
Good Token, Bad Token
Note : This is now a member-only story. However if you join the Stable Diffusion Training Discord Server, and ask me there (
@yushan.777), I will give you a Friends link to view with free access.
Note: This is now a member-only story. However if you join the [Stable Diffusion Training Discord Server](https://discord.com/invite/yJWSrsX4hW) (free to join), and ask me (@yushan.777) there, I will give you a Friends link to view with free access.
Your choice of a token word when training a Stable Diffusion model using Dreambooth could be a factor in how well it trains and how your trained subject will look.
Bad Token
A bad token or rather, a suboptimal token is one that already has a strong association to specific concepts within the model. This could be an object, a person, an animal, images of an event.
An obvious choice for a token would be a combination of first name + last name e.g. “anitabath” or “carrieoakey”, many do it and it can work. However, let’s say you happen to share the same name with a well-known celebrity and let’s say it’s Tom Cruise.
If you use the token “tomcruise”, it already has a strong association in the model. Eventually with enough training, you can overwrite the concept of Tom Cruise in the model, pull all the weights to your own subject and erase poor old Tom, but until you reach that point you will just end up a weird blend of your subject’s face and Tom’s.
Good Token
If a bad token is one that has strong association with a concept in the model, then a good token would be the opposite, one that would have no particular strong associations and would generate seemingly random images. You will never have a token that produces nothing.
Try To Avoid…
- Single letters, especially ones like “a” which is used a lot when forming sentences and therefore in prompts too :
“<a> photo of <a> man sitting on <a> chair in <a> cafe." - Common nouns and names
- Well known persons, either real or fictional
- Abbreviations of well-known brands or corporations.
- Random, long, convoluted words — if they are not found in the model’s dictionary then it will be broken up into smaller tokens, each of which may have a strong prior. From the Dreambooth Paper:
We generally find existing English words (e.g. “unique”, “special”) suboptimal since the model has to learn to disentangle them from their original meaning and to re-entangle them to reference our subject. This motivates the need for an identifier that has a weak prior in both the language model and the diffusion model.
A hazardous way of doing this is to select random characters in the English language and concatenate them to generate a rare identifier (e.g. “xxy5syt00”). In reality, the tokenizer might tokenize each letter separately, and the prior for the diffusion model is strong for these letters. We often find that these tokens incur the similar weaknesses as using common English words.
Let’s take that token example and extend it a bit further with a few more characters : “xxy5sytcar01230” You will see below that the token has been broken up into 11 tokens. No prizes for guessing which token is the most dominant one: “car”
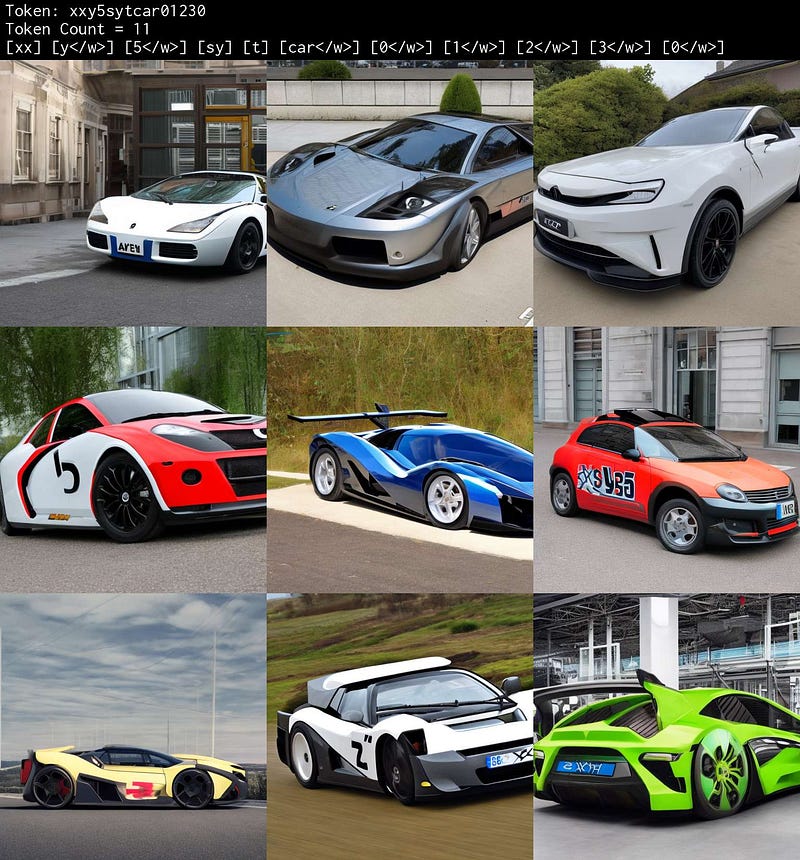
Examples
So let’s take a look at some example tokens.
In each example, there are 3 grids. The first will be the token in isolation, the 2nd will be the token word + the class word “person”, and the 3rd will be the token word + the class word “woman”.
Even if a token in isolation appears good (produces random results), when it is paired with a class word, it could take on a different meaning.
sks
Bad token. Rifles appear strongly especially with woman added, but less so with person.

The token sks has a bit of a history. It was first used in example code from the original textual inversion paper. DreamBooth that followed was a modification of the original textual inversion code and so remained. Many who followed the examples just assumed that was the token to use and it stuck.
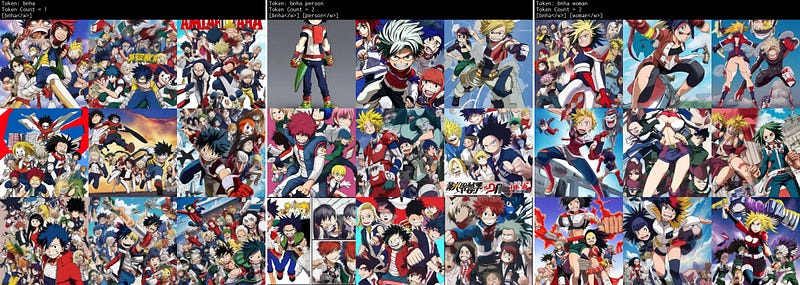
bnha
Bad token. Clearly associated with anime in terms of content and aesthetic across all three grids.
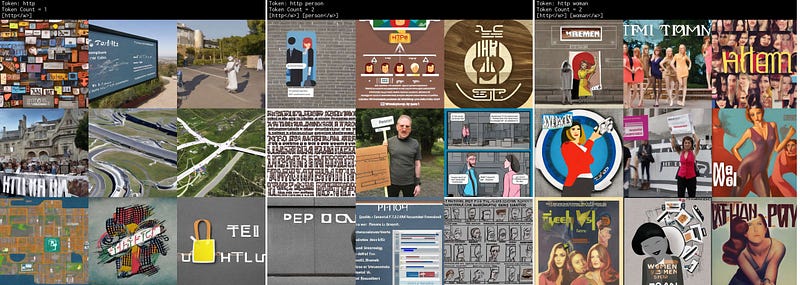
http
Good token. Seemingly random images, the persons and women do not share a look, race or aesthetic across the 3 grids.
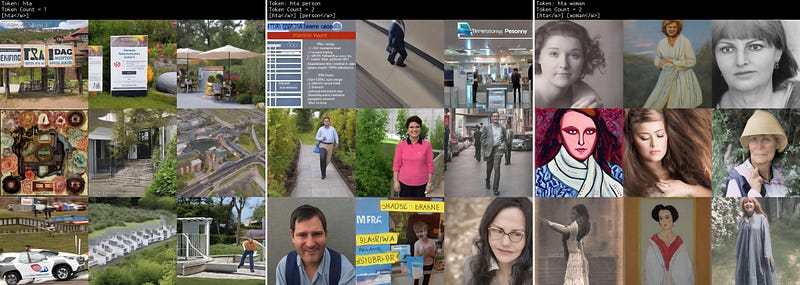
hta
Good token. Seemingly random images, the persons and women do not share a look, race or aesthetic across the 3 grids.
hmv
Bad token. Strong association with a media or music store and with the same content and aesthetic across the 3 grids.

httr
Bad Token. Strong association with an American Football team across all 3 grids.

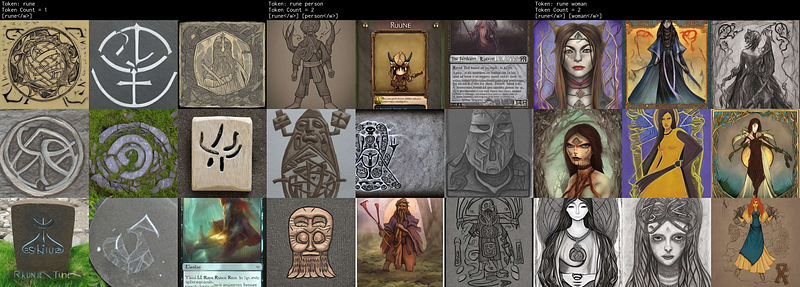
rune
Bad Token. Strong association with rune and stones, sword and sorcery imagery. I have actually trained with this token, and my subject occasionally had rune symbols on their forehead as well as their likeness not being quite right.
inem
Good-okay token. Seemingly random images, the persons and women do not share a look, race or aesthetic across the 3 grids. However there maybe a slight emphasis on black & white photos. Not enough samples to really say.

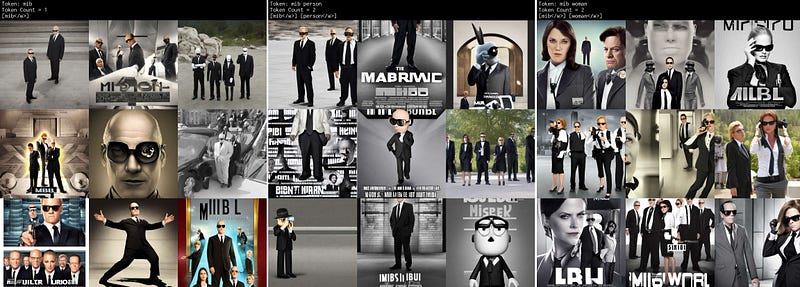
mib
Bad token. Men In Black.
oue
Good token. Slight emphasis on fashion magazine when woman is added (Was thinking probably due closeness to “vogue” — but not sure)

At the end of the day what you choose is entirely up to you. If it works for you then it’s all good. If you happen to be called Tom Cruise and don’t care about erasing the more famous one from the model, then by all means go for it.
The example images were generated using a Google Colab Notebook (Link shown below) that takes one or more tokens and generates a grid with that token as a prompt. It will also show a breakdown of your token into sub tokens. The model used was Stable Diffusion 1.5.
It is worth noting that the classic (and still considered best) Stable Diffusion 1.5 and 2.x share the same vocab.json dictionary. However, what the model will infer and generate will be different.

Links
sd-1–5-token-images.zip (a 600+ collection of images generated from tokens)
Stable Diffusion Dreambooth Token Checker Dreambooth Paper
If you have any questions or just want to learn more then join the Stable Diffusion Training Discord Server. There are a lot smart people there who can help you





