
| ARTIFICIAL INTELLIGENCE| MEDICINE| HEALTH|
Google Med-PaLM M: Towards the Medical AI Generalist
Google unveils a multi-modal model capable of incredible skills
Medicine is multimodal, and LLMs have only text as input. We have a possible multimodal LLM for a multimodal world, is this possible?
LLMs and medicine

Actually, it is a long love affair between medicine and artificial intelligence. Although for practical reasons and stringent regulations, it is difficult for AI applications to enter the clinic, there is intense research. Why? Because artificial intelligence could save so many lives,
Google has early on tried to adapt its PaLM model to the clinic, using special fine-tuning to make it more domino-friendly.
At the same time, the open-source community has also dedicated itself to the same goal. The first version of LLaMA was immediately to medicine. The model was fine-tuned on millions of abstracts.
On the other hand, one of the main problems of LLMs is to hallucinate, and interesting solutions were sought. For example, inserting additional knowledge. ClinicalGPT exploits an ingenious idea to give different inputs to the model, but it cannot be called strictly multimodal.
At present, most of today’s models are unimodal. For example, we have excellent ViTs that can be used with medical images, but these cannot incorporate relevant patient information from medical records. Such a model also outputs a predefined set of classes, cannot explain predictions, and cannot interact interactively with the clinician.
Google and other companies think foundation models can change the approach to medicine. These models are trained with huge amounts of data and can be quickly adapted to downstream tasks (even often without fine-tuning), and have generative and dialogic capabilities. A further advance would be the ability to integrate different modalities into complex structures that would allow the model to relate information and address new challenges. This is in the direction of a generalist biomedical AI system.
A generalist biomedical AI system can be defined as a model that manages to integrate all modalities and handle all the various downstream tasks at the same time, using the same set of weights for all of them.
This is an ambitious idea for several reasons:
- it lacks comprehensive multimodal medical benchmarks.
- An architecture to integrate the different modalities.
Multimodal Med-PaLM: boosting the AI physician

Google recently published a new study in which it presents the multimodal version of Med-PaLM:
The contributions of this work can be summarized:
- a new multimodal biomedical benchmark.
- Med-PaLM M, the first demonstration of a generalist biomedical artificial intelligence system.
- Evidence of new emerging capabilities in Med-PaLM M (such as zero-shot medical reasoning, generalization to new medical concepts and tasks, and positive transfer between tasks.
- In a blinded ranking of chest radiographs, physicians expressed a pairwise preference for Med-PaLM M reports over those produced by radiologists up to 40.50% of the time.
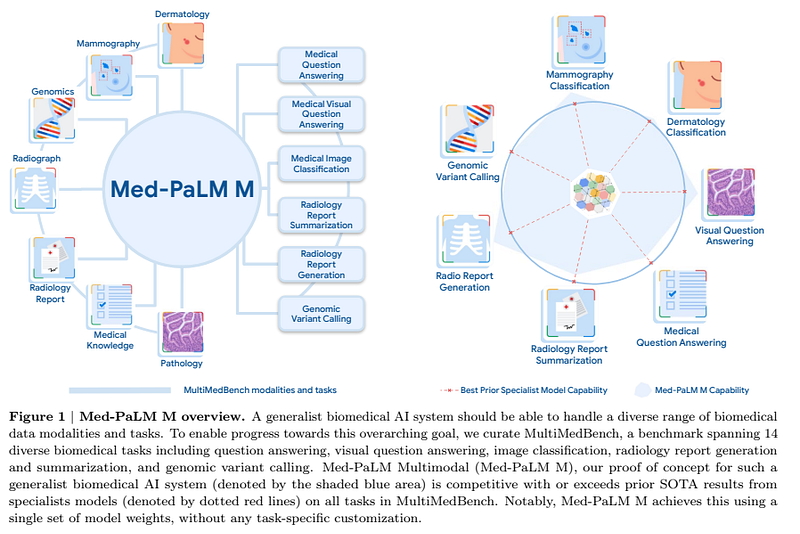
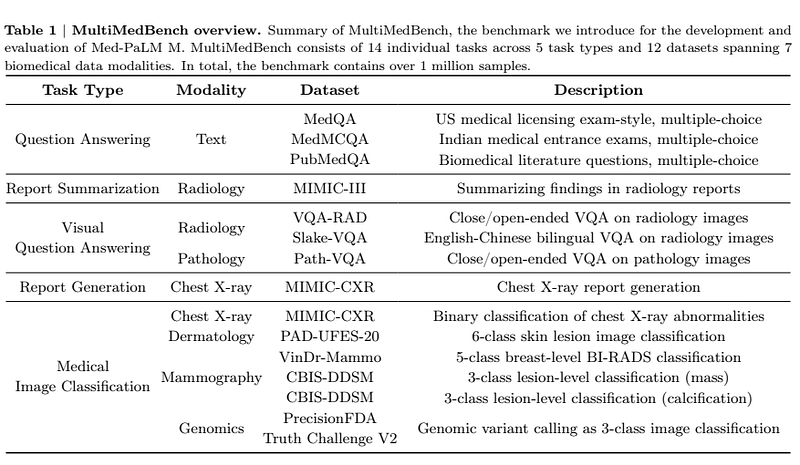
The dataset
The authors curated a dataset for biomedical AI; the dataset includes 12 open-source datasets and 14 tasks. This dataset is used to measure a model’s ability to perform a variety of clinically-relevant tasks. The dataset includes data from genomics, pathology, radiology, medical question, and others.
- Task type: question answering, report generation and summarization, visual question answering, medical image classification, and genomic variant calling.
- Modality: text, radiology (CT, MRI, and X-ray), pathology, dermatology, mammography, and genomics.
- Output format: open-ended generation for all tasks including classification.
The model
The authors used the Pathways Language Model (PaLM). It is a wide decoder-only Transformer (there are three versions: 8, 62, and 540 billion parameters). The authors then used Vision Transformer (ViT) as an encoder.
The authors used PaLM-E (a multimodal language model which uses pre-trained PaLM and ViT) as the basis for Med-PaLM M. In other words, the authors reused models that had already been pre-trained and then conducted fine-tuning on MultiMedBench.
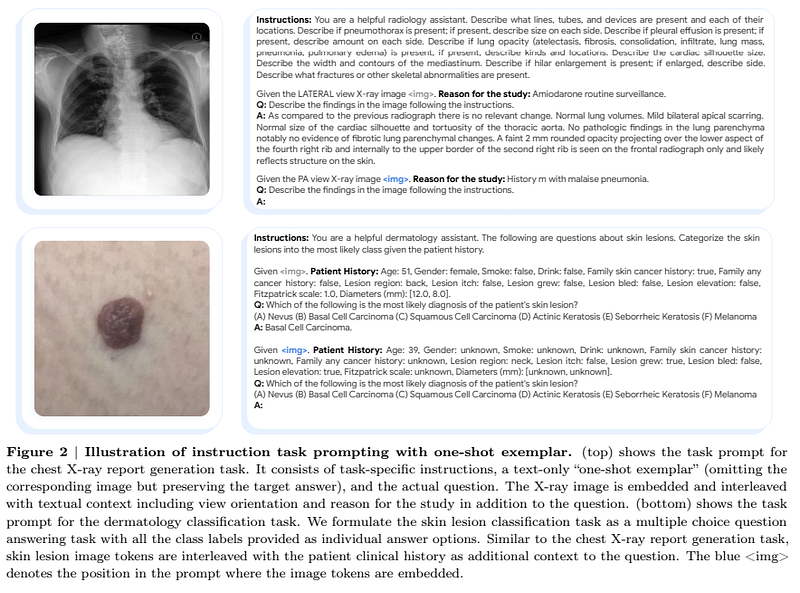
The authors trained the model with a mixture of distinct tasks simultaneously via instruction tuning, this was to create a model that performs multiple tasks on multimodal inputs (while still using only one model). The authors show an example of this training, in which they provide a medical image, context on the image, and instruction:
Evaluation
The authors evaluated the following cases:
- Evaluate generalist capabilities. evaluate the model on different biomedical tasks. Compared with the previous SOTA for each task.
- Explore novel emergent capabilities. Test whether using a single flexible model led to the emergence of new abilities in the biomedical field.
- Measure radiology report generation quality. They performed expert radiologist evaluations of AI-generated reports.
Results
Med-PaLM M reaches and exceeds previous SOTAs in 5 of the 12 tasks, although it is still competitive in the other tasks as well. The authors point out that these results are obtained using only one model with the same set of weights
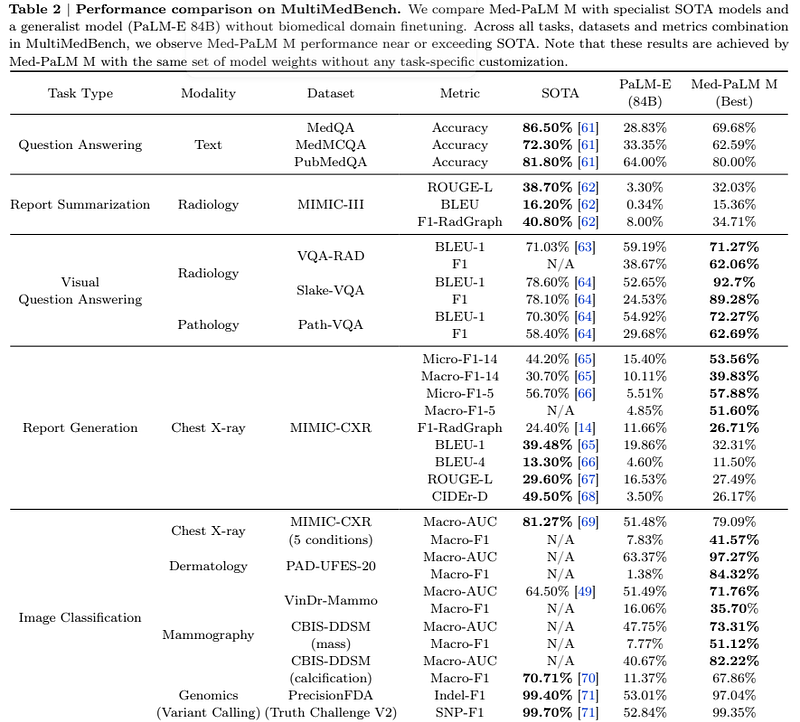
The authors point out other interesting points:
- Med-PaLM M outperformed the previous best PaLM results and the results themselves of Med-PaLM 2 (non-multimodal model). This demonstrates the importance of multimodality.
- The model is superior to PaLM-E, multimodal but not fine-tuned on medical topics. This result shows the importance of domain adaptation.
- For tasks that require language understanding and reasoning (such as question answering), the authors note that there is a proportional improvement with scaling. Also, for tasks such as mammography or dermatology image classification where the importance of language is less than visual understanding, the vision encoder dimensions are the bottleneck.
The authors show that the model is capable of zero-shot generalization, because even when trained on datasets that also contain X-rays the model is not specifically trained to recognize tuberculosis in the image
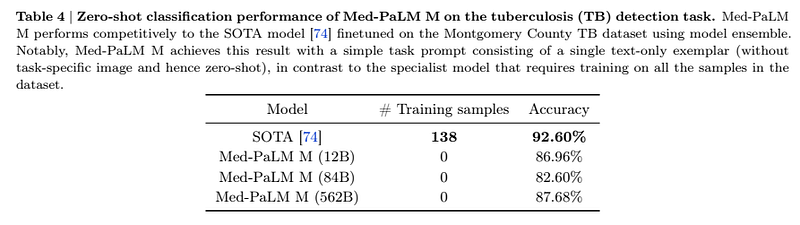
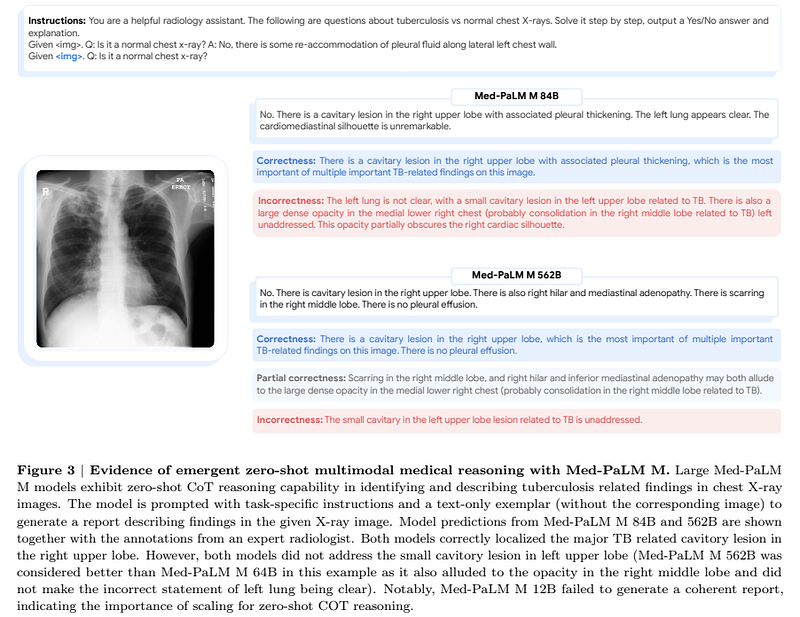
The model is also able to write a report and explain the reasoning (zero-shot chain-of-thought (CoT)), although there is room for improvement in this aspect:
However, according to expert radiologist review, there are still some omissions of findings and errors in the model generated report, suggesting room for improvement. (source)
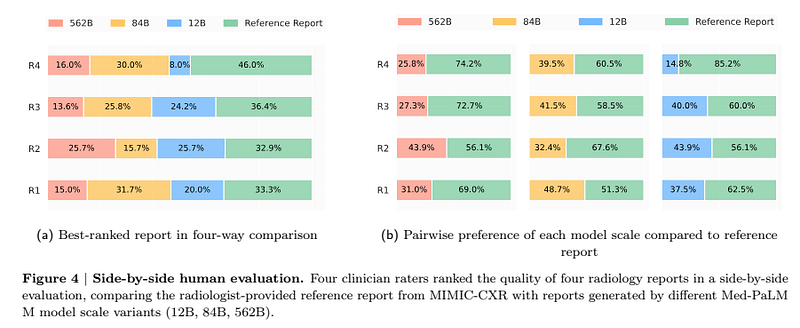
The authors then conducted a side-by-side evaluation with clinicians. In the study, four clinicians compared reports from radiologists and the model. The clinicians’ reports are preferred in most cases, but the larger model reports show better performance.
Conclusions
Google has presented a model capable of showing performance that is SOTA or otherwise competitive for 12 tasks, all thanks to a single model.
The model also shows emerging capabilities that are multimodal, showing the importance of using multiple modalities in medicine. They also show how domain adaptation is important.
Among the most interesting capabilities is report production for radiology. The authors note that the model also produces errors and cites articles that do not exist (AI artifacts) however, the quality is still impressive.
While human clinicians can train for “general practice”, helpful subspecialty-specific expertise is often found in different experts, to whom non-specialist clinicians may refer for specialist opinions in the course of care. It is also commonplace for multiple physician specialities to work together in care delivery. (source)
For Google in the future, physicians will work together with both generalist and specialist AI models. On the other hand, however, these models would have to be tested extensively before entering the clinic, and at present the model is not available for analysis.
What do guys think? Let me know in the comments
If you have found this interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, you can become a Medium member to access all its stories (affiliate links of the platform for which I get small revenues without cost to you) and you can also connect or reach me on LinkedIn.
Here is the link to my GitHub repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.
or you may be interested in one of my recent articles:
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
🔔 Follow us: Twitter | LinkedIn | Newsletter
🧠 AI Tools ⇒ Become an AI prompt engineer