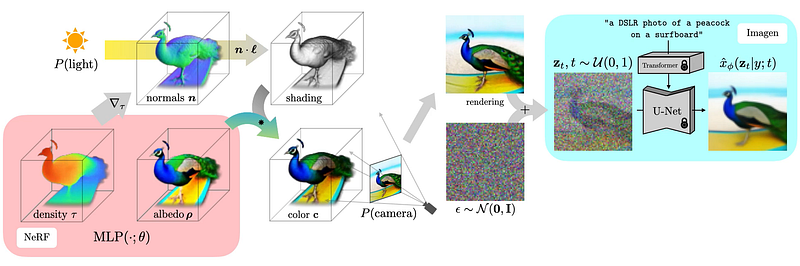
4) Backpropages an update to the NeRF weights and optimize.
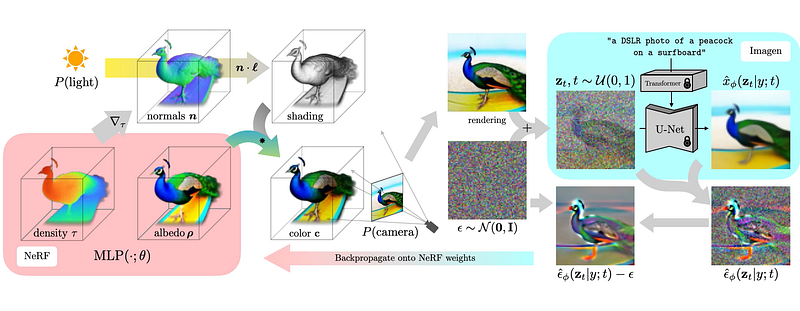
5) Repat until it converges.
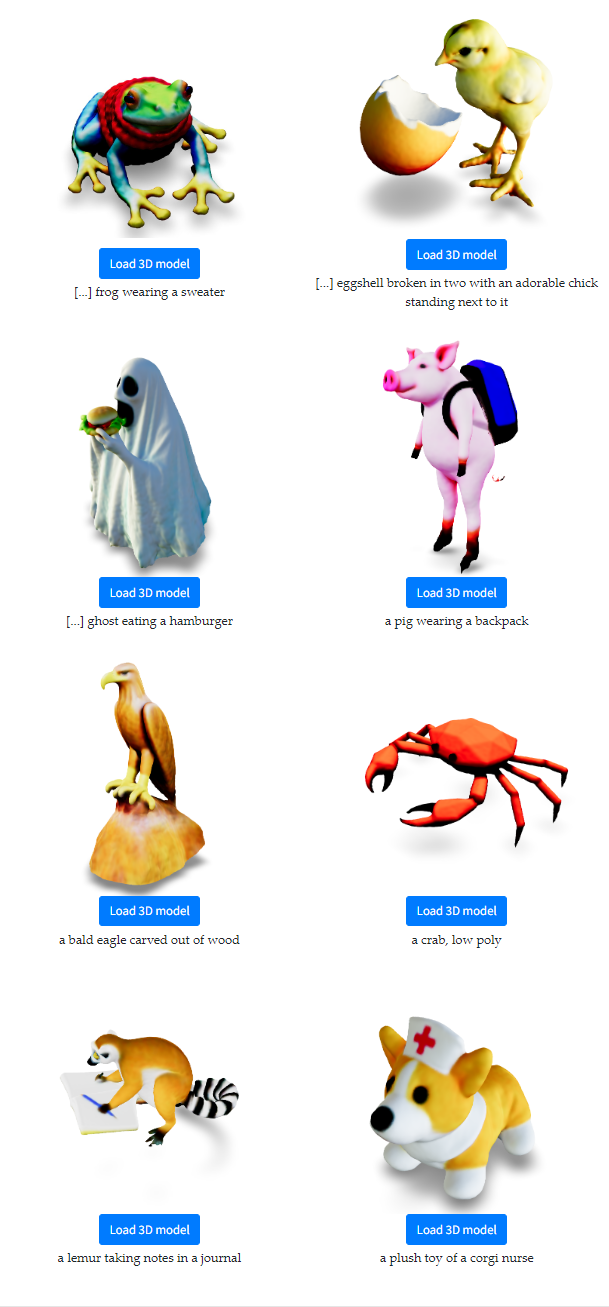
The results produced by DreamFusion are remarkable providing an interesting perspective of the possibilities of generative AI for the 3D space.