
Go: Understand the Design of Sync.Pool

ℹ️ This article is based on Go 1.12 and 1.13 and explains the evolution of sync/pool.go between those two versions.
The sync package provides a powerful pool of instances that can be re-used in order to reduce the pressure on the garbage collector. Before using the package, it is really important to benchmark your application before and after the usage of the pool since it could decrease your performance if you do not understand well how it works internally.
Limitation of the pool
Let’s take a basic example to see how it works in a pretty simple context with 1k allocations:
type Small struct {
a int
}
var pool = sync.Pool{
New: func() interface{} { return new(Small) },
}
//go:noinline
func inc(s *Small) { s.a++ }
func BenchmarkWithoutPool(b *testing.B) {
var s *Small
for i := 0; i < b.N; i++ {
for j := 0; j < 10000; j++ {
s = &Small{ a: 1, }
b.StopTimer(); inc(s); b.StartTimer()
}
}
}
func BenchmarkWithPool(b *testing.B) {
var s *Small
for i := 0; i < b.N; i++ {
for j := 0; j < 10000; j++ {
s = pool.Get().(*Small)
s.a = 1
b.StopTimer(); inc(s); b.StartTimer()
pool.Put(s)
}
}
}Here are two benchmarks, one without usage of sync.Pool and another one that takes advantage of it:
name time/op alloc/op allocs/op
WithoutPool-8 3.02ms ± 1% 160kB ± 0% 1.05kB ± 1%
WithPool-8 1.36ms ± 6% 1.05kB ± 0% 3.00 ± 0%Since the loop has 10k iterations, the benchmark that does not use the pool made 10k allocations on the heap vs only 3 for the benchmark with pool. The 3 allocations are made by the pool, but only one instance of the struct has been allocated. So far, so good; using the sync.Pool is much faster and consumes less memory.
But, in a real world, while you are using the pool, your application will do a lot of new allocations of the heap. In this case, when the memory will increase, it will trigger the garbage collector. We can also force the garbage collector in our benchmarks with the command runtime.GC()to simulate this behavior:
name time/op alloc/op allocs/op
WithoutPool-8 993ms ± 1% 249kB ± 2% 10.9k ± 0%
WithPool-8 1.03s ± 4% 10.6MB ± 0% 31.0k ± 0%We can see now that the performance is lower with the pool and the number of allocations and memory used are way higher. Let’s look deeper in the package to understand why.
Internal workflow
Digging into sync/pool.go will show us the initialization of the package that could answer our previous concern:
func init() {
runtime_registerPoolCleanup(poolCleanup)
}It registers to the runtime as a method to clean the pools. And this same method will be triggered by the garbage collector in its dedicated file runtime/mgc.go:
func gcStart(trigger gcTrigger) {
[...]
// clearpools before we start the GC
clearpools()That explains why the performance was lower when the garbage collector was called. The pools are cleared every time the garbage collector runs. The documentation warns us about that as well:
Any item stored in the Pool may be removed automatically at any time without notification
Now, let’s create the workflow in order to understand how items are managed:
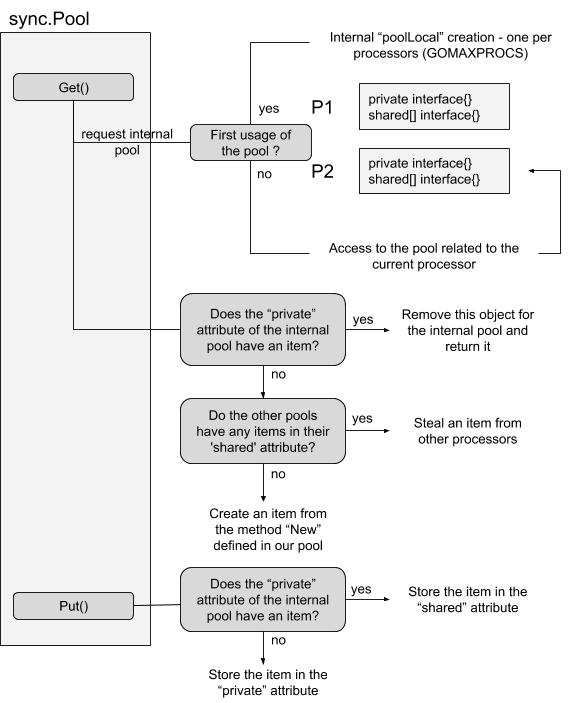
For each sync.Pool we create, go generates an internal pool poolLocal attached to each processor. This internal pool is composed by two attributes: private and shared. The first one is only accessible by its owner (push and pop — and therefore does not need any lock) while the shared attribute can be read by any other processor and needs to be concurrency-safe. Indeed, the pool is not a simple local cache, it has the possibility to be used by any thread / goroutines in our application.
The version 1.13 of Go will improve the access of the shared items and will also bring a new cache that should solve the issue related to the garbage collector and clearing of the pools.
New lock-free pool and victim cache
Go version 1.13 brings a new doubly-linked list as a shared pool that removes the lock and improves the shared access. This is the foundation in order to improve the cache. Here is the new workflow of the shared access:

With this new chained pool, each processor with push and pop at the head of its queue while the shared access will pop from the tail. The head of the queue can grow by allocating a new struct twice as big that will be linked to the previous one thanks to the next/prev attributes. The default size for the initial struct is 8 items. That means that the second struct will contains 16 items, the third 32, and so on.
Also, the lock is now not needed and the code can rely on the atomic operations.
Regarding the new cache, the new strategy is quite simple. There are now 2 set of pools: the actives ones and the archived ones. When the garbage collector runs, it will keep a reference of each pool to an new attribute inside that pool, and will then copy the set of pools to archived ones before cleaning the current pools:
// Drop victim caches from all pools.
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// The pools with non-empty primary caches now have non-empty
// victim caches and no pools have primary caches.
oldPools, allPools = allPools, nilWith this strategy, the app will now have one more cycle of garbage collector to create/collect new items with a backup thanks the victim cache. In the workflow, the victim cache will be requested at the end of the process, after the shared pools.



